Exploring Natural Language-Based Strategies for Efficient Number Learning in Children through Reinforcement Learning
作者: Tirthankar Mittra
分类: cs.CL, cs.AI, cs.LG, cs.MA
发布日期: 2024-10-10
💡 一句话要点
利用强化学习探索基于自然语言的儿童高效数字学习策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 数字学习 自然语言处理 儿童教育 深度学习
📋 核心要点
- 现有方法在模拟儿童数字学习过程中,对语言指令的作用建模不足,缺乏对不同语言结构影响的深入分析。
- 论文提出利用深度强化学习模型,模拟不同语言指令对智能体数字习得的影响,并预测最佳数字呈现序列。
- 实验结果表明,特定的语言结构能有效提升智能体的数字理解能力,并加速学习过程,为教育策略提供参考。
📝 摘要(中文)
本文探讨了儿童如何利用强化学习(RL)框架学习数字,重点关注语言指令的影响。使用强化学习的动机源于其与受控环境中的心理学学习理论的相似性。通过使用最先进的深度强化学习模型,我们模拟和分析了各种形式的语言指令对数字习得的影响。研究结果表明,某些语言结构能更有效地提高强化学习智能体的数字理解能力。此外,我们的模型预测了向强化学习智能体呈现数字的最佳序列,从而提高他们的学习速度。这项研究为语言和数字认知之间的相互作用提供了宝贵的见解,对教育策略和旨在支持幼儿学习的人工智能系统的开发具有重要意义。
🔬 方法详解
问题定义:论文旨在解决如何通过语言指令更有效地帮助儿童学习数字的问题。现有方法通常忽略了不同语言结构对学习效率的影响,缺乏对最佳教学序列的探索。因此,需要一种能够模拟语言指令影响并优化教学策略的方法。
核心思路:论文的核心思路是利用强化学习模拟儿童的学习过程,并将不同的语言指令作为智能体的输入,通过奖励机制引导智能体学习数字。通过比较不同语言指令下的学习效果,可以找到更有效的教学策略。同时,模型可以预测最佳的数字呈现序列,以加速学习过程。
技术框架:整体框架包括一个强化学习智能体和一个模拟环境。智能体接收来自环境的状态(例如,当前学习的数字),并根据语言指令选择一个动作(例如,猜测下一个数字)。环境根据智能体的动作给出奖励或惩罚,并更新状态。通过不断迭代,智能体学习到最佳的策略。主要模块包括:状态表示模块、动作选择模块、奖励函数模块和语言指令编码模块。
关键创新:论文的关键创新在于将自然语言处理技术与强化学习相结合,模拟了语言指令对数字学习的影响。通过分析不同语言结构的学习效果,为教育策略提供了新的视角。此外,模型能够预测最佳的数字呈现序列,这在传统的教学方法中难以实现。
关键设计:论文使用了深度强化学习模型,例如深度Q网络(DQN)或策略梯度方法。语言指令通过词嵌入技术进行编码,并作为智能体的输入。奖励函数的设计至关重要,需要根据学习目标进行调整。例如,可以设置奖励为:如果智能体猜对了下一个数字,则获得正奖励;如果猜错了,则获得负奖励。此外,还可以引入一些正则化项,以防止过拟合。
🖼️ 关键图片
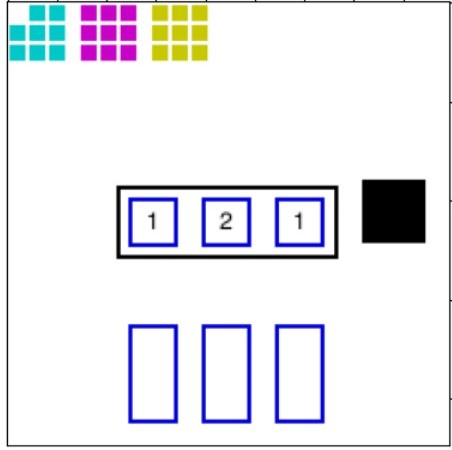
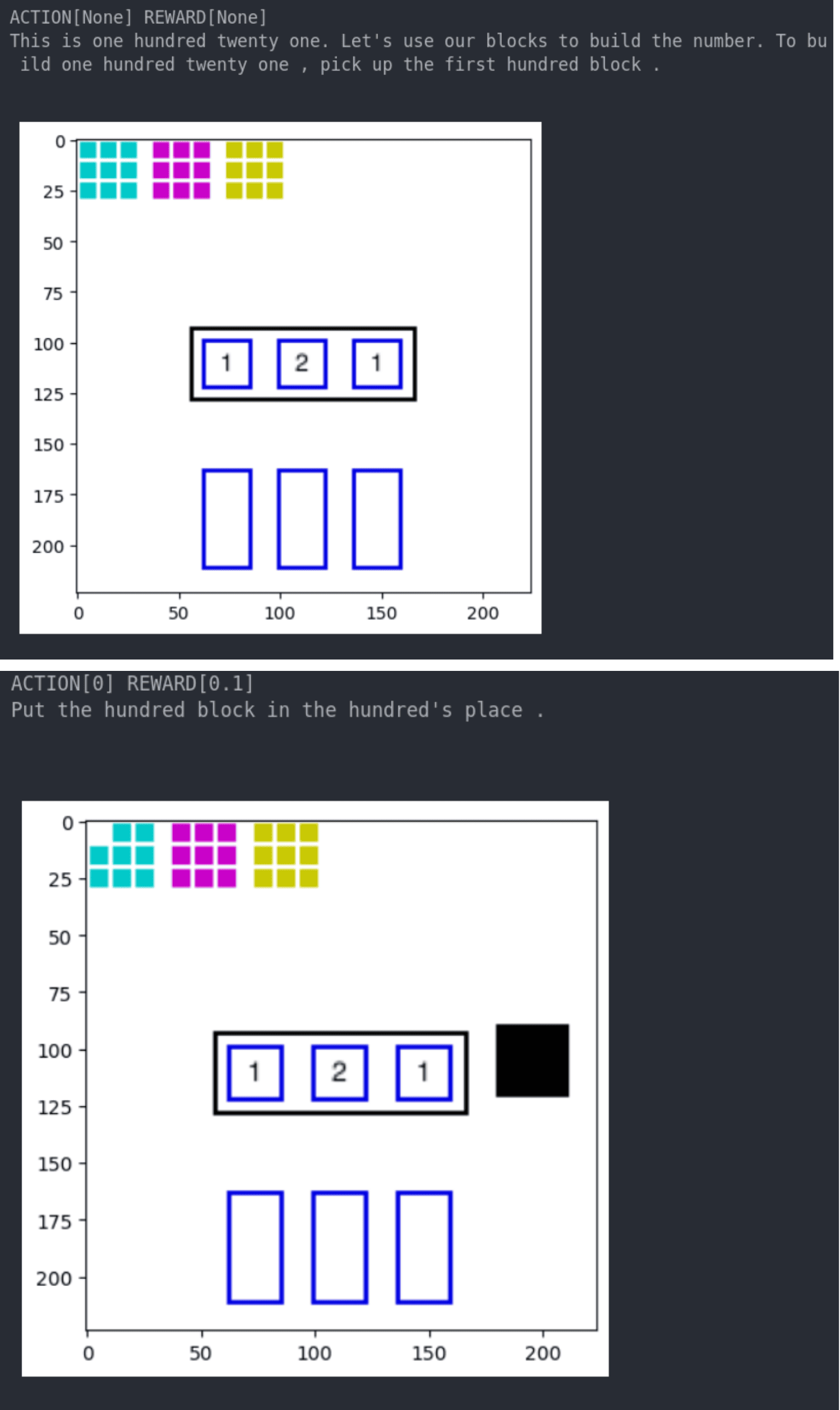
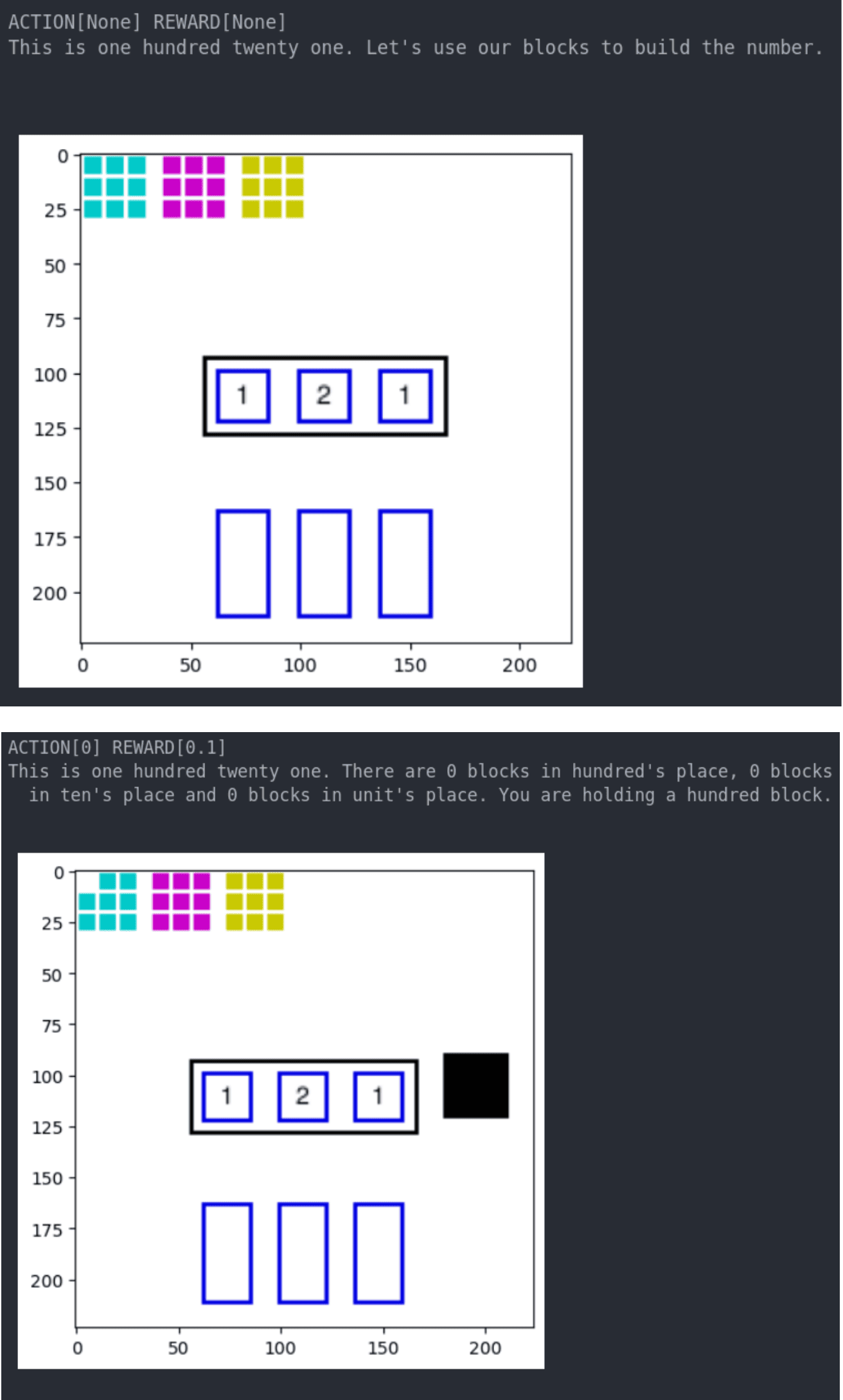
📊 实验亮点
实验结果表明,某些特定的语言结构(具体内容未知)能够显著提高强化学习智能体的数字理解能力,并加速学习过程。模型预测的最佳数字呈现序列能够显著提高学习效率(具体提升幅度未知)。这些结果验证了该方法在模拟儿童数字学习过程中的有效性,并为教育策略提供了新的思路。
🎯 应用场景
该研究成果可应用于开发个性化的数字学习App和教育机器人,根据儿童的学习特点和语言偏好,提供定制化的教学内容和学习路径。此外,该研究还可以为教育工作者提供参考,帮助他们设计更有效的教学策略,提高儿童的数字学习效率。未来,该研究还可以扩展到其他学科的学习,例如语言学习和科学学习。
📄 摘要(原文)
This paper investigates how children learn numbers using the framework of reinforcement learning (RL), with a focus on the impact of language instructions. The motivation for using reinforcement learning stems from its parallels with psychological learning theories in controlled environments. By using state of the art deep reinforcement learning models, we simulate and analyze the effects of various forms of language instructions on number acquisition. Our findings indicate that certain linguistic structures more effectively improve numerical comprehension in RL agents. Additionally, our model predicts optimal sequences for presenting numbers to RL agents which enhance their speed of learning. This research provides valuable insights into the interplay between language and numerical cognition, with implications for both educational strategies and the development of artificial intelligence systems designed to support early childhood learning.