Superficial Safety Alignment Hypothesis
作者: Jianwei Li, Jung-Eun Kim
分类: cs.CL, cs.AI, cs.CR, cs.CY, cs.LG
发布日期: 2024-10-07 (更新: 2025-10-02)
💡 一句话要点
提出浅层安全对齐假设(SSAH),揭示LLM安全对齐的关键神经元组件。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 神经元分析 二元分类 浅层学习
📋 核心要点
- 现有LLM安全对齐研究忽略了安全机制的脆弱性,通用指令遵循无法保证模型的安全性。
- 提出浅层安全对齐假设(SSAH),将安全对齐视为隐式的二元分类任务,关注关键神经元组件。
- 识别出安全关键单元(SCU)等四种关键组件,通过冻结或利用冗余单元实现安全对齐。
📝 摘要(中文)
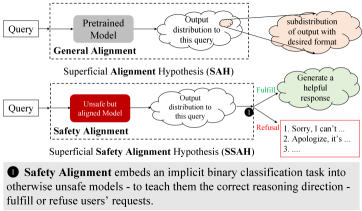
随着大型语言模型(LLMs)日益融入各种应用,确保它们生成安全的回应变得至关重要。以往的对齐研究主要关注通用指令遵循,但往往忽略了安全对齐的独特性质,例如安全机制的脆弱性。为了弥补这一差距,我们提出了浅层安全对齐假设(SSAH),该假设认为安全对齐教会了原本不安全的模型选择正确的推理方向——满足或拒绝用户的请求——这可以被解释为一个隐式的二元分类任务。通过SSAH,我们假设只有少数几个关键组件可以在LLMs中建立安全护栏。我们成功识别了四种类型的属性关键组件:安全关键单元(SCU)、效用关键单元(UCU)、复杂单元(CU)和冗余单元(RU)。我们的研究结果表明,在微调期间冻结某些安全关键组件可以使模型在适应新任务的同时保持其安全属性。类似地,我们表明,利用预训练模型中的冗余单元作为“对齐预算”可以有效地最小化对齐税,同时实现对齐目标。总而言之,本文得出结论,LLMs中安全的原子功能单元位于神经元级别,并强调安全对齐不应复杂化。
🔬 方法详解
问题定义:现有大型语言模型(LLMs)的安全对齐方法通常侧重于通用的指令遵循,而忽略了安全对齐本身的特殊性质,例如安全机制的脆弱性。这意味着即使模型在某些情况下表现出安全性,也可能在其他情况下轻易被绕过,缺乏鲁棒性。此外,现有的对齐方法往往较为复杂,难以理解和控制,导致“对齐税”过高,即为了安全对齐而牺牲了模型的其他能力。
核心思路:本文的核心思路是提出“浅层安全对齐假设”(SSAH),认为安全对齐本质上是一个二元分类任务,即模型需要判断是否应该满足用户的请求。基于此假设,模型只需要学习选择正确的推理方向,而不需要进行复杂的推理过程。作者认为,LLM的安全属性是由少数几个关键的神经元组件控制的,通过识别和操作这些组件,可以有效地实现安全对齐。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 提出浅层安全对齐假设(SSAH);2) 设计实验来验证SSAH,并识别出四种类型的属性关键组件:安全关键单元(SCU)、效用关键单元(UCU)、复杂单元(CU)和冗余单元(RU);3) 通过冻结SCU或利用RU来优化安全对齐过程,减少对齐税。
关键创新:该研究最重要的技术创新点在于提出了浅层安全对齐假设(SSAH),将安全对齐简化为一个二元分类任务,并强调了关键神经元组件的重要性。这与以往关注复杂推理过程的安全对齐方法形成了鲜明对比。此外,该研究还成功识别出四种类型的属性关键组件,为理解和控制LLM的安全行为提供了新的视角。
关键设计:该研究的关键设计包括:1) 设计实验来识别不同类型的属性关键组件,例如通过分析神经元的激活模式来判断其是否与安全相关;2) 通过冻结SCU来保持模型的安全属性,同时允许模型适应新的任务;3) 利用预训练模型中的RU作为“对齐预算”,减少对齐过程对模型性能的影响。具体的参数设置和网络结构细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该研究成功识别出四种类型的属性关键组件(SCU、UCU、CU、RU),并证明了通过冻结安全关键单元(SCU)可以在微调过程中保持模型的安全属性。此外,研究还表明,利用预训练模型中的冗余单元(RU)可以有效减少安全对齐带来的性能损失,即“对齐税”。具体的性能提升数据和对比基线在摘要中未提供,属于未知信息。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,减少有害内容的生成。通过识别和控制关键神经元组件,可以更有效地构建安全护栏,防止模型被恶意利用。此外,该研究还可以帮助降低安全对齐的成本,减少对模型性能的影响,使其在安全的前提下更好地服务于各种应用场景。
📄 摘要(原文)
As large language models (LLMs) are overwhelmingly more and more integrated into various applications, ensuring they generate safe responses is a pressing need. Previous studies on alignment have largely focused on general instruction-following but have often overlooked the distinct properties of safety alignment, such as the brittleness of safety mechanisms. To bridge the gap, we propose the Superficial Safety Alignment Hypothesis (SSAH), which posits that safety alignment teaches an otherwise unsafe model to choose the correct reasoning direction - fulfill or refuse users' requests - interpreted as an implicit binary classification task. Through SSAH, we hypothesize that only a few essential components can establish safety guardrails in LLMs. We successfully identify four types of attribute-critical components: Safety Critical Unit (SCU), Utility Critical Unit (UCU), Complex Unit (CU), and Redundant Unit (RU). Our findings show that freezing certain safety-critical components during fine-tuning allows the model to retain its safety attributes while adapting to new tasks. Similarly, we show that leveraging redundant units in the pre-trained model as an "alignment budget" can effectively minimize the alignment tax while achieving the alignment goal. All considered, this paper concludes that the atomic functional unit for safety in LLMs is at the neuron level and underscores that safety alignment should not be complicated.