Rational Metareasoning for Large Language Models
作者: C. Nicolò De Sabbata, Theodore R. Sumers, Badr AlKhamissi, Antoine Bosselut, Thomas L. Griffiths
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-07 (更新: 2025-06-23)
💡 一句话要点
提出基于元推理的LLM优化方法,降低推理成本并保持性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 元推理 推理成本 专家迭代 价值计算
📋 核心要点
- 大型语言模型推理成本日益增加,如何优化推理的成本-性能权衡是核心问题。
- 论文核心思想是训练LLM仅在必要时才使用中间推理步骤,基于元推理的计算模型。
- 实验结果表明,该方法在降低推理成本的同时,保持了任务性能,优于现有方法。
📝 摘要(中文)
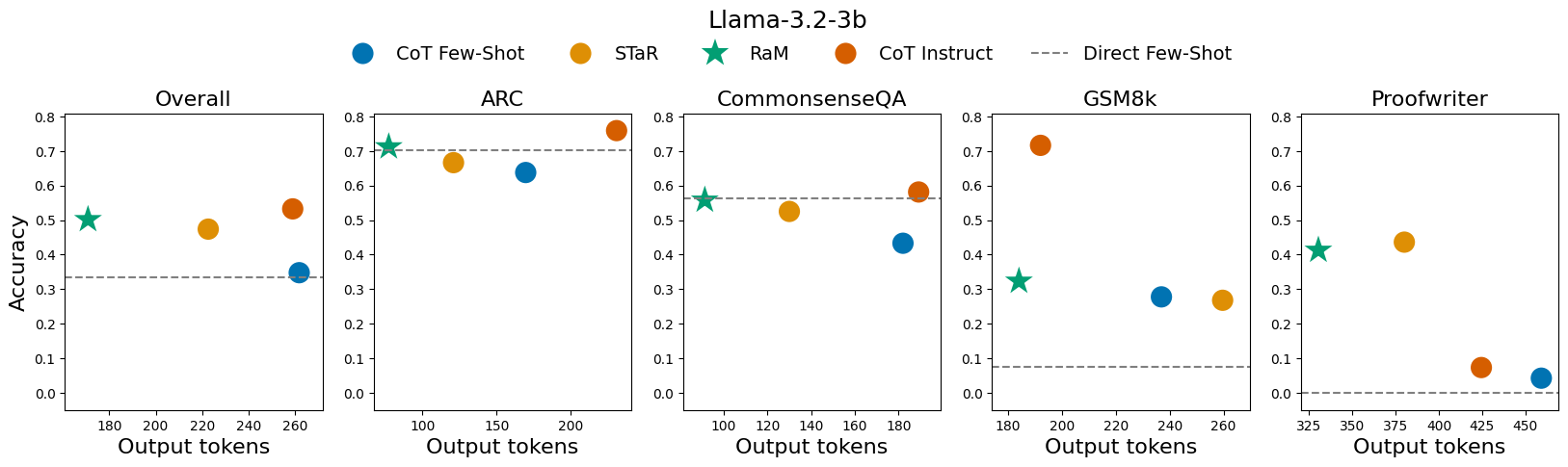
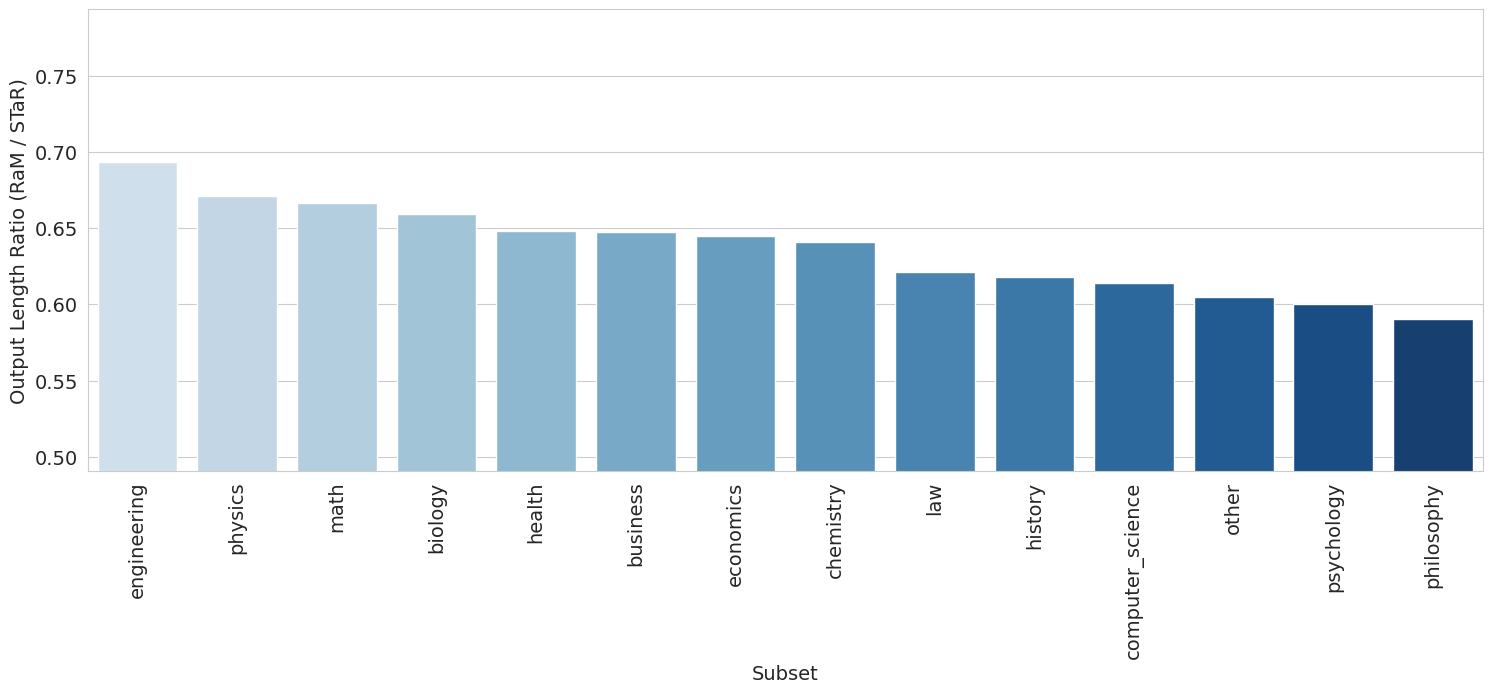
本文提出了一种新颖的方法,基于认知科学中元推理的计算模型,训练大型语言模型(LLM)仅在必要时才选择性地使用中间推理步骤,从而优化推理的成本-性能权衡。首先,开发了一个奖励函数,通过惩罚不必要的推理来结合计算价值。然后,将此奖励函数与专家迭代(Expert Iteration)结合使用来训练LLM。与少样本链式思维提示(few-shot chain-of-thought prompting)和STaR相比,该方法显著降低了推理成本(在三个模型中减少了20-37%的tokens生成),同时保持了跨不同数据集的任务性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理成本高昂的问题。随着LLM规模和应用范围的扩大,推理所需的计算资源也显著增加,导致成本负担加重。现有的链式思维(Chain-of-Thought)等方法虽然能提升性能,但同时也增加了推理步骤,进一步推高了成本。因此,如何在保证任务性能的前提下,降低LLM的推理成本,是本文要解决的关键问题。
核心思路:论文的核心思路是借鉴认知科学中的元推理概念,让LLM学会“思考如何思考”,即根据当前任务的难度和自身的能力,动态地决定是否需要进行中间推理步骤。通过这种方式,LLM可以避免不必要的推理,从而降低计算成本。这种方法的核心在于让LLM具备“价值计算”的能力,即评估进行推理的收益与成本,并做出合理的决策。
技术框架:论文采用专家迭代(Expert Iteration)框架来训练LLM。整体流程如下:1) 首先,定义一个奖励函数,该函数综合考虑任务的完成情况和推理成本。具体来说,如果LLM在没有进行中间推理的情况下就能完成任务,则给予更高的奖励;如果LLM进行了不必要的推理,则给予惩罚。2) 然后,使用该奖励函数来训练LLM,使其学会根据任务的难度和自身的能力,选择性地使用中间推理步骤。3) 在训练过程中,采用专家迭代的方法,不断地生成新的“专家”策略,并将其与LLM的策略进行混合,从而提高LLM的性能。
关键创新:论文最重要的技术创新点在于将元推理的概念引入到LLM的训练中,并设计了一个能够有效衡量推理价值的奖励函数。与传统的链式思维等方法不同,该方法不是强制LLM进行固定的推理步骤,而是让LLM根据实际情况动态地调整推理过程。这种方法能够更好地平衡推理的成本和性能,从而提高LLM的效率。
关键设计:奖励函数的设计是关键。论文中,奖励函数包含两部分:任务奖励和推理惩罚。任务奖励根据LLM是否正确完成任务来确定,推理惩罚则根据LLM使用的tokens数量来确定。具体来说,如果LLM在没有进行中间推理的情况下就能完成任务,则任务奖励较高,推理惩罚较低;如果LLM需要进行中间推理才能完成任务,则任务奖励较低,推理惩罚较高。通过调整任务奖励和推理惩罚的权重,可以控制LLM的推理策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在三个不同的LLM模型上,相对于少样本链式思维提示和STaR,显著降低了推理成本(减少了20-37%的tokens生成),同时保持了跨不同数据集的任务性能。这表明该方法能够有效地平衡推理的成本和性能,具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于各种需要使用大型语言模型的场景,尤其是在计算资源有限或对推理延迟有较高要求的场景下。例如,在移动设备上运行LLM、在边缘计算环境中进行推理、以及在需要快速响应的实时应用中,该方法都能有效降低推理成本,提高效率。此外,该研究也为未来开发更智能、更高效的LLM提供了新的思路。
📄 摘要(原文)
Being prompted to engage in reasoning has emerged as a core technique for using large language models (LLMs), deploying additional inference-time compute to improve task performance. However, as LLMs increase in both size and adoption, inference costs are correspondingly becoming increasingly burdensome. How, then, might we optimize reasoning's cost-performance tradeoff? This work introduces a novel approach based on computational models of metareasoning used in cognitive science, training LLMs to selectively use intermediate reasoning steps only when necessary. We first develop a reward function that incorporates the Value of Computation by penalizing unnecessary reasoning, then use this reward function with Expert Iteration to train the LLM. Compared to few-shot chain-of-thought prompting and STaR, our method significantly reduces inference costs (20-37\% fewer tokens generated across three models) while maintaining task performance across diverse datasets.