SFTMix: Elevating Language Model Instruction Tuning with Mixup Recipe
作者: Yuxin Xiao, Shujian Zhang, Wenxuan Zhou, Marzyeh Ghassemi, Sanqiang Zhao
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-07 (更新: 2025-10-16)
💡 一句话要点
SFTMix:利用Mixup提升语言模型指令微调效果,无需高质量数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 大型语言模型 Mixup 数据增强 泛化能力 置信度 训练动态
📋 核心要点
- 现有指令微调方法依赖高质量数据集,通常需要昂贵的标注或专有LLM过滤,成本高昂。
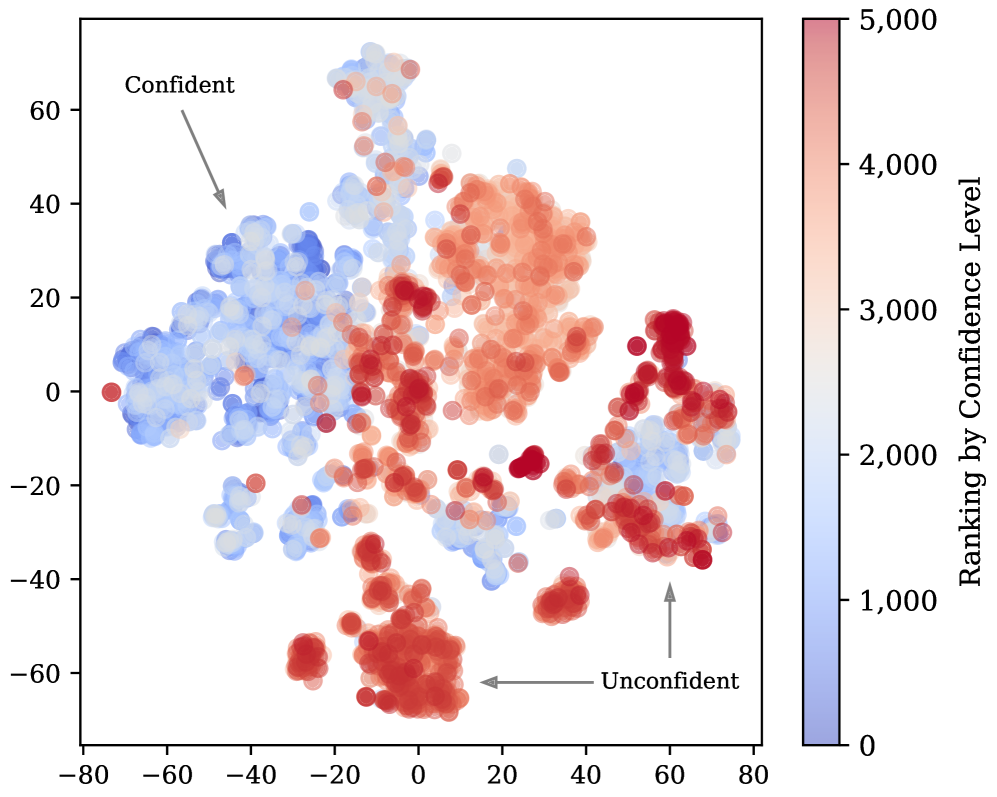
- SFTMix通过Mixup方法,在训练过程中识别并混合不同置信度的样本,弥补置信度差距,提升泛化能力。
- 实验表明,SFTMix在多种LLM和SFT数据集上均有效,且与数据选择兼容,适应计算受限场景。
📝 摘要(中文)
为了获得指令遵循能力,大型语言模型(LLM)通常会进行指令微调,即使用指令-响应对,通过预测下一个token进行训练。改进指令微调的方法通常侧重于更高质量的监督微调(SFT)数据集,这通常需要使用专有LLM或人工标注进行数据过滤。本文提出了一种不同的方法,即SFTMix,一种基于Mixup的新型配方,可以在不依赖精心策划的数据集的情况下提升LLM指令微调的效果。我们观察到LLM在语义表示空间中表现出不均匀的置信度。我们认为,具有不同置信度水平的样本在指令微调中应发挥不同的作用:高置信度的数据容易过拟合,而低置信度的数据则难以泛化。基于此,SFTMix利用训练动态来识别具有不同置信度水平的样本,然后对它们进行插值以弥合置信度差距,并应用基于Mixup的正则化来支持对这些额外的插值样本的学习。我们证明了SFTMix在指令遵循和医疗保健特定SFT任务中的有效性,并在LLM系列和不同大小和质量的SFT数据集中都取得了持续的改进。对六个方向的广泛分析突出了SFTMix与数据选择的兼容性、对计算受限场景的适应性以及对更广泛应用的可扩展性。
🔬 方法详解
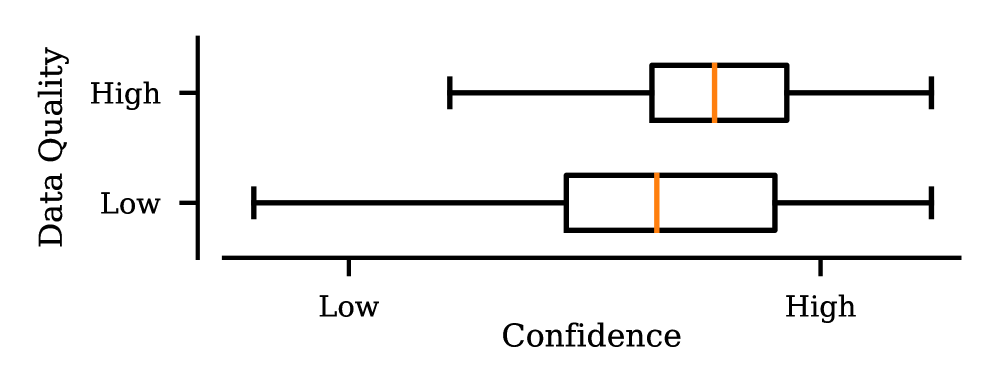
问题定义:论文旨在解决大型语言模型指令微调过程中,对高质量数据集的依赖问题。现有方法通常需要人工标注或使用大型模型进行数据过滤,成本高昂且效率低下。此外,模型在训练过程中容易对高置信度样本过拟合,而对低置信度样本学习不足,导致泛化能力受限。
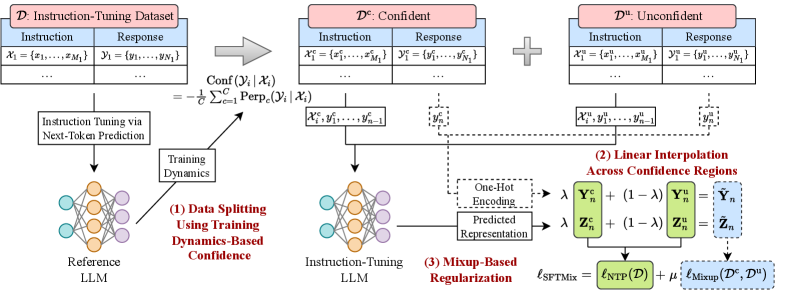
核心思路:论文的核心思路是利用Mixup方法,在训练过程中动态地识别并混合具有不同置信度水平的样本。通过对这些样本进行插值,可以有效地弥合置信度差距,并生成新的训练样本,从而提高模型的泛化能力。这种方法无需额外的数据标注或过滤,降低了训练成本。
技术框架:SFTMix的整体框架包括以下几个主要步骤:1) 在训练过程中,计算每个样本的置信度得分,例如使用交叉熵损失或预测概率。2) 根据置信度得分,选择具有不同置信度水平的样本对。3) 对选定的样本对进行线性插值,生成新的混合样本。4) 使用混合样本和原始样本一起进行训练,并应用Mixup正则化。
关键创新:SFTMix的关键创新在于它利用训练动态来识别具有不同置信度水平的样本,并使用Mixup方法对这些样本进行混合。这种方法能够有效地利用现有的训练数据,而无需额外的数据标注或过滤。此外,SFTMix还能够提高模型的泛化能力,使其在未见过的指令上表现更好。
关键设计:SFTMix的关键设计包括:1) 置信度得分的计算方法,可以选择交叉熵损失或预测概率等。2) 样本对的选择策略,可以选择随机选择或根据置信度差异进行选择。3) 插值系数的选择,通常使用均匀分布或Beta分布进行采样。4) Mixup正则化的强度,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SFTMix在指令遵循和医疗保健特定SFT任务中均取得了显著的改进。在多个LLM系列和不同大小、质量的SFT数据集上,SFTMix均表现出一致的性能提升。例如,在某些任务上,SFTMix可以将模型的准确率提高5%以上,且与数据选择方法兼容,进一步提升了性能。
🎯 应用场景
SFTMix可广泛应用于各种需要指令微调的大型语言模型,尤其是在数据资源有限或获取高质量标注数据成本较高的场景下。例如,在医疗、金融等专业领域,可以利用SFTMix提升模型在特定任务上的性能,降低对专业标注数据的依赖,加速模型落地。
📄 摘要(原文)
To acquire instruction-following capabilities, large language models (LLMs) undergo instruction tuning, where they are trained on instruction-response pairs using next-token prediction (NTP). Efforts to improve instruction tuning often focus on higher-quality supervised fine-tuning (SFT) datasets, typically requiring data filtering with proprietary LLMs or human annotation. In this paper, we take a different approach by proposing SFTMix, a novel Mixup-based recipe that elevates LLM instruction tuning without relying on well-curated datasets. We observe that LLMs exhibit uneven confidence across the semantic representation space. We argue that examples with different confidence levels should play distinct roles in instruction tuning: Confident data is prone to overfitting, while unconfident data is harder to generalize. Based on this insight, SFTMix leverages training dynamics to identify examples with varying confidence levels. We then interpolate them to bridge the confidence gap and apply a Mixup-based regularization to support learning on these additional, interpolated examples. We demonstrate the effectiveness of SFTMix in both instruction-following and healthcare-specific SFT tasks, with consistent improvements across LLM families and SFT datasets of varying sizes and qualities. Extensive analyses across six directions highlight SFTMix's compatibility with data selection, adaptability to compute-constrained scenarios, and scalability to broader applications.