Sample then Identify: A General Framework for Risk Control and Assessment in Multimodal Large Language Models
作者: Qingni Wang, Tiantian Geng, Zhiyuan Wang, Teng Wang, Bo Fu, Feng Zheng
分类: cs.CL, cs.AI, cs.LG, cs.MM
发布日期: 2024-10-10 (更新: 2025-06-29)
备注: Accepted by ICLR 2025 Spotlights
💡 一句话要点
提出TRON框架,用于多模态大语言模型风险控制与评估,提升开放环境下的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 风险控制 风险评估 Conformal Prediction 自洽性 视频问答 开放式问答
📋 核心要点
- 现有MLLM方法依赖模型内部信息或局限于多项选择,泛化性和适应性受限,难以应对开放环境。
- TRON框架通过新颖的conformal score采样响应集,并利用自洽性理论识别高质量响应,控制风险。
- 实验表明,TRON在VideoQA数据集上实现了期望的错误率,去重后的预测集更高效稳定。
📝 摘要(中文)
多模态大语言模型(MLLM)在各种任务中展现出令人瞩目的进步,但仍然面临着严重的可信度问题。以往的研究在语言建模中应用Split Conformal Prediction (SCP)来构建具有统计保证的预测集。然而,这些方法通常依赖于内部模型logits或仅限于多项选择设置,这阻碍了它们在动态、开放环境中的通用性和适应性。在本文中,我们介绍TRON,这是一个两步风险控制和评估框架,适用于任何支持开放式和封闭式采样的MLLM。TRON包括两个主要组成部分:(1) 一种新颖的conformal score,用于采样最小尺寸的响应集;(2) 一种nonconformity score,用于基于自洽性理论识别高质量的响应,通过两个特定的风险级别控制错误率。此外,我们首次研究了开放式上下文中预测集中的语义冗余,从而产生了一种基于平均集合大小的有前景的MLLM评估指标。我们在四个视频问答(VideoQA)数据集上利用八个MLLM进行的全面实验表明,TRON实现了由两个用户指定的风险级别限定的期望错误率。此外,去重的预测集保持了适应性,同时对于不同风险级别下的风险评估更加高效和稳定。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLM)在开放式问答等任务中表现出色,但其生成结果的可靠性难以保证。传统的Split Conformal Prediction (SCP)方法虽然可以提供统计保证,但依赖于模型内部的logits信息,或者仅适用于多项选择等封闭式场景,无法很好地应用于开放式的MLLM,并且缺乏对生成结果语义冗余的有效评估。
核心思路:TRON框架的核心思路是,首先通过采样生成多个可能的答案,然后利用自洽性理论对这些答案进行评估和筛选,最终得到一个既包含正确答案,又尽可能减少冗余的预测集合。通过控制预测集合的规模和质量,从而实现对MLLM风险的有效控制和评估。该方法不依赖于模型内部信息,适用于各种支持采样的MLLM。
技术框架:TRON框架包含两个主要阶段:采样阶段和识别阶段。
-
采样阶段:利用一种新颖的conformal score,从MLLM中采样得到一个包含多个候选答案的响应集合。该conformal score旨在生成最小尺寸的响应集,同时保证覆盖率。
-
识别阶段:使用一种nonconformity score,基于自洽性理论评估候选答案的质量。该nonconformity score用于识别高质量的响应,并根据用户指定的风险级别控制错误率。通过对响应集合进行去重,可以进一步提高效率和稳定性。
关键创新:TRON框架的关键创新在于:
-
提出了一种适用于开放式MLLM的风险控制和评估框架,不依赖于模型内部信息。
-
引入了基于自洽性理论的nonconformity score,用于识别高质量的响应。
-
首次研究了开放式上下文中预测集中的语义冗余,并提出了基于平均集合大小的MLLM评估指标。
关键设计:TRON框架的关键设计包括:
-
Conformal Score的设计:具体的设计细节未知,但其目标是生成最小尺寸的响应集,同时保证覆盖率。
-
Nonconformity Score的设计:基于自洽性理论,具体实现未知,但其目标是评估候选答案的质量。
-
风险级别的控制:通过调整nonconformity score的阈值,可以控制错误率,从而实现用户指定的风险级别。
🖼️ 关键图片

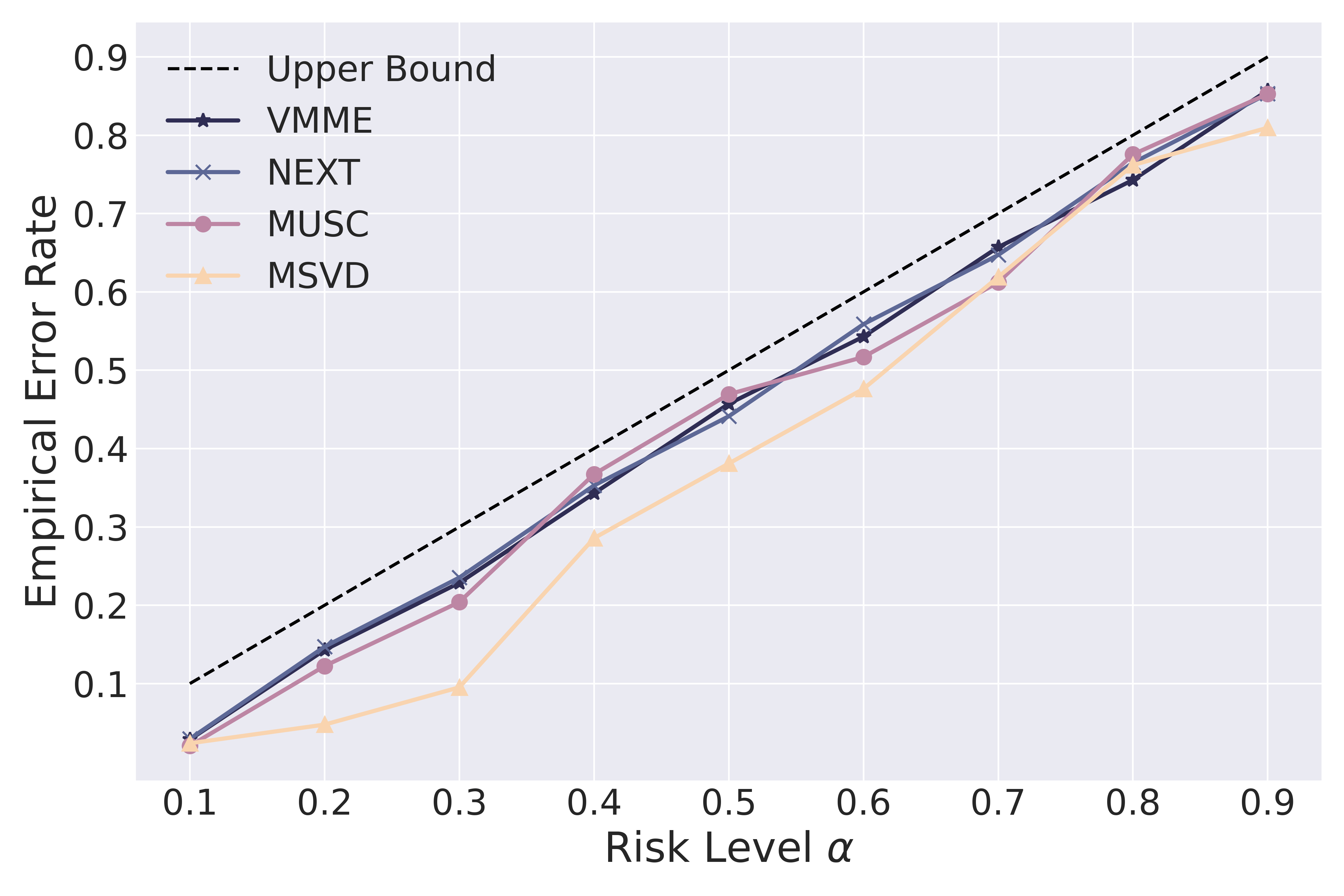
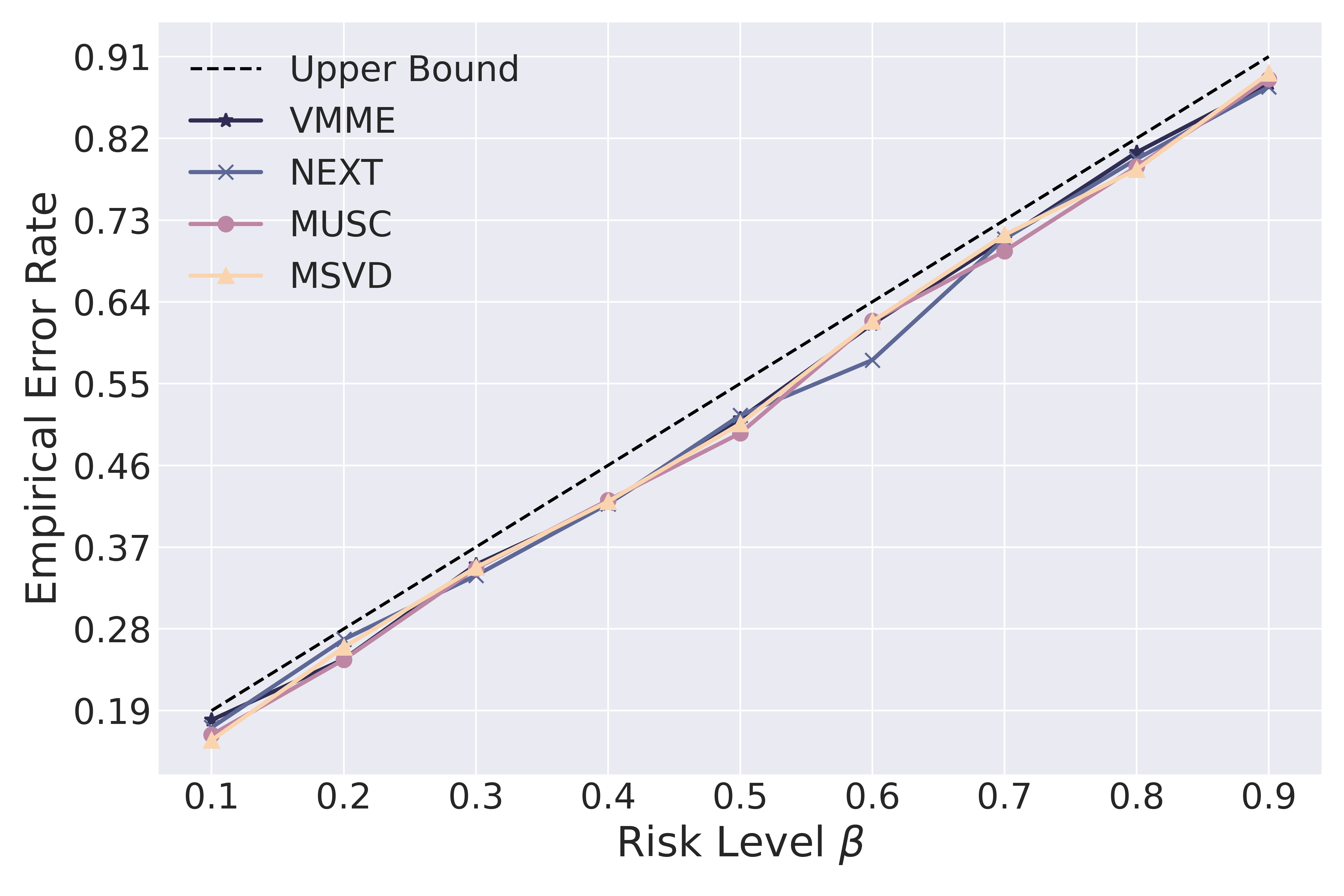
📊 实验亮点
实验结果表明,TRON框架在四个VideoQA数据集上,利用八个MLLM,实现了用户指定的风险级别限定的期望错误率。此外,去重后的预测集在保持适应性的同时,对于不同风险级别下的风险评估更加高效和稳定。具体性能提升数据未知,但实验验证了TRON框架的有效性和实用性。
🎯 应用场景
TRON框架可应用于各种需要高可靠性的多模态大语言模型应用场景,例如医疗诊断、金融风控、自动驾驶等。通过提供风险可控的预测结果,可以提高决策的准确性和安全性,降低潜在风险。该框架还有助于评估和比较不同MLLM的可靠性,促进MLLM的进一步发展。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) exhibit promising advancements across various tasks, yet they still encounter significant trustworthiness issues. Prior studies apply Split Conformal Prediction (SCP) in language modeling to construct prediction sets with statistical guarantees. However, these methods typically rely on internal model logits or are restricted to multiple-choice settings, which hampers their generalizability and adaptability in dynamic, open-ended environments. In this paper, we introduce TRON, a two-step framework for risk control and assessment, applicable to any MLLM that supports sampling in both open-ended and closed-ended scenarios. TRON comprises two main components: (1) a novel conformal score to sample response sets of minimum size, and (2) a nonconformity score to identify high-quality responses based on self-consistency theory, controlling the error rates by two specific risk levels. Furthermore, we investigate semantic redundancy in prediction sets within open-ended contexts for the first time, leading to a promising evaluation metric for MLLMs based on average set size. Our comprehensive experiments across four Video Question-Answering (VideoQA) datasets utilizing eight MLLMs show that TRON achieves desired error rates bounded by two user-specified risk levels. Additionally, deduplicated prediction sets maintain adaptiveness while being more efficient and stable for risk assessment under different risk levels.