StraGo: Harnessing Strategic Guidance for Prompt Optimization
作者: Yurong Wu, Yan Gao, Bin Benjamin Zhu, Zineng Zhou, Xiaodi Sun, Sheng Yang, Jian-Guang Lou, Zhiming Ding, Linjun Yang
分类: cs.CL
发布日期: 2024-10-11
备注: 19 pages, 3 figures, 20 tables
💡 一句话要点
StraGo:利用策略指导优化提示,解决提示漂移问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示工程 提示优化 大型语言模型 上下文学习 策略引导
📋 核心要点
- 现有提示优化方法存在提示漂移问题,即优化后的提示可能损害先前成功的案例。
- StraGo通过分析成功和失败案例,提取关键因素,并制定策略指导提示优化,从而缓解漂移。
- 实验表明,StraGo在推理、自然语言理解等任务上表现出色,达到了新的state-of-the-art。
📝 摘要(中文)
提示工程对于发挥大型语言模型(LLMs)在各种应用中的能力至关重要。现有的提示优化方法虽然提高了提示的有效性,但往往会导致提示漂移,即新生成的提示在解决失败案例的同时,会对先前成功的案例产生不利影响。此外,这些方法倾向于过度依赖LLM的内在能力来进行提示优化任务。本文介绍了一种名为StraGo(策略引导优化)的新方法,旨在通过利用成功和失败案例中的见解来识别实现优化目标的关键因素,从而减轻提示漂移。StraGo采用了一种“如何做”的方法,整合了上下文学习,以制定具体的、可操作的策略,为提示优化提供详细的、逐步的指导。在包括推理、自然语言理解、领域特定知识和工业应用等一系列任务中进行的大量实验证明了StraGo的卓越性能。它在提示优化方面建立了一个新的最先进水平,展示了其提供稳定和有效的提示改进的能力。
🔬 方法详解
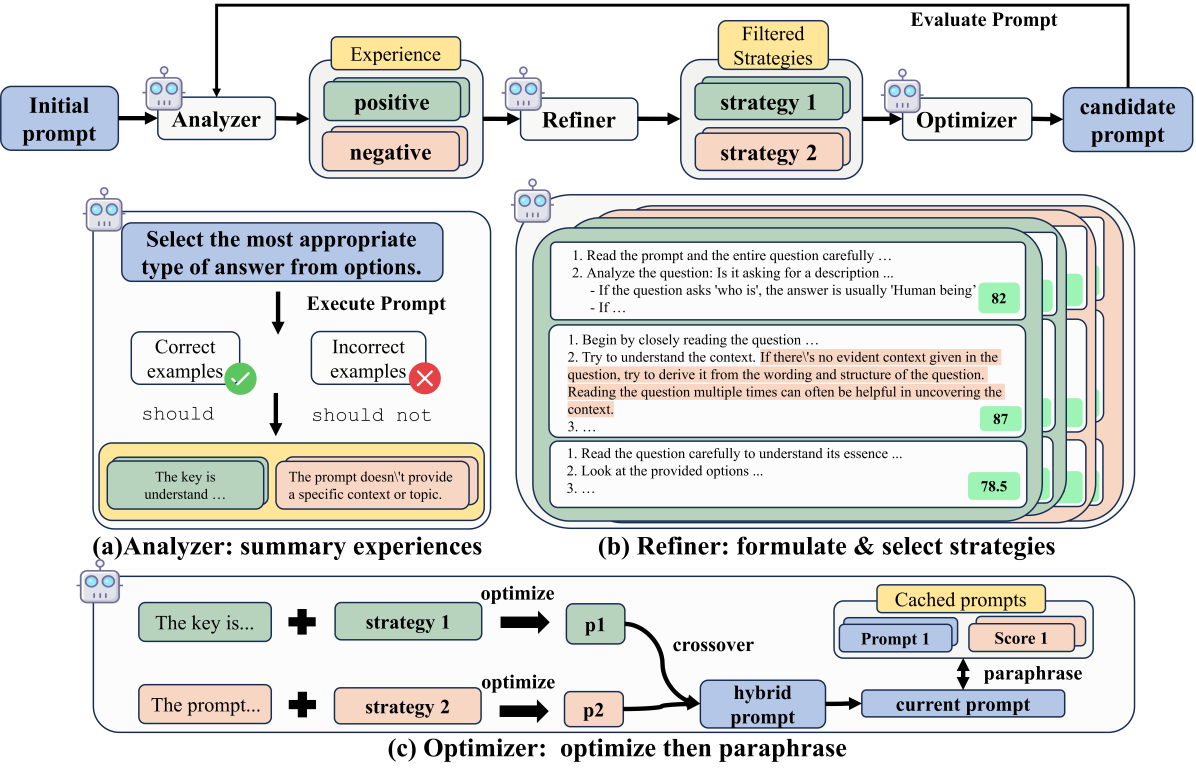
问题定义:现有提示优化方法在提升模型性能的同时,容易出现“提示漂移”现象,即为了解决某些失败案例而优化的提示,反而降低了模型在之前成功案例上的表现。此外,现有方法过度依赖LLM自身的能力进行优化,缺乏明确的指导策略。
核心思路:StraGo的核心思路是利用成功和失败案例的经验,从中提取关键因素,并将其转化为具体的、可操作的策略,指导提示的优化过程。通过这种“如何做”的方法,StraGo旨在稳定地提升提示的有效性,并减轻提示漂移。
技术框架:StraGo的整体流程包括以下几个主要阶段:1) 分析成功和失败的案例,识别影响性能的关键因素;2) 基于这些因素,利用上下文学习(In-Context Learning)制定详细的、逐步的优化策略;3) 将这些策略应用于提示的优化过程,生成新的提示;4) 评估新提示的性能,并重复上述过程进行迭代优化。
关键创新:StraGo最重要的创新在于其策略引导的优化方法。与以往依赖LLM自身能力进行优化的方法不同,StraGo通过显式地提取和应用优化策略,实现了更稳定和可控的提示优化过程。这种方法能够更好地平衡不同案例之间的性能,从而减轻提示漂移。
关键设计:StraGo的关键设计在于如何有效地提取和表示优化策略。论文采用In-Context Learning的方式,通过提供成功和失败案例的示例,引导LLM生成具体的优化策略。这些策略通常包含一系列步骤,指导用户如何修改提示以提高性能。具体的参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,StraGo在包括推理、自然语言理解、领域特定知识和工业应用等一系列任务中,均取得了显著的性能提升,并达到了新的state-of-the-art。具体的数据和对比基线在论文中进行了详细的展示,证明了StraGo在提示优化方面的优越性。
🎯 应用场景
StraGo具有广泛的应用前景,可以应用于各种需要提示工程的领域,例如自然语言处理、知识图谱问答、代码生成等。通过StraGo,可以更有效地优化提示,提高LLM在各种任务上的性能,并降低提示工程的成本。此外,StraGo的策略引导方法也可以应用于其他机器学习模型的优化,具有一定的通用性。
📄 摘要(原文)
Prompt engineering is pivotal for harnessing the capabilities of large language models (LLMs) across diverse applications. While existing prompt optimization methods improve prompt effectiveness, they often lead to prompt drifting, where newly generated prompts can adversely impact previously successful cases while addressing failures. Furthermore, these methods tend to rely heavily on LLMs' intrinsic capabilities for prompt optimization tasks. In this paper, we introduce StraGo (Strategic-Guided Optimization), a novel approach designed to mitigate prompt drifting by leveraging insights from both successful and failed cases to identify critical factors for achieving optimization objectives. StraGo employs a how-to-do methodology, integrating in-context learning to formulate specific, actionable strategies that provide detailed, step-by-step guidance for prompt optimization. Extensive experiments conducted across a range of tasks, including reasoning, natural language understanding, domain-specific knowledge, and industrial applications, demonstrate StraGo's superior performance. It establishes a new state-of-the-art in prompt optimization, showcasing its ability to deliver stable and effective prompt improvements.