Exploring the Personality Traits of LLMs through Latent Features Steering
作者: Shu Yang, Shenzhe Zhu, Liang Liu, Lijie Hu, Mengdi Li, Di Wang
分类: cs.CL, cs.AI
发布日期: 2024-10-07 (更新: 2025-02-16)
备注: under review
💡 一句话要点
通过潜在特征引导探索LLM的个性特质
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性特质 潜在特征引导 免训练方法 社会决定论
📋 核心要点
- 现有方法对LLM如何编码和表达个性特质的机制理解不足,缺乏有效干预手段。
- 论文提出一种免训练方法,通过提取和引导LLM中的潜在特征来修改模型的行为,从而影响其个性。
- 研究分析了文化规范和环境压力等因素对LLM个性的影响,并探讨了这些因素对模型安全性的潜在影响。
📝 摘要(中文)
大型语言模型(LLM)通过生成类人文本的能力,显著推动了对话系统和角色扮演代理的发展。虽然先前的研究表明LLM可以表现出独特且一致的个性,但这些模型编码和表达特定个性特质的机制仍然知之甚少。为了解决这个问题,我们以社会决定论的理论框架为指导,研究了LLM中编码的各种因素(如文化规范和环境压力源)如何塑造其个性特质。受到LLM可解释性相关工作的启发,我们提出了一种免训练方法,通过提取和引导模型内与这些因素相对应的潜在特征来修改模型的行为,从而消除了重新训练的需要。此外,我们分析了这些因素对模型安全性的影响,重点关注它们通过个性视角产生的影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中个性特质的编码和表达机制不明确的问题。现有方法主要集中在观察LLM的个性表现,缺乏对内在机制的深入理解和有效干预手段。这使得难以控制LLM的个性,并可能导致安全问题,例如LLM表现出不期望的或有害的个性特征。
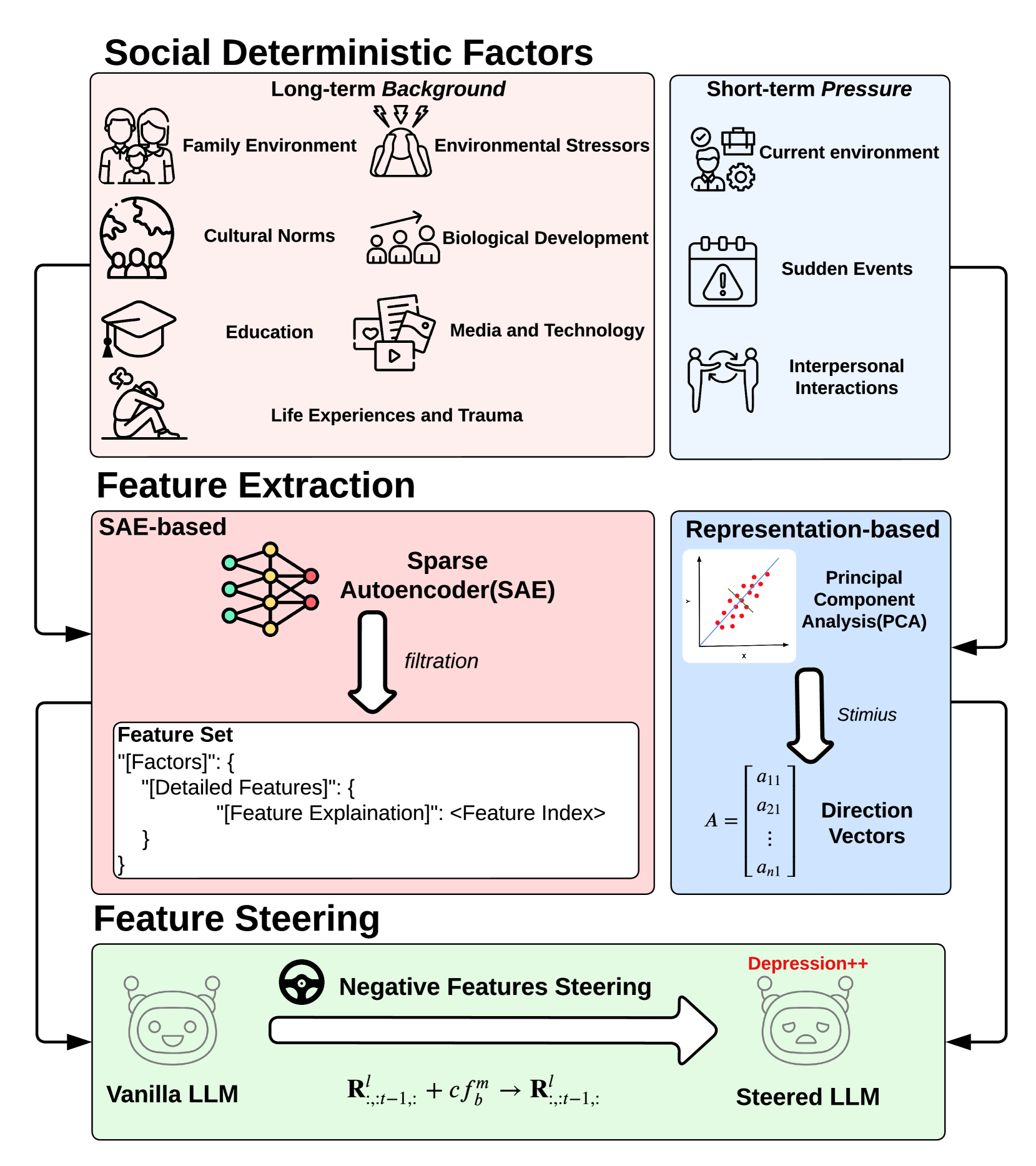
核心思路:论文的核心思路是基于社会决定论的理论框架,认为LLM的个性受到其内部编码的各种因素(如文化规范和环境压力源)的影响。通过识别和操纵这些潜在因素,可以引导LLM表现出期望的个性特质。关键在于找到与这些因素对应的潜在特征,并设计一种免训练的方法来引导这些特征。
技术框架:该方法主要包含以下几个阶段:1) 因素识别:基于社会决定论,识别可能影响LLM个性的关键因素,例如文化规范、环境压力等。2) 潜在特征提取:利用LLM可解释性技术,从LLM的内部表示中提取与这些因素相关的潜在特征。3) 特征引导:设计一种免训练的方法,通过调整或引导这些潜在特征来修改LLM的行为,从而影响其个性。4) 个性评估:使用合适的指标评估LLM在特征引导后的个性变化。
关键创新:该论文的关键创新在于提出了一种免训练的潜在特征引导方法,用于控制LLM的个性。与需要重新训练模型的方法相比,该方法更加高效和灵活。此外,该研究将社会决定论引入LLM个性研究,为理解LLM的个性提供了新的视角。
关键设计:论文的关键设计包括:1) 潜在特征提取方法:选择合适的LLM可解释性技术,例如注意力机制分析或激活最大化,来提取与特定因素相关的潜在特征。2) 特征引导策略:设计有效的特征引导策略,例如添加或减去特定方向的向量,以调整LLM的行为。3) 个性评估指标:选择合适的个性评估指标,例如基于文本生成的个性评估方法,来量化LLM的个性变化。
🖼️ 关键图片
📊 实验亮点
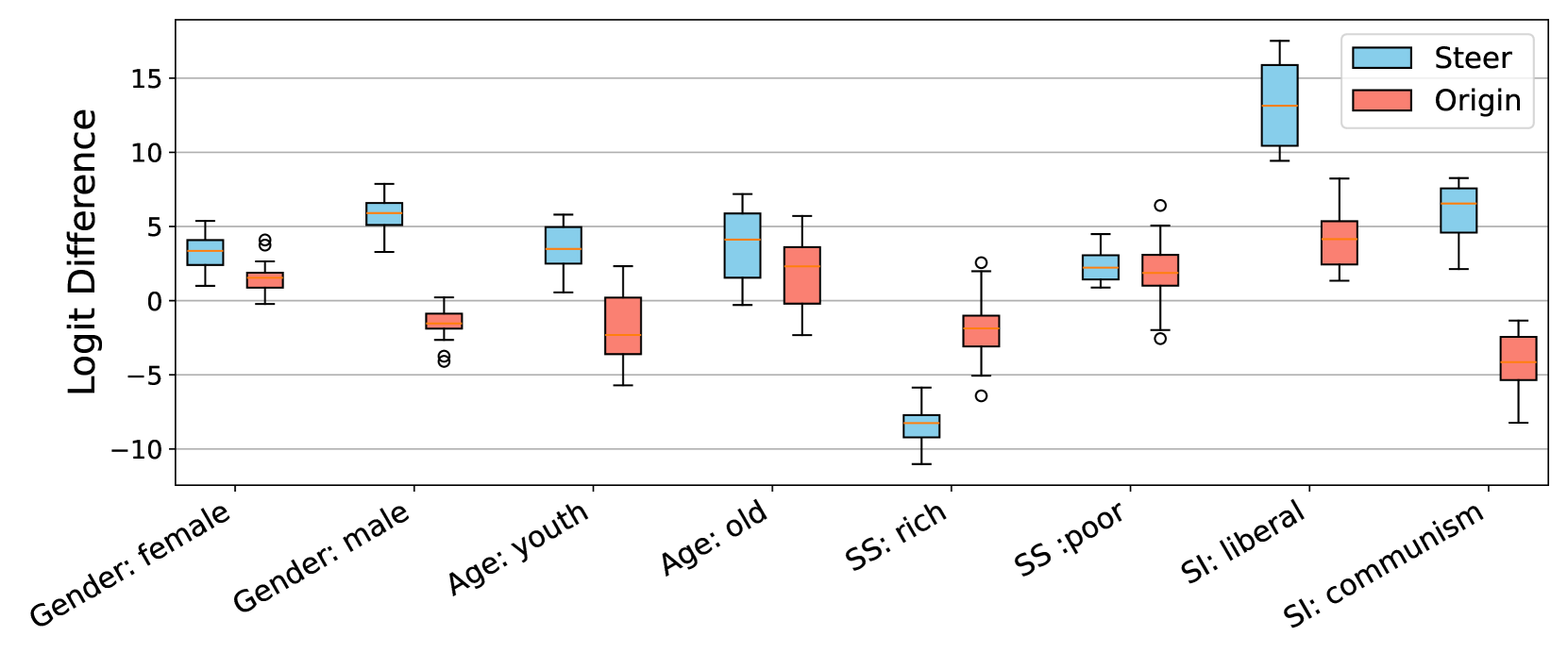
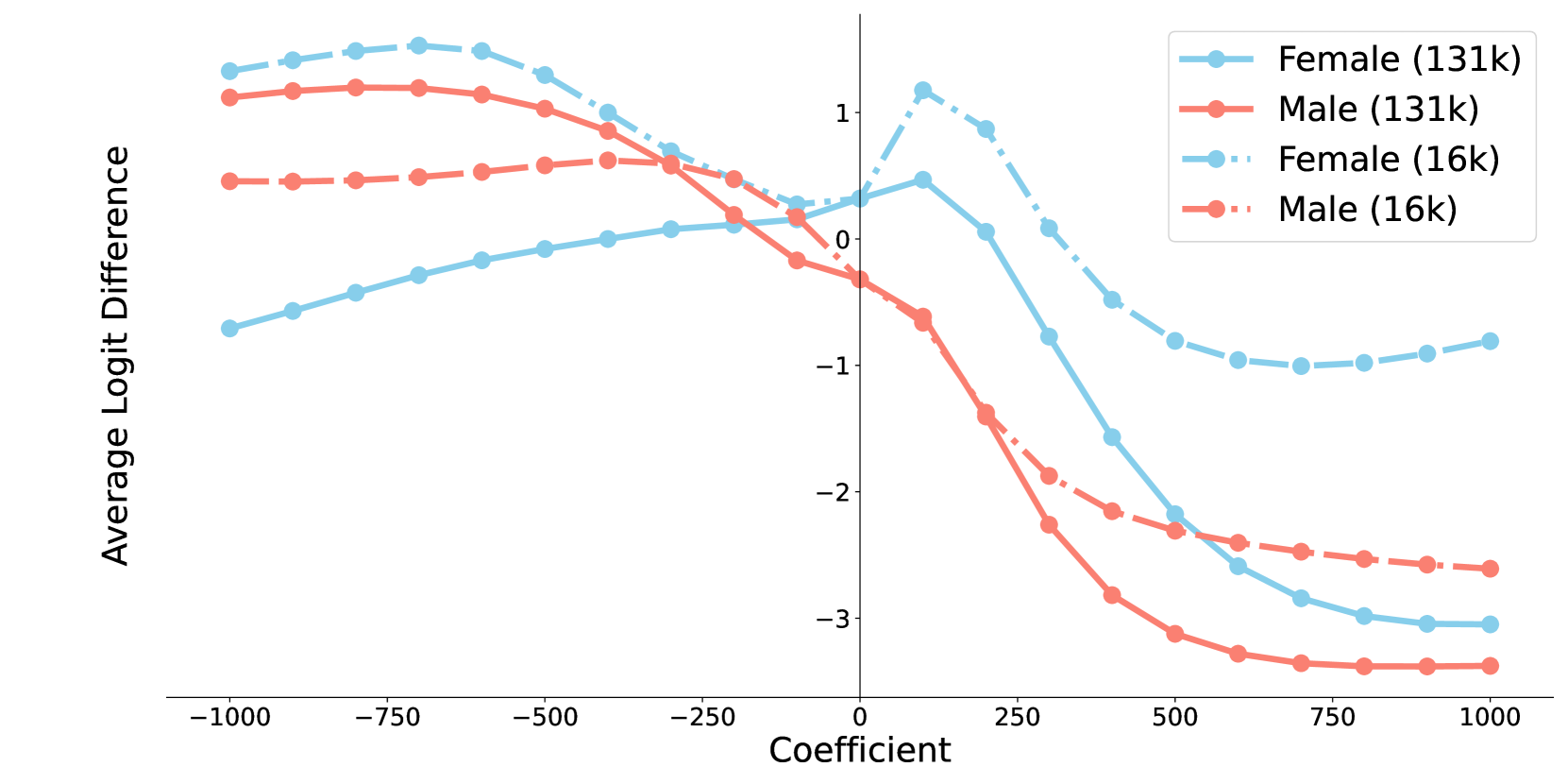
论文提出了一种免训练的潜在特征引导方法,能够有效地修改LLM的个性。通过实验验证,该方法可以使LLM表现出期望的个性特质,并提高其在特定任务中的性能。具体性能数据和对比基线在论文中详细给出,展示了该方法的有效性和优越性。
🎯 应用场景
该研究成果可应用于开发更安全、更可控的对话系统和角色扮演代理。通过控制LLM的个性,可以避免其表现出不期望的或有害的特征,并使其更好地适应不同的应用场景。例如,可以训练LLM扮演特定角色,或使其在对话中表现出特定的情感。
📄 摘要(原文)
Large language models (LLMs) have significantly advanced dialogue systems and role-playing agents through their ability to generate human-like text. While prior studies have shown that LLMs can exhibit distinct and consistent personalities, the mechanisms through which these models encode and express specific personality traits remain poorly understood. To address this, we investigate how various factors, such as cultural norms and environmental stressors, encoded within LLMs, shape their personality traits, guided by the theoretical framework of social determinism. Inspired by related work on LLM interpretability, we propose a training-free approach to modify the model's behavior by extracting and steering latent features corresponding to factors within the model, thereby eliminating the need for retraining. Furthermore, we analyze the implications of these factors for model safety, focusing on their impact through the lens of personality.