Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification
作者: Tao Meng, Ninareh Mehrabi, Palash Goyal, Anil Ramakrishna, Aram Galstyan, Richard Zemel, Kai-Wei Chang, Rahul Gupta, Charith Peris
分类: cs.CL
发布日期: 2024-10-07
备注: Accepted to EMNLP Findings
💡 一句话要点
提出基于属性控制的LLM微调框架,以提升模型输出安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 属性控制 微调 约束学习 毒性检测
📋 核心要点
- 现有LLM微调方法难以在保证生成质量的同时,有效控制特定属性(如毒性)。
- 提出一种约束学习方案,通过KL散度正则化LLM训练,并利用辅助模型将序列约束分解为token级别指导。
- 实验表明,该方法能有效降低LLM输出的毒性,并在基准测试中保持竞争力。
📝 摘要(中文)
本文提出了一种用于大型语言模型(LLM)微调的约束学习方案,旨在实现属性控制。给定训练语料库和以序列级别约束形式表达的控制标准,该方法在训练语料库上微调LLM,同时增强约束满足度,并尽量减少对模型效用和生成质量的影响。具体而言,该方法通过惩罚期望输出分布(满足约束)与LLM后验之间的KL散度来正则化LLM训练。该正则化项可以通过训练辅助模型将序列级别约束分解为token级别指导来近似,从而允许通过闭式公式测量该项。为了进一步提高效率,我们设计了一种并行方案,用于并发更新LLM和辅助模型。我们通过控制训练LLM时的毒性来评估我们方法的经验性能。结果表明,我们的方法能够生成更少的不得体回复,并在基准测试和毒性检测任务上实现有竞争力的性能。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在生成文本时,可能产生包含毒性、偏见或不适当内容的回复。直接对LLM进行微调以消除这些不良属性,往往会导致模型效用下降,即在其他任务上的性能降低。因此,如何在微调过程中有效控制LLM的输出属性,同时保持其生成质量,是一个重要的挑战。
核心思路:本文的核心思路是通过约束学习来引导LLM的微调过程。具体来说,将期望的属性控制(例如,降低毒性)表示为序列级别的约束,并在训练过程中惩罚模型输出与满足这些约束的理想输出之间的差异。这种差异通过KL散度来衡量,从而鼓励模型生成更符合约束的文本。
技术框架:该方法包含两个主要模块:LLM和辅助模型。LLM是需要进行微调的目标模型。辅助模型的作用是将序列级别的约束分解为token级别的指导信号。整个训练流程如下:1) LLM生成文本;2) 辅助模型评估文本是否满足约束,并生成token级别的指导信号;3) 使用KL散度正则化LLM的训练,使其输出更接近满足约束的文本;4) 并行更新LLM和辅助模型。
关键创新:该方法最重要的创新点在于使用辅助模型将序列级别的约束分解为token级别的指导信号。这使得可以使用闭式公式来近似计算KL散度正则化项,从而简化了训练过程。此外,并行更新LLM和辅助模型的设计提高了训练效率。
关键设计:关键的设计包括:1) 使用KL散度作为正则化项,惩罚模型输出与期望输出之间的差异;2) 训练辅助模型,将序列级别约束分解为token级别指导;3) 设计并行更新方案,同时优化LLM和辅助模型。辅助模型的具体结构和训练方式需要根据具体的约束类型进行调整。损失函数包括生成损失和KL散度损失两部分,通过调整两者的权重来平衡生成质量和属性控制。
🖼️ 关键图片


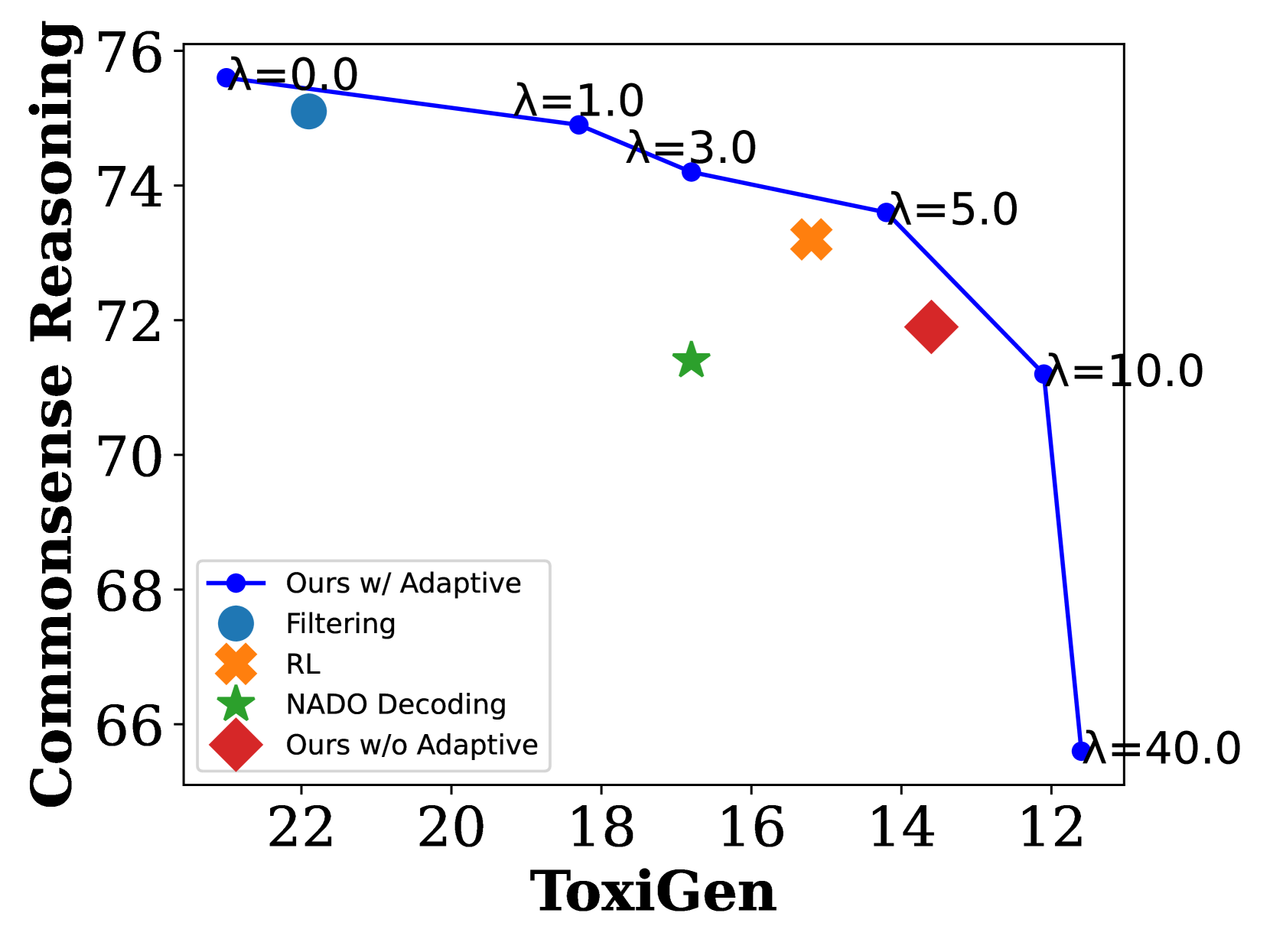
📊 实验亮点
实验结果表明,该方法在降低LLM输出毒性方面取得了显著效果。与直接微调相比,该方法在降低毒性的同时,能够更好地保持模型在其他任务上的性能。在毒性检测任务上,该方法能够显著降低模型输出的毒性评分,并在基准测试中保持竞争力。
🎯 应用场景
该研究成果可应用于各种需要控制LLM输出属性的场景,例如:构建更安全的聊天机器人、生成无偏见的新闻报道、以及开发符合特定道德规范的AI系统。通过属性控制,可以有效降低LLM在实际应用中产生不良影响的风险,提升用户体验。
📄 摘要(原文)
We propose a constraint learning schema for fine-tuning Large Language Models (LLMs) with attribute control. Given a training corpus and control criteria formulated as a sequence-level constraint on model outputs, our method fine-tunes the LLM on the training corpus while enhancing constraint satisfaction with minimal impact on its utility and generation quality. Specifically, our approach regularizes the LLM training by penalizing the KL divergence between the desired output distribution, which satisfies the constraints, and the LLM's posterior. This regularization term can be approximated by an auxiliary model trained to decompose the sequence-level constraints into token-level guidance, allowing the term to be measured by a closed-form formulation. To further improve efficiency, we design a parallel scheme for concurrently updating both the LLM and the auxiliary model. We evaluate the empirical performance of our approach by controlling the toxicity when training an LLM. We show that our approach leads to an LLM that produces fewer inappropriate responses while achieving competitive performance on benchmarks and a toxicity detection task.