Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
作者: Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, Zhengyang Tang, Benyou Wang, Daoguang Zan, Shanghaoran Quan, Ge Zhang, Lei Sha, Yichang Zhang, Xuancheng Ren, Tianyu Liu, Baobao Chang
分类: cs.CL
发布日期: 2024-10-10 (更新: 2024-12-24)
备注: 30 pages
💡 一句话要点
提出Omni-MATH,一个面向大语言模型的奥林匹克级别数学推理基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 奥林匹克数学 基准数据集 模型评估
📋 核心要点
- 现有数学推理基准(如GSM8K、MATH)已无法充分挑战当前先进的大语言模型,亟需更具难度的评估标准。
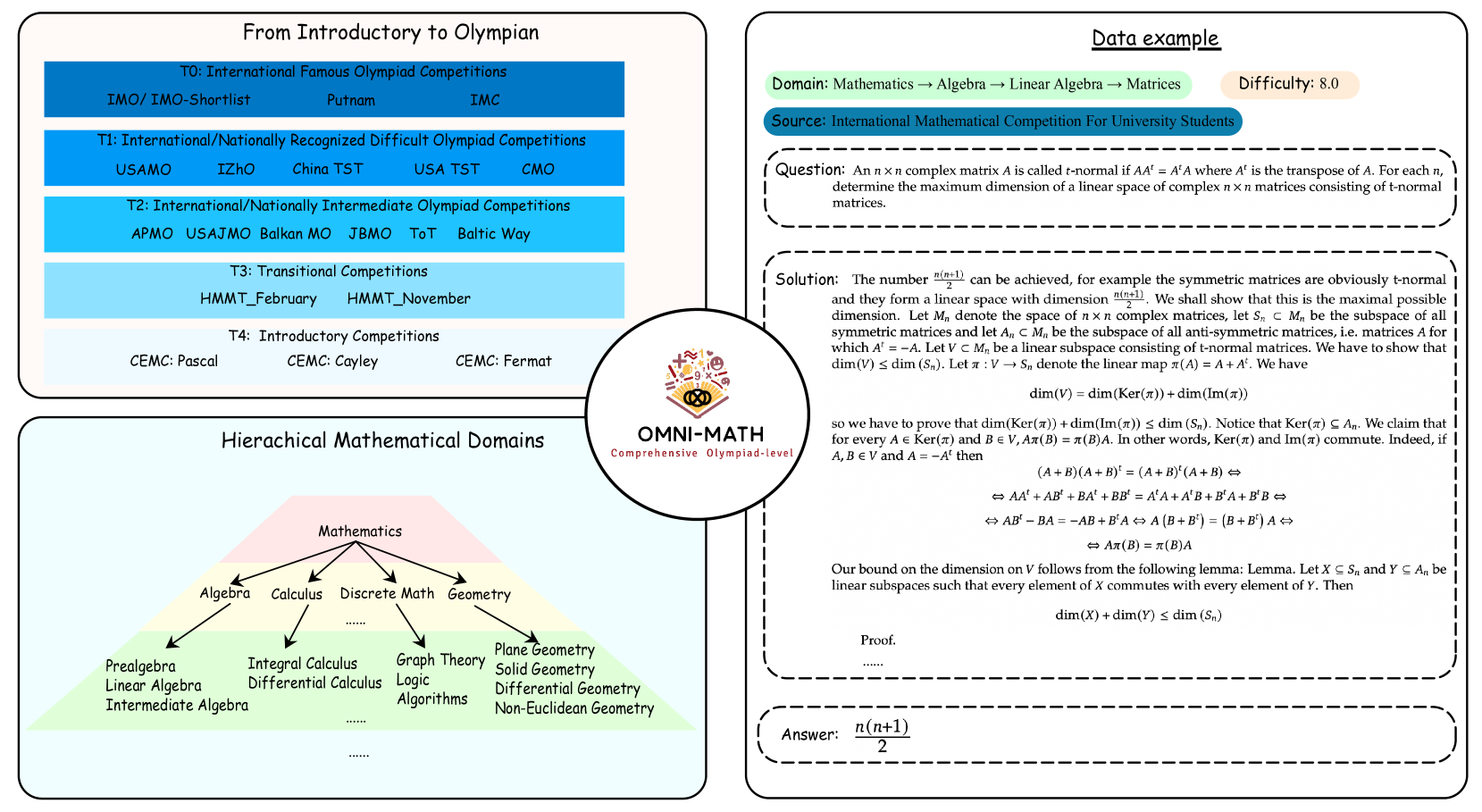
- Omni-MATH构建了一个包含4428道奥林匹克级别数学题目的数据集,覆盖多个子领域和难度等级,并进行人工标注。
- 实验表明,即使是OpenAI o1系列模型在Omni-MATH上也表现出显著的性能瓶颈,表明奥赛级别数学推理仍具挑战。
📝 摘要(中文)
本文提出了Omni-MATH,一个全面且具有挑战性的基准,专门用于评估大语言模型在奥林匹克级别数学推理方面的能力。与现有的奥赛相关基准不同,该数据集仅关注数学,包含4428个竞赛级别的问题,并经过严格的人工标注。这些问题被细致地分为33个以上的子领域,跨越10个以上的不同难度级别,从而能够全面评估模型在奥林匹克数学推理中的表现。基于此基准的深入分析表明,即使是最先进的模型,如OpenAI o1-mini和OpenAI o1-preview,在极具挑战性的奥林匹克级别问题上也表现不佳,准确率分别为60.54%和52.55%,突显了奥林匹克级别数学推理方面的巨大挑战。
🔬 方法详解
问题定义:现有的大语言模型在数学推理能力上取得了显著进展,但在解决奥林匹克级别的数学问题时仍然面临挑战。现有的基准数据集,如GSM8K和MATH,已经无法充分评估这些模型的能力,因为它们在这些数据集上已经达到了很高的准确率。因此,需要一个更具挑战性的基准来推动大语言模型在数学推理方面的进一步发展。
核心思路:Omni-MATH的核心思路是构建一个高质量、高难度的数学问题数据集,专门用于评估大语言模型在奥林匹克级别的数学推理能力。该数据集包含大量竞赛级别的数学问题,覆盖多个数学子领域和难度等级,并经过严格的人工标注,以确保数据集的质量和可靠性。通过在这个数据集上评估大语言模型的性能,可以更准确地了解模型在数学推理方面的优势和不足。
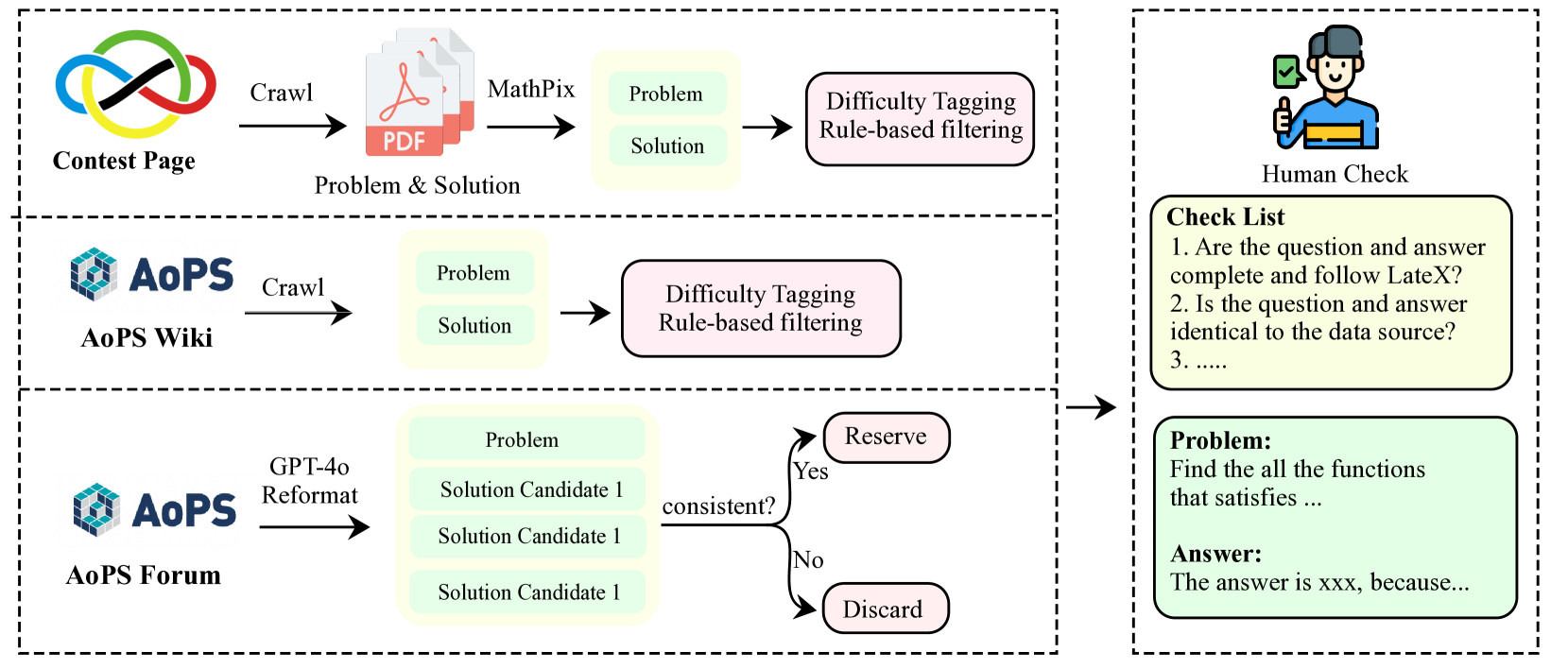
技术框架:Omni-MATH数据集的构建主要包括以下几个阶段:1) 数据收集:从各种数学竞赛和奥林匹克数学资源中收集大量的数学问题。2) 数据清洗:对收集到的问题进行清洗和筛选,去除重复、错误或不符合要求的问题。3) 数据标注:对筛选后的问题进行人工标注,包括问题类型、难度等级、涉及的数学知识点等。4) 数据划分:将标注后的问题划分为训练集、验证集和测试集,用于模型的训练和评估。
关键创新:Omni-MATH的关键创新在于其数据集的难度和规模。与现有的数学推理基准相比,Omni-MATH包含的问题更加复杂和具有挑战性,需要更高级的数学推理能力才能解决。此外,Omni-MATH的数据集规模也更大,覆盖了更多的数学子领域和难度等级,从而能够更全面地评估大语言模型的数学推理能力。
关键设计:Omni-MATH数据集包含4428个竞赛级别的数学问题,分为33个以上的子领域,跨越10个以上的难度级别。数据集中的每个问题都经过人工标注,包括问题类型、难度等级、涉及的数学知识点等。数据集被划分为训练集、验证集和测试集,用于模型的训练和评估。具体的数据划分比例未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是目前最先进的大语言模型,如OpenAI o1-mini和OpenAI o1-preview,在Omni-MATH数据集上的准确率也分别只有60.54%和52.55%。这表明,当前的大语言模型在奥林匹克级别的数学推理方面仍然存在很大的提升空间,Omni-MATH可以作为一个有效的基准来推动相关研究。
🎯 应用场景
Omni-MATH可用于评估和提升大语言模型在数学、科学、工程等领域的推理能力。通过在该基准上训练和评估模型,可以推动模型在解决复杂数学问题方面的能力,从而应用于自动化定理证明、科学发现、教育辅导等领域,提升相关任务的效率和准确性。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8\% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54\% and 52.55\% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.