A social context-aware graph-based multimodal attentive learning framework for disaster content classification during emergencies: a benchmark dataset and method
作者: Shahid Shafi Dar, Mohammad Zia Ur Rehman, Karan Bais, Mohammed Abdul Haseeb, Nagendra Kumara
分类: cs.CY, cs.CL
发布日期: 2024-10-11 (更新: 2025-10-18)
期刊: journal={Expert Systems with Applications},pages={125337},year={2024},publisher={Elsevier}
DOI: 10.1016/j.eswa.2024.125337
💡 一句话要点
提出CrisisSpot框架,利用社交上下文感知图神经网络进行紧急事件中灾害内容分类。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灾害内容分类 社交媒体分析 图神经网络 多模态融合 注意力机制
📋 核心要点
- 现有灾害内容分类方法忽略了用户可信度、情感和社会互动等重要社交上下文信息。
- CrisisSpot利用图神经网络建模文本、视觉模态和社会上下文的复杂关系,并引入IDEA注意力机制。
- 实验表明,CrisisSpot在CrisisMMD和TSEqD数据集上显著优于现有方法,F1分数分别提升9.45%和5.01%。
📝 摘要(中文)
在危机时期,快速准确地分类社交媒体平台上分享的灾害相关信息对于有效的灾害响应和公共安全至关重要。在这些关键事件中,人们使用社交媒体进行交流,分享多模态的文本和视觉内容。然而,由于大量未经筛选和多样化的数据涌入,人道主义组织在有效利用这些信息方面面临挑战。现有的灾害相关内容分类方法通常未能对用户的可信度、情感背景和社会互动信息进行建模,而这些信息对于准确分类至关重要。为了解决这一差距,我们提出了一种名为CrisisSpot的方法,该方法利用基于图的神经网络来捕获文本和视觉模态之间复杂的联系,并利用社交上下文特征来整合以用户为中心和以内容为中心的信息。我们还引入了反向双重嵌入注意力(IDEA),它捕获数据中和谐和对比的模式,以增强多模态交互并提供更丰富的见解。此外,我们还提出了TSEqD(土耳其-叙利亚地震数据集),这是一个针对单一灾害事件的大型带注释数据集,包含10,352个样本。通过广泛的实验,CrisisSpot表现出显著的改进,与公开可用的CrisisMMD数据集和TSEqD数据集上的最先进方法相比,平均F1分数分别提高了9.45%和5.01%。
🔬 方法详解
问题定义:论文旨在解决紧急事件中社交媒体灾害内容分类问题。现有方法的痛点在于未能充分利用社交上下文信息,如用户可信度、情感和社会互动,导致分类精度不高。海量未过滤的多模态数据也给有效信息提取带来挑战。
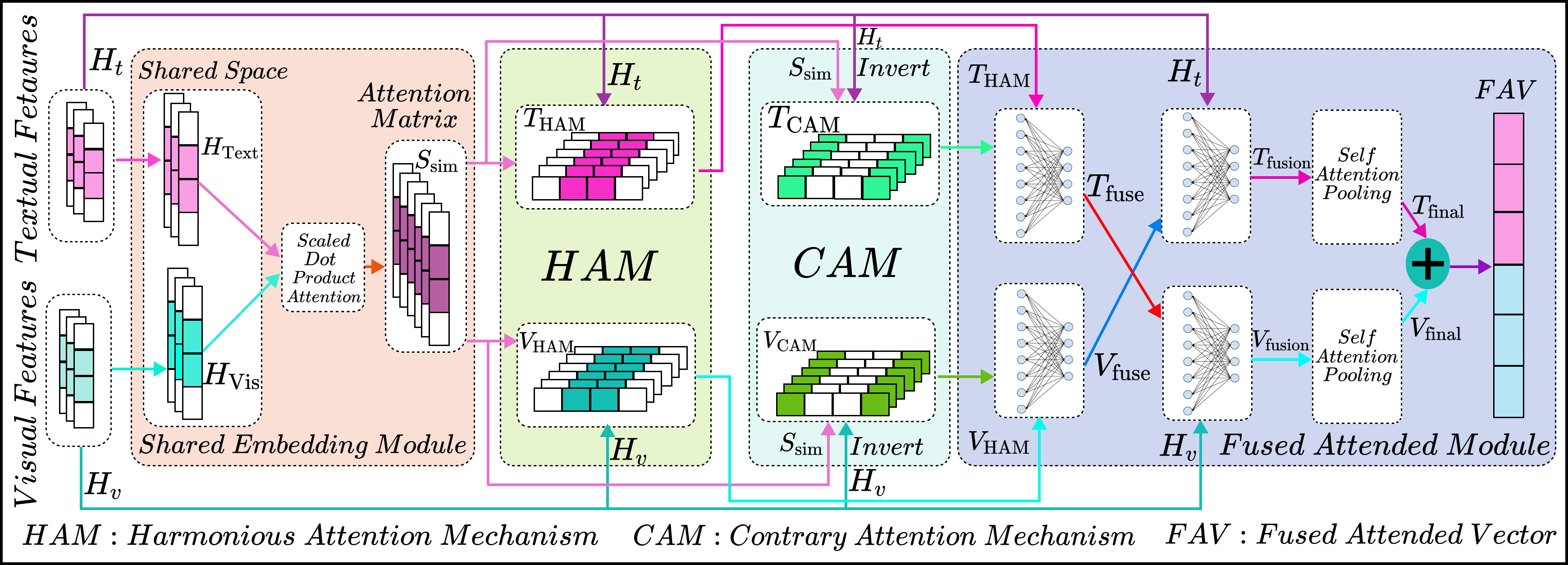
核心思路:论文的核心思路是利用图神经网络(GNN)建模文本、视觉内容以及社交上下文之间的复杂关系。通过GNN,可以将用户、帖子、情感等信息表示为图节点,并通过边连接相关节点,从而学习到更丰富的特征表示。同时,引入反向双重嵌入注意力(IDEA)机制,增强多模态特征的交互和融合。
技术框架:CrisisSpot框架主要包含以下几个模块:1) 文本特征提取模块:使用预训练语言模型(如BERT)提取文本特征。2) 视觉特征提取模块:使用卷积神经网络(CNN)提取图像特征。3) 社交上下文特征提取模块:提取用户可信度、情感等特征。4) 图神经网络模块:构建社交上下文感知的图结构,利用GNN学习节点表示。5) 多模态融合模块:使用IDEA注意力机制融合文本、视觉和社交上下文特征。6) 分类器:使用全连接层进行灾害内容分类。
关键创新:论文的关键创新在于:1) 提出了社交上下文感知的图神经网络,能够有效建模用户、帖子等实体之间的关系。2) 引入了反向双重嵌入注意力(IDEA)机制,能够捕获多模态数据中和谐和对比的模式,增强特征交互。3) 构建了大规模的土耳其-叙利亚地震数据集(TSEqD),为灾害内容分类研究提供了新的benchmark。
关键设计:图神经网络采用Graph Attention Network (GAT),允许节点根据邻居节点的重要性进行加权聚合。IDEA注意力机制通过计算文本和视觉特征之间的相似度和差异度,自适应地调整不同模态的权重。损失函数采用交叉熵损失,优化模型参数。
🖼️ 关键图片

📊 实验亮点
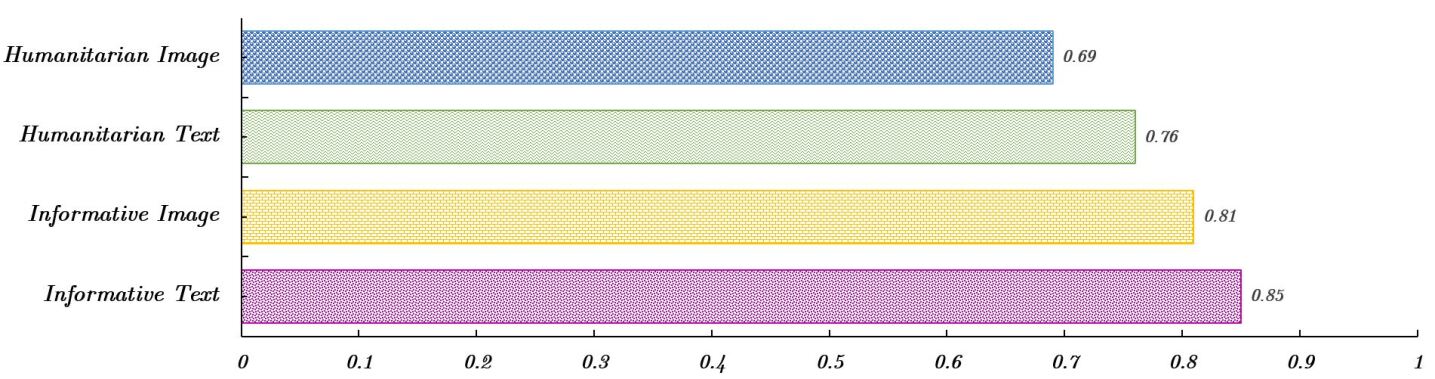
CrisisSpot在CrisisMMD和TSEqD数据集上进行了评估,实验结果表明,CrisisSpot显著优于现有方法。在CrisisMMD数据集上,CrisisSpot的平均F1分数提升了9.45%;在TSEqD数据集上,平均F1分数提升了5.01%。这些结果表明,CrisisSpot能够有效利用社交上下文信息,提高灾害内容分类的准确性。
🎯 应用场景
该研究成果可应用于灾害应急响应、舆情监控、虚假信息检测等领域。通过快速准确地识别社交媒体上的灾害相关信息,可以帮助救援组织更有效地分配资源,提高救援效率,减少人员伤亡。同时,该方法也可用于识别和过滤虚假信息,维护社会稳定。
📄 摘要(原文)
In times of crisis, the prompt and precise classification of disaster-related information shared on social media platforms is crucial for effective disaster response and public safety. During such critical events, individuals use social media to communicate, sharing multimodal textual and visual content. However, due to the significant influx of unfiltered and diverse data, humanitarian organizations face challenges in leveraging this information efficiently. Existing methods for classifying disaster-related content often fail to model users' credibility, emotional context, and social interaction information, which are essential for accurate classification. To address this gap, we propose CrisisSpot, a method that utilizes a Graph-based Neural Network to capture complex relationships between textual and visual modalities, as well as Social Context Features to incorporate user-centric and content-centric information. We also introduce Inverted Dual Embedded Attention (IDEA), which captures both harmonious and contrasting patterns within the data to enhance multimodal interactions and provide richer insights. Additionally, we present TSEqD (Turkey-Syria Earthquake Dataset), a large annotated dataset for a single disaster event, containing 10,352 samples. Through extensive experiments, CrisisSpot demonstrated significant improvements, achieving an average F1-score gain of 9.45% and 5.01% compared to state-of-the-art methods on the publicly available CrisisMMD dataset and the TSEqD dataset, respectively.