Data Processing for the OpenGPT-X Model Family
作者: Nicolo' Brandizzi, Hammam Abdelwahab, Anirban Bhowmick, Lennard Helmer, Benny Jörg Stein, Pavel Denisov, Qasid Saleem, Michael Fromm, Mehdi Ali, Richard Rutmann, Farzad Naderi, Mohamad Saif Agy, Alexander Schwirjow, Fabian Küch, Luzian Hahn, Malte Ostendorff, Pedro Ortiz Suarez, Georg Rehm, Dennis Wegener, Nicolas Flores-Herr, Joachim Köhler, Johannes Leveling
分类: cs.CL
发布日期: 2024-10-11 (更新: 2025-08-07)
💡 一句话要点
OpenGPT-X项目:构建大规模多语种LLM的数据处理流程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多语种处理 数据清洗 数据去重 数据过滤 OpenGPT-X 欧洲语言
📋 核心要点
- 现有大型语言模型在多语种支持和数据合规性方面存在挑战,尤其是在欧洲语言和法规方面。
- OpenGPT-X项目通过构建专门的数据处理流程,区分精选数据和网络数据,针对性地进行过滤和去重。
- 该研究深入分析了数据集,提高了透明度,并为未来多语种LLM的数据准备提供了宝贵的经验和建议。
📝 摘要(中文)
本文全面概述了为OpenGPT-X项目开发的数据准备流程,该项目旨在创建开放且高性能的多语种大型语言模型(LLM)。项目目标是提供覆盖所有主要欧洲语言的模型,特别关注欧盟内的实际应用。我们解释了所有数据处理步骤,从数据选择和需求定义到最终过滤数据的准备。我们区分了精选数据和网络数据,因为这两类数据由不同的流程处理,精选数据经过最少的过滤,而网络数据需要广泛的过滤和去重。这种区分指导了针对两种流程的专用算法解决方案的开发。除了描述处理方法外,我们还对数据集进行了深入分析,提高了透明度并与欧洲数据法规保持一致。最后,我们分享了项目期间面临的关键见解和挑战,为未来大规模多语种LLM数据准备工作提供了建议。
🔬 方法详解
问题定义:论文旨在解决构建大规模多语种LLM时,如何高效、合规地准备训练数据的问题。现有方法在处理不同来源、不同质量的数据时,缺乏针对性,且难以满足欧洲数据法规的要求。尤其是在网络数据中,噪声数据和重复数据会严重影响模型的性能。
核心思路:论文的核心思路是将数据分为精选数据和网络数据两类,并针对每类数据设计不同的处理流程。精选数据质量较高,只需少量过滤;而网络数据质量参差不齐,需要进行更严格的过滤和去重。通过这种方式,可以最大限度地利用高质量数据,同时减少噪声数据对模型的影响。
技术框架:整体流程包括以下几个主要阶段:1) 数据选择和需求定义;2) 数据获取;3) 数据清洗和过滤(包括精选数据和网络数据两个独立流程);4) 数据去重;5) 数据格式化和准备。其中,数据清洗和过滤是核心环节,针对精选数据采用最小化过滤策略,针对网络数据采用包括基于规则的过滤、基于模型的过滤等多种方法。
关键创新:论文的关键创新在于针对多语种LLM的数据准备,提出了区分精选数据和网络数据的处理策略,并针对网络数据设计了高效的过滤和去重算法。这种策略能够更好地平衡数据质量和数据规模,提高模型的性能和泛化能力。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,强调了在数据过滤过程中,需要根据不同的语言和领域特点,设计不同的过滤规则和模型。此外,在数据去重方面,采用了多种去重算法,包括基于文本相似度的去重和基于语义相似度的去重。
🖼️ 关键图片


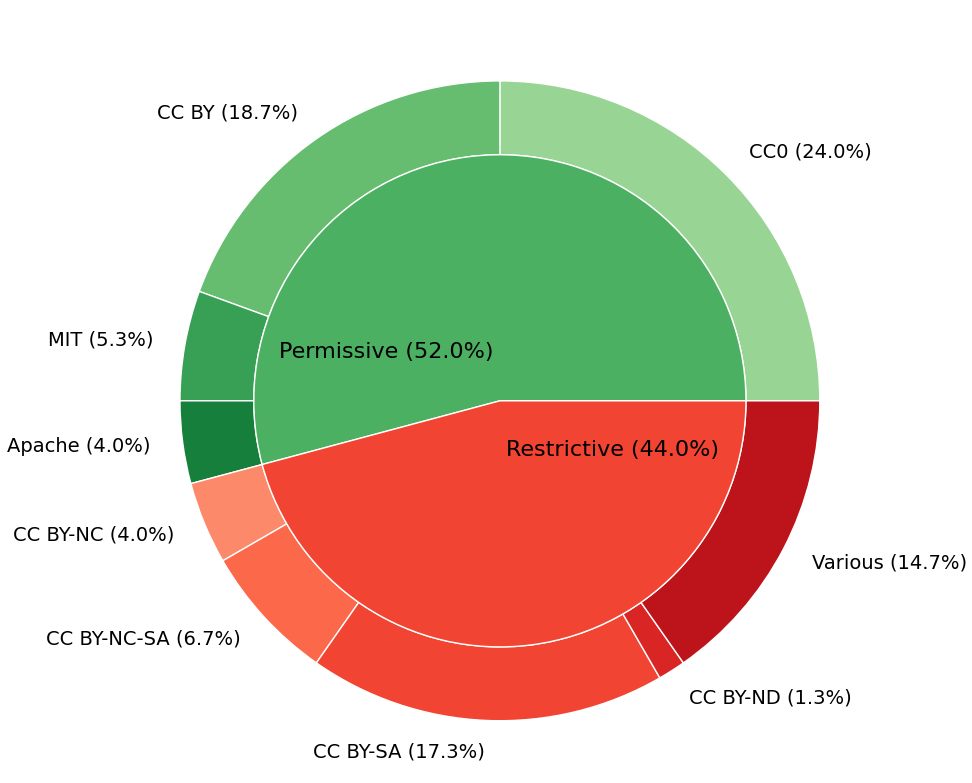
📊 实验亮点
论文详细描述了OpenGPT-X项目的数据处理流程,并对数据集进行了深入分析,提高了透明度。虽然没有提供具体的性能数据,但强调了数据质量对模型性能的重要性,并为未来多语种LLM的数据准备提供了宝贵的经验和建议。该项目旨在构建覆盖所有主要欧洲语言的模型,具有重要的实际意义。
🎯 应用场景
该研究成果可应用于构建各种多语种大型语言模型,特别是在需要遵守欧洲数据法规的场景下。例如,可以用于开发面向欧洲市场的智能客服、机器翻译、文本摘要等应用。此外,该研究提出的数据处理流程和方法,也可以为其他语言和领域的大型语言模型的数据准备提供参考。
📄 摘要(原文)
This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final filtered data. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.