Understanding the Interplay between Parametric and Contextual Knowledge for Large Language Models
作者: Sitao Cheng, Liangming Pan, Xunjian Yin, Xinyi Wang, William Yang Wang
分类: cs.CL
发布日期: 2024-10-10
备注: 27 pages, 8 figures and 17 tables
🔗 代码/项目: GITHUB
💡 一句话要点
ECHOQA:探究大语言模型中参数知识与上下文知识的动态交互
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识融合 参数知识 上下文知识 ECHOQA 基准测试 知识推理
📋 核心要点
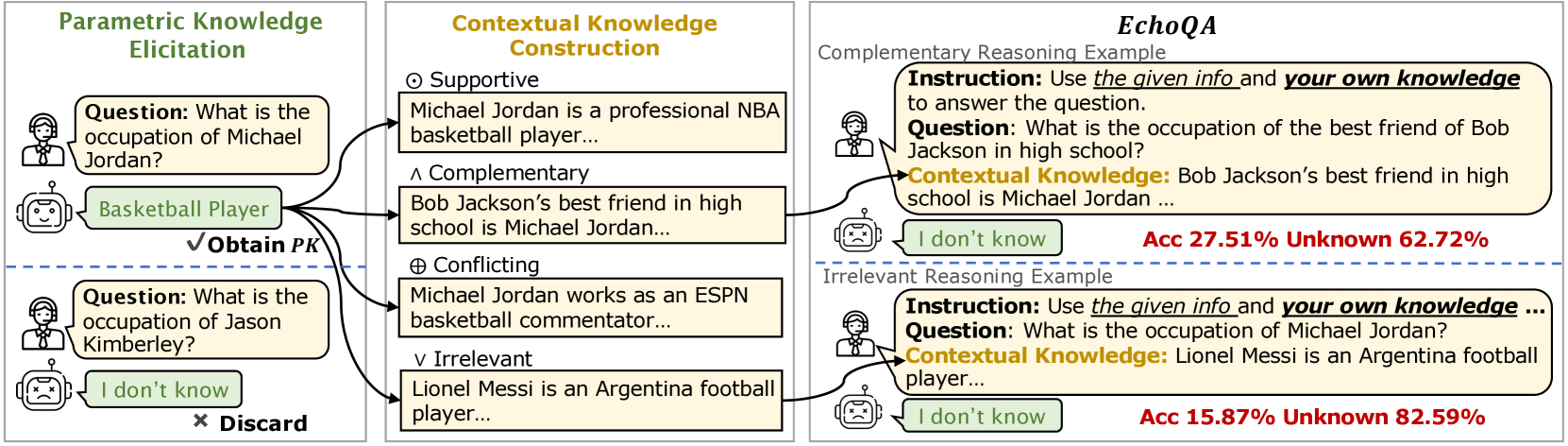
- 现有LLM难以有效整合内部参数知识(PK)与外部上下文知识(CK),尤其是在两者关系复杂时。
- 论文提出ECHOQA基准,用于评估LLM在不同PK/CK关系下的表现,并分析其交互模式。
- 实验表明,LLM倾向于过度依赖上下文知识,即使上下文知识是无关的或与参数知识互补。
📝 摘要(中文)
大型语言模型(LLM)在预训练过程中编码了大量的参数知识(PK),并且可以通过整合上下文知识(CK)来进一步增强。本文旨在研究LLM如何有效地整合其内部PK与外部CK以解决复杂问题。我们对PK和CK之间的动态交互进行研究,将其关系分为四种类型:支持型、互补型、冲突型和无关型。为了支持这项研究,我们提出了ECHOQA,一个涵盖科学、事实和常识知识的基准。结果表明,LLM倾向于抑制其PK,即使在上下文信息是互补或无关的情况下。虽然定制的指令可以鼓励LLM更多地依赖其PK,但它们仍然难以充分利用它。这些发现揭示了LLM的一个关键漏洞,引发了人们对其在知识密集型任务中的可靠性的担忧。
🔬 方法详解
问题定义:现有的大语言模型在处理需要结合自身知识和外部信息的任务时,存在无法有效融合两种知识的问题。具体来说,当外部上下文知识(CK)与模型内部参数知识(PK)存在冲突、互补或无关等关系时,模型如何权衡和利用这两种知识仍然是一个挑战。现有的方法往往无法充分利用模型自身的知识,或者容易受到错误上下文信息的影响。
核心思路:本文的核心思路是通过构建一个专门的基准数据集ECHOQA,来系统地研究LLM在不同PK和CK关系下的行为。通过分析模型在不同情况下的表现,揭示模型在知识融合方面的优势和不足。同时,探索不同的指令策略,以期引导模型更好地利用自身的知识。
技术框架:ECHOQA基准数据集包含科学、事实和常识三种类型的知识,每种知识都设计了支持型、互补型、冲突型和无关型四种PK/CK关系。研究人员使用不同的LLM(例如,GPT-3)在ECHOQA上进行实验,并分析模型的输出结果。此外,他们还尝试了不同的指令策略,例如,明确告知模型需要同时考虑内部知识和外部信息。
关键创新:该论文的关键创新在于提出了ECHOQA基准数据集,该数据集能够系统地评估LLM在不同PK/CK关系下的知识融合能力。此外,该研究还揭示了LLM在知识融合方面的一个重要缺陷,即过度依赖上下文知识,即使上下文知识是错误的或无关的。
关键设计:ECHOQA数据集的设计关键在于对PK/CK关系的细致划分。对于每种知识类型,都精心设计了四种不同关系的样本,以确保能够全面地评估LLM的知识融合能力。指令策略的设计也至关重要,研究人员尝试了多种不同的指令,以期找到能够有效引导模型利用自身知识的方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在面对上下文知识时,即使上下文知识是互补或无关的,也倾向于抑制其内部参数知识。通过调整指令,可以鼓励LLM更多地依赖其内部知识,但效果有限。该研究揭示了LLM在知识融合方面的一个关键漏洞,并为未来的研究方向提供了重要的启示。
🎯 应用场景
该研究成果可应用于提升LLM在知识密集型任务中的可靠性,例如问答系统、信息检索和科学研究。通过更好地理解和控制LLM的知识融合行为,可以开发出更值得信赖的AI系统,减少错误信息的传播,并提高AI在各个领域的应用价值。
📄 摘要(原文)
Large language models (LLMs) encode vast amounts of knowledge during pre-training (parametric knowledge, or PK) and can further be enhanced by incorporating contextual knowledge (CK). Can LLMs effectively integrate their internal PK with external CK to solve complex problems? In this paper, we investigate the dynamic interaction between PK and CK, categorizing their relationships into four types: Supportive, Complementary, Conflicting, and Irrelevant. To support this investigation, we introduce ECHOQA, a benchmark spanning scientific, factual, and commonsense knowledge. Our results show that LLMs tend to suppress their PK when contextual information is available, even when it is complementary or irrelevant. While tailored instructions can encourage LLMs to rely more on their PK, they still struggle to fully leverage it. These findings reveal a key vulnerability in LLMs, raising concerns about their reliability in knowledge-intensive tasks. Resources are available at https://github.com/sitaocheng/Knowledge_Interplay