Better Language Models Exhibit Higher Visual Alignment
作者: Jona Ruthardt, Gertjan J. Burghouts, Serge Belongie, Yuki M. Asano
分类: cs.CL, cs.AI, cs.CV
发布日期: 2024-10-09 (更新: 2026-01-16)
💡 一句话要点
研究表明,更优的语言模型表现出更高的视觉对齐能力,并提出高效的视觉-语言融合方法ShareLock。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 语言模型对齐 零样本学习 跨语言学习 多模态融合
📋 核心要点
- 现有视觉-语言模型依赖大量配对数据和计算资源,而纯文本LLM的视觉对齐能力未被充分探索。
- 论文提出ShareLock,一种轻量级视觉-语言融合方法,利用冻结的视觉和语言骨干网络,减少对配对数据的需求。
- 实验表明,ShareLock在ImageNet和跨语言图像分类任务上表现出色,显著优于CLIP等基线模型。
📝 摘要(中文)
本文系统性地评估了纯文本大型语言模型(LLMs)与视觉世界的对齐程度。通过将各种语言模型的冻结表示整合到判别式视觉-语言框架中,并测量其对新概念的零样本泛化能力,研究发现,基于解码器的模型比基于编码器的模型表现出更强的视觉对齐能力,即使控制模型和数据集大小也是如此。此外,语言建模性能与视觉泛化能力相关,表明单模态LLM的进步可以同时改进视觉模型。基于这些发现,本文提出了一种轻量级的融合冻结视觉和语言骨干网络的方法ShareLock。ShareLock在各项任务中实现了稳健的性能,同时大大减少了对配对数据和计算的需求。仅使用56.3万个图像-文本对和不到一个GPU小时的训练,它在ImageNet上达到了51%的准确率。在跨语言设置中,ShareLock显著优于CLIP,在中文图像分类上实现了38.7%的top-1准确率,而CLIP仅为1.4%。代码已开源。
🔬 方法详解
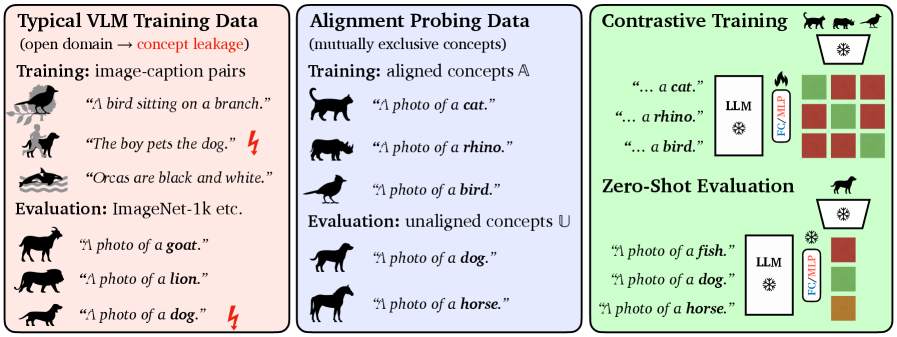
问题定义:现有视觉-语言模型训练需要大量的图像-文本配对数据,且计算成本高昂。此外,纯文本LLM在多大程度上与视觉世界对齐,以及如何有效利用LLM的知识来提升视觉任务的性能,是亟待解决的问题。现有方法通常需要从头训练或微调大型模型,计算资源消耗巨大。
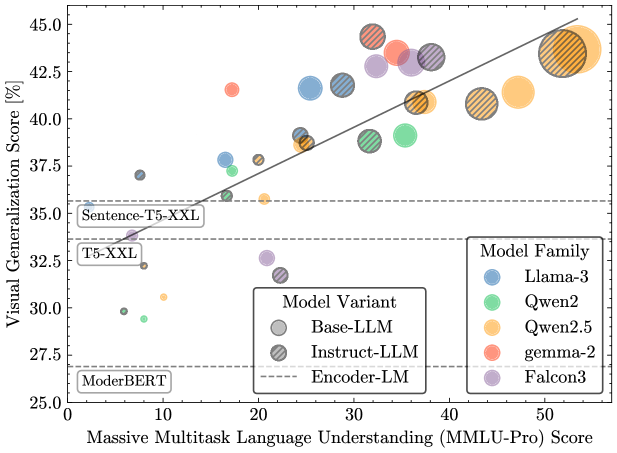
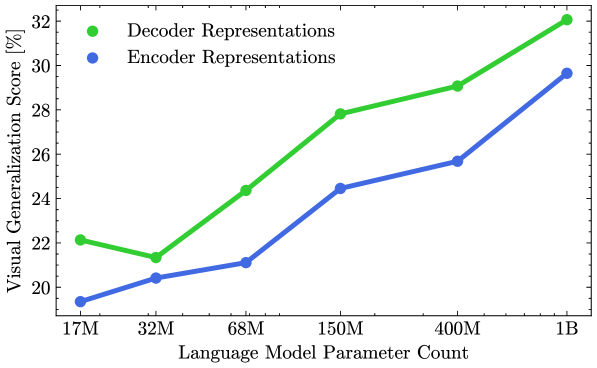
核心思路:论文的核心思路是利用预训练的、冻结的LLM的表征能力,并将其与视觉表征进行融合,从而在减少训练数据和计算资源需求的同时,提升视觉任务的性能。通过研究不同类型的LLM(编码器 vs 解码器)的视觉对齐能力,发现解码器模型具有更强的视觉对齐能力,并以此为基础设计高效的融合方法。
技术框架:ShareLock框架包含两个主要的冻结骨干网络:一个视觉骨干网络和一个语言骨干网络。视觉骨干网络负责提取图像的视觉特征,语言骨干网络负责提取文本的语义特征。ShareLock通过一个轻量级的可训练模块,将视觉和语言特征进行融合,并用于下游任务的预测。整体流程包括:图像输入 -> 视觉骨干网络 -> 视觉特征;文本输入 -> 语言骨干网络 -> 语言特征;视觉特征 + 语言特征 -> ShareLock融合模块 -> 预测结果。
关键创新:ShareLock的关键创新在于其轻量级的融合模块和对不同类型LLM视觉对齐能力的洞察。与需要大量训练数据的传统方法不同,ShareLock只需要少量配对数据即可进行训练,大大降低了计算成本。此外,通过实验发现解码器模型具有更强的视觉对齐能力,为选择合适的LLM提供了指导。
关键设计:ShareLock的融合模块采用简单的线性层或MLP结构,参数量小,易于训练。损失函数采用交叉熵损失,用于分类任务的训练。在实验中,作者探索了不同的视觉和语言骨干网络组合,并对ShareLock的超参数进行了优化,例如学习率、batch size等。
🖼️ 关键图片
📊 实验亮点
ShareLock在ImageNet上仅使用56.3k图像-文本对和不到1 GPU小时的训练,达到了51%的准确率。在跨语言图像分类任务中,ShareLock在中文数据集上取得了38.7%的top-1准确率,显著优于CLIP的1.4%,证明了其在低资源和跨语言场景下的优越性。
🎯 应用场景
该研究成果可应用于图像分类、图像检索、视觉问答等领域。ShareLock方法降低了对大规模配对数据的依赖,使得在数据稀缺或跨语言场景下构建高性能视觉-语言模型成为可能。未来可应用于智能客服、自动驾驶、医疗影像分析等领域,提升AI系统的多模态理解能力。
📄 摘要(原文)
How well do text-only large language models (LLMs) align with the visual world? We present a systematic evaluation of this question by incorporating frozen representations of various language models into a discriminative vision-language framework and measuring zero-shot generalization to novel concepts. We find that decoder-based models exhibit stronger visual alignment than encoders, even when controlling for model and dataset size. Moreover, language modeling performance correlates with visual generalization, suggesting that advances in unimodal LLMs can simultaneously improve vision models. Leveraging these insights, we propose ShareLock, a lightweight method for fusing frozen vision and language backbones. ShareLock achieves robust performance across tasks while drastically reducing the need for paired data and compute. With just 563k image-caption pairs and under one GPU-hour of training, it reaches 51% accuracy on ImageNet. In cross-lingual settings, ShareLock dramatically outperforms CLIP, achieving 38.7% top-1 accuracy on Chinese image classification versus CLIP's 1.4%. Code is available.