How Does Vision-Language Adaptation Impact the Safety of Vision Language Models?
作者: Seongyun Lee, Geewook Kim, Jiyeon Kim, Hyunji Lee, Hoyeon Chang, Sue Hyun Park, Minjoon Seo
分类: cs.CL, cs.CV
发布日期: 2024-10-10 (更新: 2024-11-15)
备注: Work in Progress
💡 一句话要点
研究视觉语言适配对视觉语言模型安全性的影响,并提出权重融合方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 安全性 视觉语言适配 权重融合 安全微调
📋 核心要点
- 现有视觉语言适配方法在提升模型多模态能力的同时,往往忽略了对模型安全性的影响,导致安全性下降。
- 该研究分析了视觉语言适配对模型安全性的影响,并提出权重融合方法,旨在缓解适配过程中的安全性退化问题。
- 实验表明,即使使用安全数据进行适配,模型安全性仍会下降;权重融合方法能在维持模型有用性的同时,有效降低安全性退化。
📝 摘要(中文)
视觉语言适配(VL adaptation)将大型语言模型(LLMs)转化为大型视觉语言模型(LVLMs),以执行多模态任务,但此过程通常会损害原始LLM中固有的安全能力。尽管由于安全措施的削弱可能造成危害,但对VL适配对安全性的影响的深入分析仍然不足。本研究探讨了VL适配如何影响安全性,并评估了安全微调方法的影响。分析表明,即使在安全的数据上进行训练,VL适配也会导致安全性下降。虽然使用安全数据集进行监督微调或从人类反馈中进行强化学习等安全调整技术可以缓解一些风险,但由于过度拒绝问题,它们仍然会导致安全降级和有用性降低。对内部模型权重的进一步分析表明,VL适配可能会影响某些与安全相关的层,从而可能降低整体安全级别。此外,我们的研究结果表明,VL适配和安全调整的目标是不同的,这通常导致它们的同时应用并非最佳。为了解决这个问题,我们建议使用权重合并方法作为一种有效的解决方案,可以在保持有用性的同时有效地减少安全降级。这些见解有助于指导开发更可靠和安全的LVLM,以用于实际应用。
🔬 方法详解
问题定义:论文旨在解决视觉语言适配过程中,大型视觉语言模型(LVLMs)的安全性下降问题。现有方法在将大型语言模型(LLMs)适配到视觉语言领域时,往往会牺牲LLM原有的安全机制,导致模型更容易产生有害或不安全的内容。现有安全微调方法,如监督微调和强化学习,虽然能缓解部分问题,但会导致模型过度拒绝正常请求,降低可用性。
核心思路:论文的核心思路是,视觉语言适配和安全调整的目标是不同的,直接进行安全微调可能会与适配的目标冲突,导致性能下降。因此,论文提出使用权重融合的方法,将适配后的模型和安全微调后的模型进行融合,从而在不影响模型可用性的前提下,提升模型的安全性。
技术框架:论文主要包含以下几个阶段:1) 使用视觉语言数据对LLM进行适配,得到LVLM;2) 使用安全数据集对LLM进行安全微调,得到安全模型;3) 分析适配后的LVLM的安全性,并与原始LLM进行对比;4) 使用权重融合方法,将LVLM和安全模型进行融合,得到最终模型;5) 评估最终模型的安全性和可用性。
关键创新:论文的关键创新在于:1) 首次系统性地研究了视觉语言适配对模型安全性的影响;2) 提出了权重融合方法,有效缓解了适配过程中的安全性退化问题,同时保持了模型的可用性;3) 通过分析模型内部权重,揭示了视觉语言适配可能影响模型中与安全相关的层。
关键设计:权重融合方法的核心在于确定融合的权重比例。论文通过实验确定了最佳的权重比例,使得融合后的模型在安全性和可用性之间达到平衡。此外,论文还分析了不同安全微调方法对模型安全性和可用性的影响,为选择合适的安全微调方法提供了指导。
🖼️ 关键图片

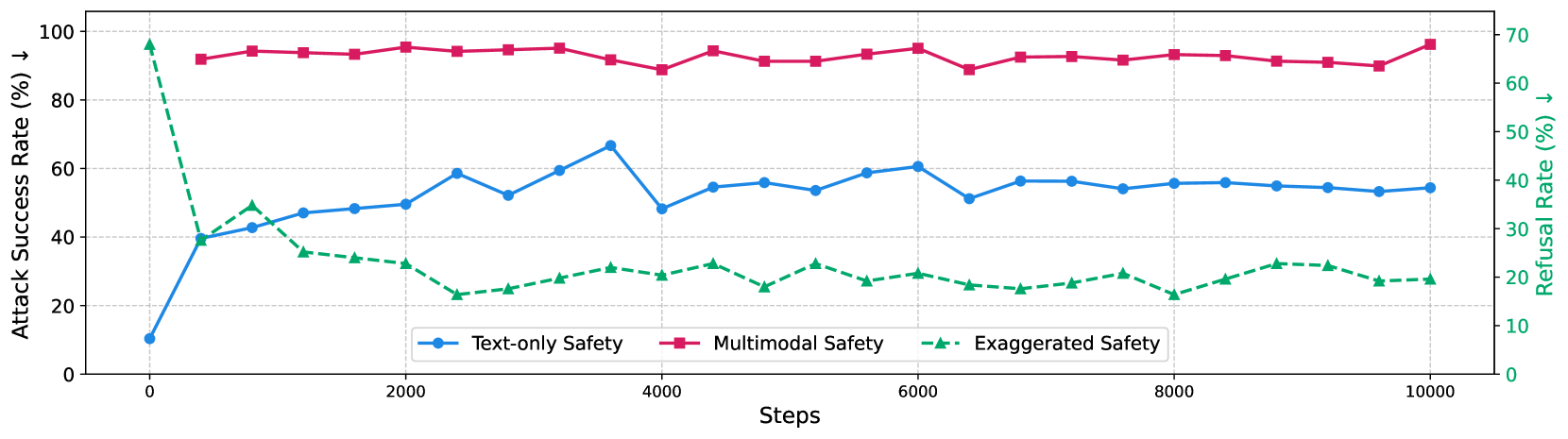

📊 实验亮点
研究表明,视觉语言适配会导致模型安全性下降,即使使用安全数据进行训练也是如此。权重融合方法能够在维持模型有用性的同时,有效降低安全性退化。实验结果表明,使用权重融合方法后,模型的安全性得到了显著提升,同时保持了较高的可用性。
🎯 应用场景
该研究成果可应用于开发更安全可靠的视觉语言模型,例如在智能客服、自动驾驶、医疗诊断等领域,可以有效防止模型生成有害信息,保障用户安全。此外,该研究提出的权重融合方法,也可以推广到其他模型的安全增强任务中。
📄 摘要(原文)
Vision-Language adaptation (VL adaptation) transforms Large Language Models (LLMs) into Large Vision-Language Models (LVLMs) for multimodal tasks, but this process often compromises the inherent safety capabilities embedded in the original LLMs. Despite potential harmfulness due to weakened safety measures, in-depth analysis on the effects of VL adaptation on safety remains under-explored. This study examines how VL adaptation influences safety and evaluates the impact of safety fine-tuning methods. Our analysis reveals that safety degradation occurs during VL adaptation, even when the training data is safe. While safety tuning techniques like supervised fine-tuning with safety datasets or reinforcement learning from human feedback mitigate some risks, they still lead to safety degradation and a reduction in helpfulness due to over-rejection issues. Further analysis of internal model weights suggests that VL adaptation may impact certain safety-related layers, potentially lowering overall safety levels. Additionally, our findings demonstrate that the objectives of VL adaptation and safety tuning are divergent, which often results in their simultaneous application being suboptimal. To address this, we suggest the weight merging approach as an optimal solution effectively reducing safety degradation while maintaining helpfulness. These insights help guide the development of more reliable and secure LVLMs for real-world applications.