SuperCorrect: Advancing Small LLM Reasoning with Thought Template Distillation and Self-Correction
作者: Ling Yang, Zhaochen Yu, Tianjun Zhang, Minkai Xu, Joseph E. Gonzalez, Bin Cui, Shuicheng Yan
分类: cs.CL
发布日期: 2024-10-11 (更新: 2025-02-26)
备注: ICLR 2025. Project: https://github.com/YangLing0818/SuperCorrect-llm
🔗 代码/项目: GITHUB
💡 一句话要点
SuperCorrect:通过思想模板蒸馏和自校正提升小LLM的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小规模LLM 推理能力 思想模板蒸馏 自校正 跨模型DPO
📋 核心要点
- 小规模LLM在复杂数学推理中表现不佳,主要原因是缺乏有效的错误识别和纠正机制。
- SuperCorrect利用大型教师模型监督和纠正学生模型的推理和反思过程,提升小模型的推理能力。
- 实验表明,SuperCorrect-7B在MATH/GSM8K上显著超越DeepSeekMath-7B和Qwen2.5-Math-7B,达到7B模型的新SOTA。
📝 摘要(中文)
大型语言模型(LLMs)如GPT-4、DeepSeek-R1和ReasonFlux在各种推理任务中表现出显著的改进。然而,较小的LLMs在复杂的数学推理方面仍然存在困难,因为它们无法有效地识别和纠正推理错误。最近基于反思的方法旨在通过启用自我反思和自我纠正来解决这些问题,但它们在独立检测推理步骤中的错误方面仍然面临挑战。为了克服这些限制,我们提出了一种新颖的两阶段框架SuperCorrect,该框架使用大型教师模型来监督和纠正较小规模学生模型的推理和反思过程。在第一阶段,我们从教师模型中提取分层的高级和详细的思想模板,以指导学生模型引出更细粒度的推理思想。在第二阶段,我们引入跨模型协同直接偏好优化(DPO),通过在训练期间遵循教师的纠正轨迹来增强学生模型的自我纠正能力。这种跨模型DPO方法教会学生模型有效地定位和解决错误的思想,并从教师模型的错误驱动的见解中学习,打破其思想的瓶颈,并获得新的技能和知识来解决具有挑战性的问题。大量的实验一致地证明了我们方法的优越性。值得注意的是,我们的SuperCorrect-7B模型在MATH/GSM8K基准测试中显著超越了强大的DeepSeekMath-7B(7.8%/5.3%)和Qwen2.5-Math-7B(15.1%/6.3%),在所有7B模型中实现了新的SOTA性能。
🔬 方法详解
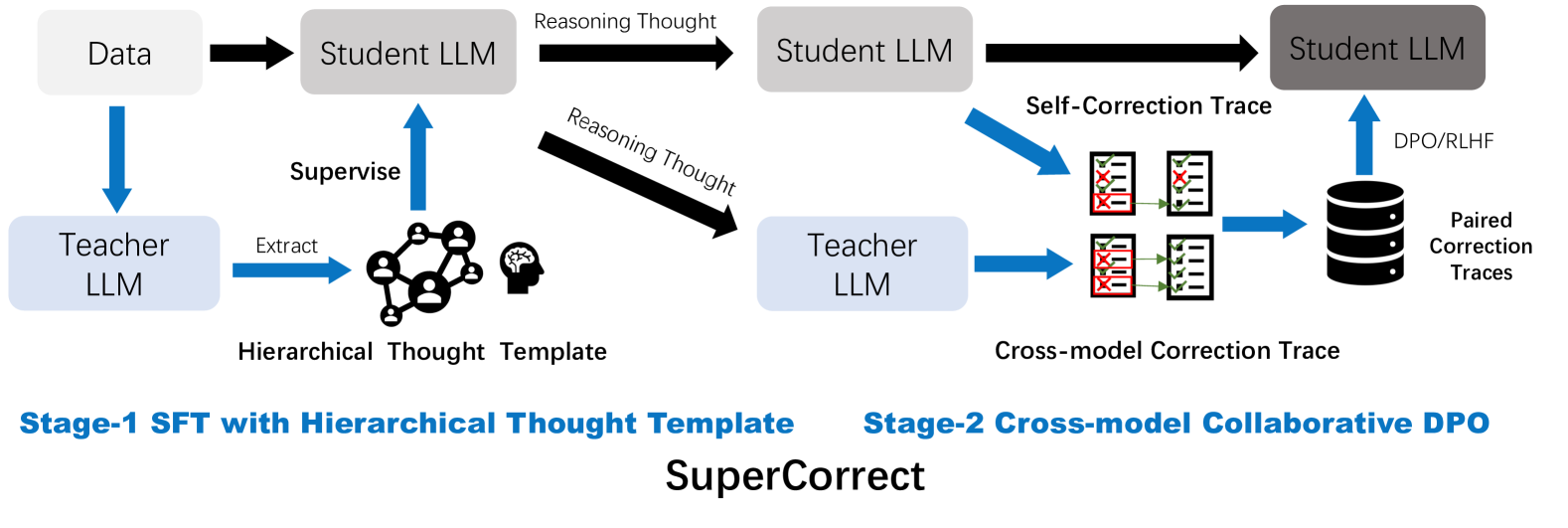
问题定义:论文旨在解决小规模语言模型(LLM)在复杂数学推理任务中表现不佳的问题。现有方法,特别是基于反思的方法,虽然尝试通过自我反思和自我纠正来改进推理,但仍然难以独立检测推理步骤中的错误,导致推理能力受限。
核心思路:论文的核心思路是利用大型、更强大的教师模型来指导和监督小规模学生模型的推理和反思过程。通过从教师模型中提取知识和纠错经验,并将其迁移到学生模型,从而提升学生模型的推理能力和自我纠正能力。
技术框架:SuperCorrect框架包含两个主要阶段:1) 思想模板蒸馏:从教师模型中提取分层的高级和详细的思想模板,用于指导学生模型生成更细粒度的推理过程。2) 跨模型协同直接偏好优化(DPO):利用教师模型的纠错轨迹,通过DPO训练学生模型,使其能够有效地定位和解决推理过程中的错误。
关键创新:论文的关键创新在于跨模型协同直接偏好优化(DPO),它允许学生模型从教师模型的纠错经验中学习,从而打破自身推理能力的瓶颈。与传统的知识蒸馏方法不同,SuperCorrect不仅传递知识,还传递纠错能力,使学生模型能够更好地应对复杂问题。
关键设计:在思想模板蒸馏阶段,论文设计了分层模板提取方法,以捕捉教师模型推理过程中的不同抽象层次的信息。在跨模型DPO阶段,论文使用教师模型的纠错轨迹作为偏好数据,训练学生模型,使其能够区分正确和错误的推理步骤,并学习如何进行有效的自我纠正。具体的损失函数设计和参数设置细节在论文中有详细描述,但摘要中未明确提及。
🖼️ 关键图片


📊 实验亮点
SuperCorrect-7B模型在MATH和GSM8K基准测试中分别取得了显著的性能提升。在MATH数据集上,SuperCorrect-7B超越了DeepSeekMath-7B 7.8%,超越了Qwen2.5-Math-7B 15.1%。在GSM8K数据集上,SuperCorrect-7B超越了DeepSeekMath-7B 5.3%,超越了Qwen2.5-Math-7B 6.3%。这些结果表明,SuperCorrect方法能够有效地提升小规模LLM的推理能力,并在7B模型中实现了新的SOTA性能。
🎯 应用场景
SuperCorrect方法可应用于提升各种小规模语言模型在复杂推理任务中的性能,例如数学问题求解、代码生成和逻辑推理。该方法有助于降低模型部署成本,并使小规模模型能够在资源受限的环境中执行复杂的任务。未来,该方法可以扩展到其他领域,例如自然语言理解和对话系统。
📄 摘要(原文)
Large language models (LLMs) like GPT-4, DeepSeek-R1, and ReasonFlux have shown significant improvements in various reasoning tasks. However, smaller LLMs still struggle with complex mathematical reasoning because they fail to effectively identify and correct reasoning errors. Recent reflection-based methods aim to address these issues by enabling self-reflection and self-correction, but they still face challenges in independently detecting errors in their reasoning steps. To overcome these limitations, we propose SuperCorrect, a novel two-stage framework that uses a large teacher model to supervise and correct both the reasoning and reflection processes of a smaller student model. In the first stage, we extract hierarchical high-level and detailed thought templates from the teacher model to guide the student model in eliciting more fine-grained reasoning thoughts. In the second stage, we introduce cross-model collaborative direct preference optimization (DPO) to enhance the self-correction abilities of the student model by following the teacher's correction traces during training. This cross-model DPO approach teaches the student model to effectively locate and resolve erroneous thoughts with error-driven insights from the teacher model, breaking the bottleneck of its thoughts and acquiring new skills and knowledge to tackle challenging problems. Extensive experiments consistently demonstrate our superiority over previous methods. Notably, our SuperCorrect-7B model significantly surpasses powerful DeepSeekMath-7B by 7.8%/5.3% and Qwen2.5-Math-7B by 15.1%/6.3% on MATH/GSM8K benchmarks, achieving new SOTA performance among all 7B models. Code: https://github.com/YangLing0818/SuperCorrect-llm