TPO: Aligning Large Language Models with Multi-branch & Multi-step Preference Trees
作者: Weibin Liao, Xu Chu, Yasha Wang
分类: cs.CL, cs.AI
发布日期: 2024-10-10 (更新: 2025-10-24)
备注: Accepted by ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
TPO:通过多分支多步偏好树对齐大型语言模型,提升复杂推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏好学习 直接偏好优化 思维树 数学推理
📋 核心要点
- 现有基于DPO的方法在处理复杂推理任务时,无法充分利用偏好树中蕴含的细粒度偏好信息,导致学习不完整。
- TPO通过将语言模型对齐问题转化为偏好列表排序,直接从整个偏好树学习,从而更有效地利用偏好信息。
- TPO引入自适应步骤奖励,调整推理过程中每一步的奖励值,帮助模型识别关键步骤,并增大偏好差距。
📝 摘要(中文)
在数学推理等复杂推理任务中,直接偏好优化(DPO)已被用于抑制不期望的响应输出,从而增强大型语言模型(LLM)的长链推理能力。现有研究利用LLM通过思维树(ToT)生成偏好树,并从中采样DPO算法所需的成对偏好响应。然而,基于二元偏好优化的DPO算法无法学习偏好树提供的具有不同偏好/不偏好程度的多个响应,导致偏好学习不完整。本文提出树偏好优化(TPO),它不从偏好树中采样成对偏好响应,而是在微调期间直接从整个偏好树中学习。具体来说,TPO将语言模型对齐形式化为偏好列表排序问题,策略可以更有效地从给定提示的响应排序偏好列表中学习。此外,为了进一步帮助LLM识别长链推理中的判别步骤,并增加偏好列表中的相对奖励幅度,TPO利用自适应步骤奖励来调整轨迹中每个步骤的奖励值,以进行细粒度的偏好优化。在数学推理任务上进行了大量实验来评估TPO。实验结果表明,在四个数据集上的五个公共大型语言模型上,TPO始终优于DPO。代码已公开。
🔬 方法详解
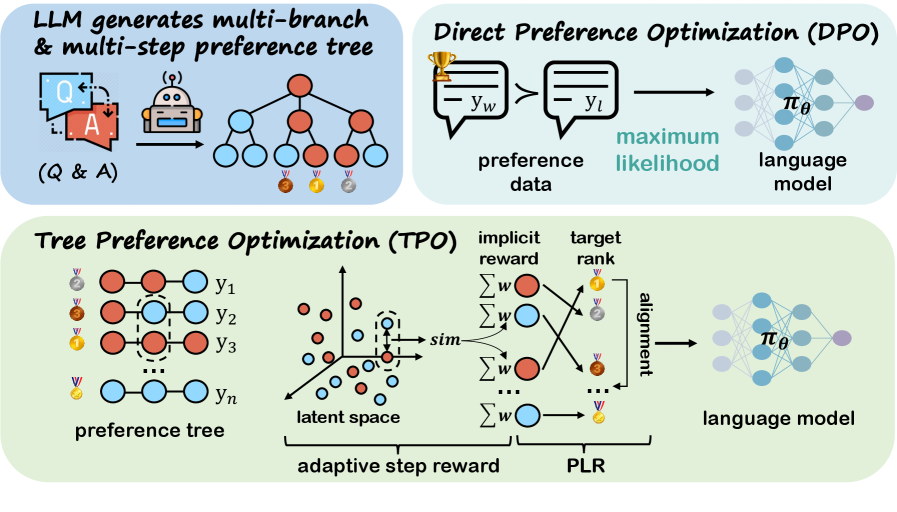
问题定义:论文旨在解决大型语言模型在复杂推理任务中,利用偏好学习进行对齐时,现有方法无法充分利用偏好树提供的细粒度偏好信息的问题。现有基于DPO的方法通常从偏好树中采样成对的偏好响应,忽略了树结构中蕴含的更丰富的偏好关系,导致偏好学习不完整,影响模型的推理能力。
核心思路:论文的核心思路是将语言模型对齐问题形式化为一个偏好列表排序问题。不再像DPO那样采样成对的偏好响应,而是直接利用整个偏好树进行学习。通过对偏好树中的所有响应进行排序,模型可以学习到更细粒度的偏好关系,从而更有效地进行对齐。
技术框架:TPO的整体框架包括以下几个主要步骤:1) 使用LLM和Tree-of-Thoughts (ToT) 生成偏好树,其中每个节点代表推理过程中的一个步骤,每个分支代表不同的推理路径。2) 对偏好树中的所有响应进行排序,生成一个偏好列表。3) 使用偏好列表作为训练数据,对LLM进行微调,目标是使模型能够根据给定的提示,生成与偏好列表排序一致的响应。4) 使用自适应步骤奖励机制,调整推理过程中每一步的奖励值,以帮助模型识别关键步骤。
关键创新:TPO的关键创新在于:1) 将语言模型对齐问题转化为偏好列表排序问题,从而能够更充分地利用偏好树中蕴含的细粒度偏好信息。2) 引入自适应步骤奖励机制,动态调整推理过程中每一步的奖励值,以帮助模型识别关键步骤,并增大偏好差距。这与传统的DPO方法只关注最终结果的偏好不同,TPO更关注推理过程中的每一步的质量。
关键设计:TPO的关键设计包括:1) 偏好列表的生成方式:论文采用某种排序算法(具体未知)对偏好树中的所有响应进行排序,生成偏好列表。2) 自适应步骤奖励的计算方式:论文设计了一种自适应步骤奖励机制,根据每个步骤的质量动态调整奖励值。具体计算公式未知,但目标是使关键步骤获得更高的奖励,从而引导模型关注这些步骤。3) 损失函数:TPO使用一种基于偏好列表排序的损失函数(具体形式未知),目标是使模型生成的响应与偏好列表的排序一致。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TPO在四个数学推理数据集上的五个大型语言模型上均优于DPO。具体性能提升数据未知,但论文强调TPO在多个数据集和模型上的一致性优越性,表明TPO具有较强的泛化能力和鲁棒性。这些结果验证了TPO在利用细粒度偏好信息方面的有效性。
🎯 应用场景
TPO方法具有广泛的应用前景,可以应用于各种需要复杂推理的任务中,例如数学问题求解、代码生成、知识图谱推理等。通过更有效地利用偏好信息,TPO可以提高LLM的推理能力和生成质量,使其能够更好地解决实际问题。未来,TPO还可以与其他技术相结合,例如强化学习、对比学习等,进一步提升LLM的性能。
📄 摘要(原文)
In the domain of complex reasoning tasks, such as mathematical reasoning, recent advancements have proposed the use of Direct Preference Optimization (DPO) to suppress output of dispreferred responses, thereby enhancing the long-chain reasoning capabilities of large language models (LLMs). To this end, these studies employed LLMs to generate preference trees via Tree-of-thoughts (ToT) and sample the paired preference responses required by the DPO algorithm. However, the DPO algorithm based on binary preference optimization is unable to learn multiple responses with varying degrees of preference/dispreference that provided by the preference trees, resulting in incomplete preference learning. In this work, we introduce Tree Preference Optimization (TPO), that does not sample paired preference responses from the preference tree; instead, it directly learns from the entire preference tree during the fine-tuning. Specifically, TPO formulates the language model alignment as a Preference List Ranking problem, where the policy can potentially learn more effectively from a ranked preference list of responses given the prompt. In addition, to further assist LLMs in identifying discriminative steps within long-chain reasoning and increase the relative reward margin in the preference list, TPO utilizes Adaptive Step Reward to adjust the reward values of each step in trajectory for performing fine-grained preference optimization. We carry out extensive experiments on mathematical reasoning tasks to evaluate TPO. The experimental results indicate that TPO consistently outperforms DPO across five public large language models on four datasets. Our code is publicly available at https://github.com/MrBlankness/TPO.git.