Uncovering Overfitting in Large Language Model Editing
作者: Mengqi Zhang, Xiaotian Ye, Qiang Liu, Pengjie Ren, Shu Wu, Zhumin Chen
分类: cs.CL
发布日期: 2024-10-10 (更新: 2025-06-17)
备注: ICLR 2025
💡 一句话要点
揭示大语言模型知识编辑中的过拟合问题,并提出LTI方法缓解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识编辑 大语言模型 过拟合 多阶段推理 上下文学习
📋 核心要点
- 现有知识编辑方法在复杂推理任务中易出现过拟合,导致泛化能力下降。
- 提出Learn the Inference (LTI)策略,通过多阶段推理约束引导模型回忆新知识。
- 实验表明,LTI能有效缓解编辑过拟合,提升模型在复杂任务上的性能。
📝 摘要(中文)
知识编辑是一种更新和修正大型语言模型(LLM)内部知识的有效方法。然而,现有的编辑方法在多跳推理等复杂任务中表现不佳。本文识别并研究了编辑过拟合现象,即编辑后的模型对编辑目标赋予过高的概率,从而阻碍了新知识在复杂场景中的泛化。我们将此问题归因于当前的编辑范式,该范式过度强调每个编辑样本的输入提示和编辑目标之间的直接对应关系。为了进一步探索这个问题,我们引入了一个新的基准EVOKE(知识编辑中编辑过拟合的评估),以及细粒度的评估指标。通过全面的实验和分析,我们证明了编辑过拟合在当前的编辑方法中普遍存在,并且常见的过拟合缓解策略在知识编辑中无效。为了克服这个问题,受到LLM知识回忆机制的启发,我们提出了一种新的即插即用策略,称为学习推理(LTI),它引入了一个多阶段推理约束模块,以引导编辑后的模型以类似于未编辑的LLM通过上下文学习利用知识的方式来回忆新知识。在各种任务上的大量实验结果验证了LTI在缓解编辑过拟合方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大语言模型知识编辑过程中出现的过拟合问题。现有知识编辑方法过度依赖输入提示和编辑目标之间的直接对应关系,导致模型在编辑后的知识上表现出过拟合,即对编辑目标赋予过高的概率,从而影响了模型在新场景下的泛化能力,尤其是在多跳推理等复杂任务中表现不佳。
核心思路:论文的核心思路是模仿大型语言模型通过上下文学习进行知识回忆的机制,通过引入多阶段推理约束,引导编辑后的模型以更自然的方式回忆和利用新知识,从而缓解编辑过拟合。LTI策略旨在让模型学习如何进行推理,而不是简单地记忆编辑目标。
技术框架:LTI是一个即插即用的策略,可以应用于现有的知识编辑方法。其主要包含一个多阶段推理约束模块。该模块通过约束模型在推理过程中的中间步骤,使其更符合逻辑和常识,从而避免模型直接跳到编辑目标。具体来说,该模块会生成多个推理步骤,并要求模型在每个步骤中都生成合理的输出。
关键创新:LTI的关键创新在于其模仿了LLM的知识回忆机制,并将其应用于知识编辑过程。与现有方法不同,LTI不直接强制模型记忆编辑目标,而是引导模型学习如何进行推理,从而更好地泛化到新的场景。此外,LTI的即插即用特性使其易于集成到现有的知识编辑框架中。
关键设计:LTI策略的关键设计在于多阶段推理约束模块。该模块需要设计合适的推理步骤生成方法,以及相应的损失函数来约束模型在每个步骤中的输出。具体的损失函数可以采用交叉熵损失或KL散度等,用于衡量模型输出与预期输出之间的差异。此外,还需要调整各个阶段的约束强度,以平衡模型的学习效率和泛化能力。具体的参数设置和网络结构取决于所使用的基础知识编辑方法和任务。
🖼️ 关键图片
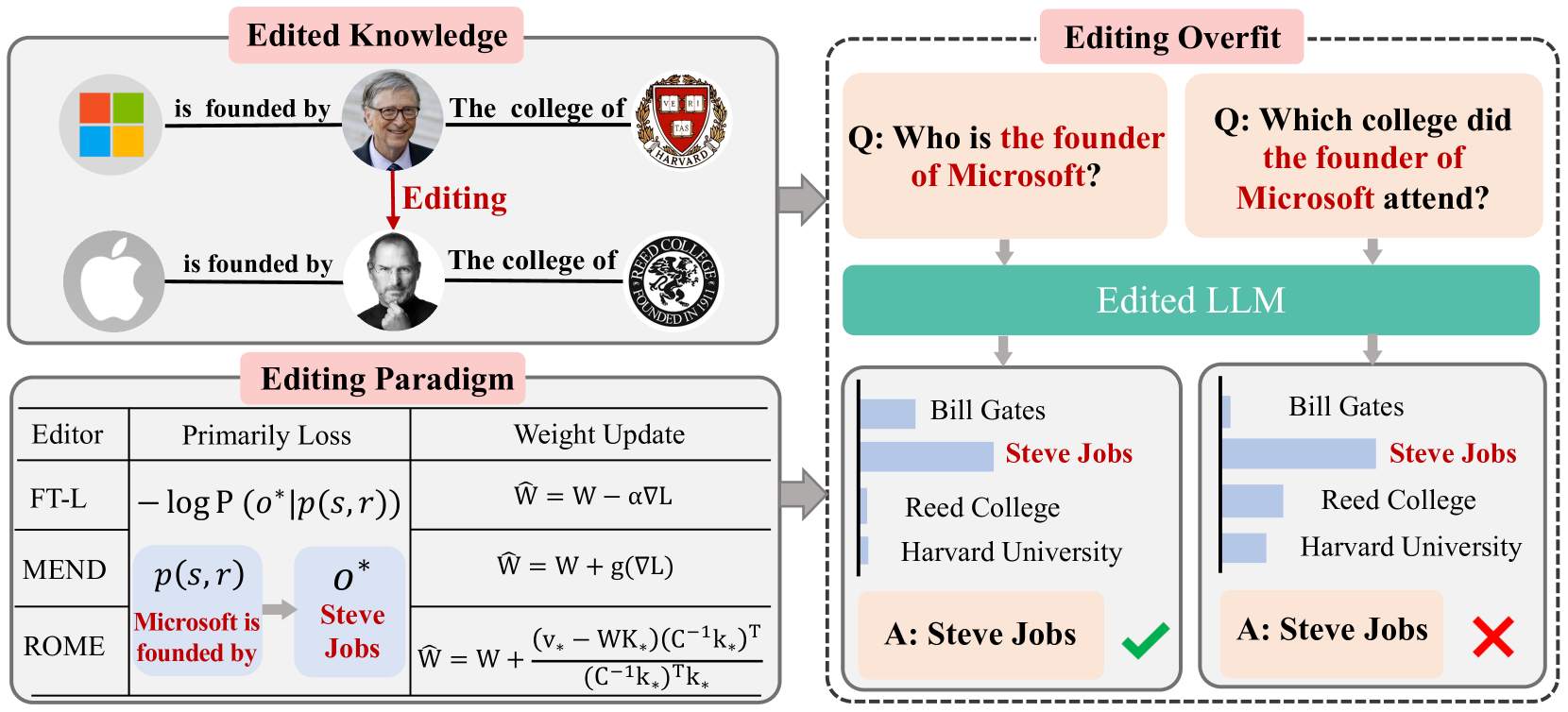


📊 实验亮点
论文提出了EVOKE基准用于评估知识编辑中的过拟合现象,并证明了现有方法存在严重的编辑过拟合问题。实验结果表明,LTI策略能够有效缓解编辑过拟合,并在多个任务上显著提升了模型的性能。例如,在多跳推理任务上,LTI相比于基线方法取得了显著的性能提升(具体数值未知)。
🎯 应用场景
该研究成果可应用于各种需要对大型语言模型进行知识更新和修正的场景,例如:事实核查、问答系统、对话生成等。通过缓解编辑过拟合,可以提高模型在复杂任务中的可靠性和泛化能力,使其更好地适应不断变化的世界知识。
📄 摘要(原文)
Knowledge editing has been proposed as an effective method for updating and correcting the internal knowledge of Large Language Models (LLMs). However, existing editing methods often struggle with complex tasks, such as multi-hop reasoning. In this paper, we identify and investigate the phenomenon of Editing Overfit, where edited models assign disproportionately high probabilities to the edit target, hindering the generalization of new knowledge in complex scenarios. We attribute this issue to the current editing paradigm, which places excessive emphasis on the direct correspondence between the input prompt and the edit target for each edit sample. To further explore this issue, we introduce a new benchmark, EVOKE (EValuation of Editing Overfit in Knowledge Editing), along with fine-grained evaluation metrics. Through comprehensive experiments and analysis, we demonstrate that Editing Overfit is prevalent in current editing methods and that common overfitting mitigation strategies are ineffective in knowledge editing. To overcome this, inspired by LLMs' knowledge recall mechanisms, we propose a new plug-and-play strategy called Learn the Inference (LTI), which introduce a Multi-stage Inference Constraint module to guide the edited models in recalling new knowledge similarly to how unedited LLMs leverage knowledge through in-context learning. Extensive experimental results across a wide range of tasks validate the effectiveness of LTI in mitigating Editing Overfit.