Cookbook: A framework for improving LLM generative abilities via programmatic data generating templates
作者: Avanika Narayan, Mayee F. Chen, Kush Bhatia, Christopher Ré
分类: cs.CL, cs.LG
发布日期: 2024-10-07
备注: COLM 2024
💡 一句话要点
Cookbook:通过程序化数据生成模板提升LLM生成能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据生成 程序化生成 指令调优 多任务学习
📋 核心要点
- 现有指令数据集构建成本高昂,且LLM生成数据存在隐私和法律风险,限制了LLM生成能力的提升。
- Cookbook框架通过程序化生成训练数据,利用简单模式和随机token,避免了人工标注和LLM生成数据的局限性。
- 实验表明,Cookbook能显著提升LLM在特定任务和多任务上的性能,并在GPT4ALL评估中取得领先成果。
📝 摘要(中文)
本文提出Cookbook框架,旨在通过程序化生成训练数据来提升大型语言模型(LLM)的生成能力。手动创建指令数据集成本高、耗时,而LLM生成的数据可能侵犯用户隐私或违反服务条款。Cookbook利用数据生成Python函数(模板)生成包含随机token简单模式的训练数据,从而实现可扩展、低成本且避免法律和隐私问题的训练方法。实验表明,在Cookbook生成的数据集上进行微调,能够将模型在相应任务上的准确率提高高达52.7个百分点。此外,Cookbook还能算法式地混合来自不同模板的数据,以优化多个任务的性能。在GPT4ALL多任务评估套件上,使用Cookbook生成的数据集微调的Mistral-7B模型,其平均准确率优于其他7B参数的指令调优模型,并在8个任务中的3个任务上表现最佳。最后,论文分析了Cookbook提升性能的原因,并提出了一个指标来验证性能提升主要归功于模型生成结果更好地遵循模板规则。
🔬 方法详解
问题定义:现有指令数据集的构建面临成本高、耗时以及潜在的隐私和法律风险。手动标注数据需要大量人力,而直接使用LLM生成数据可能违反用户协议或泄露隐私信息。因此,需要一种既能有效提升LLM生成能力,又能避免上述问题的数据生成方法。
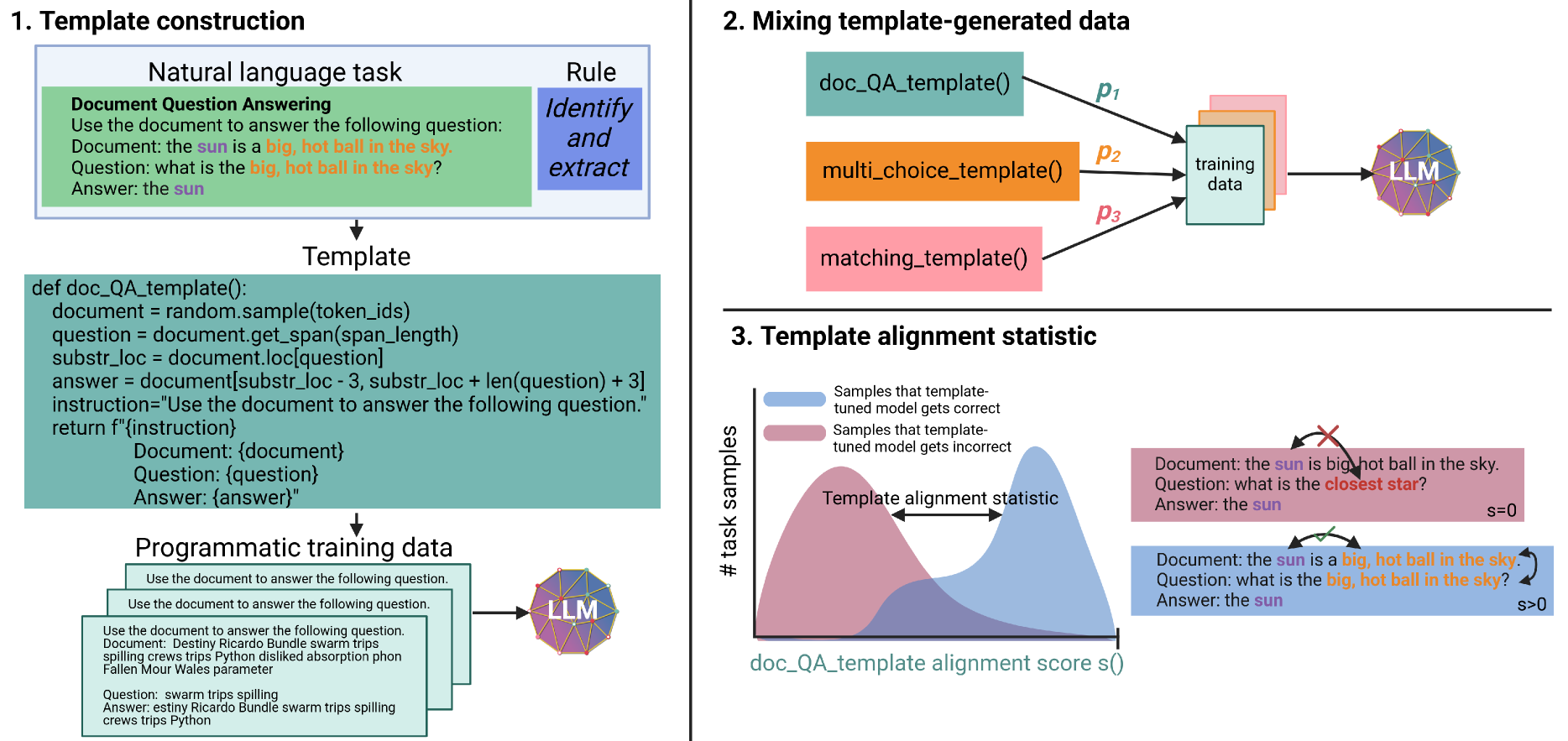
核心思路:Cookbook的核心思路是利用程序化的数据生成模板,自动创建包含特定模式的训练数据。这些模板使用随机token,并遵循预定义的规则,从而生成既具有一定结构性,又避免了直接使用人类或LLM生成数据的风险。通过在这些数据上进行微调,LLM能够学习到这些模式,从而提升其生成能力。
技术框架:Cookbook框架主要包含以下几个步骤:1) 定义数据生成模板:使用Python函数编写模板,指定数据的模式和规则。2) 生成训练数据:利用模板生成大量的训练样本。3) 模型微调:在生成的训练数据上对LLM进行微调。4) 多任务优化:使用算法自动混合来自不同模板的数据,以优化多个任务的性能。5) 性能评估:使用标准数据集评估微调后的模型性能。
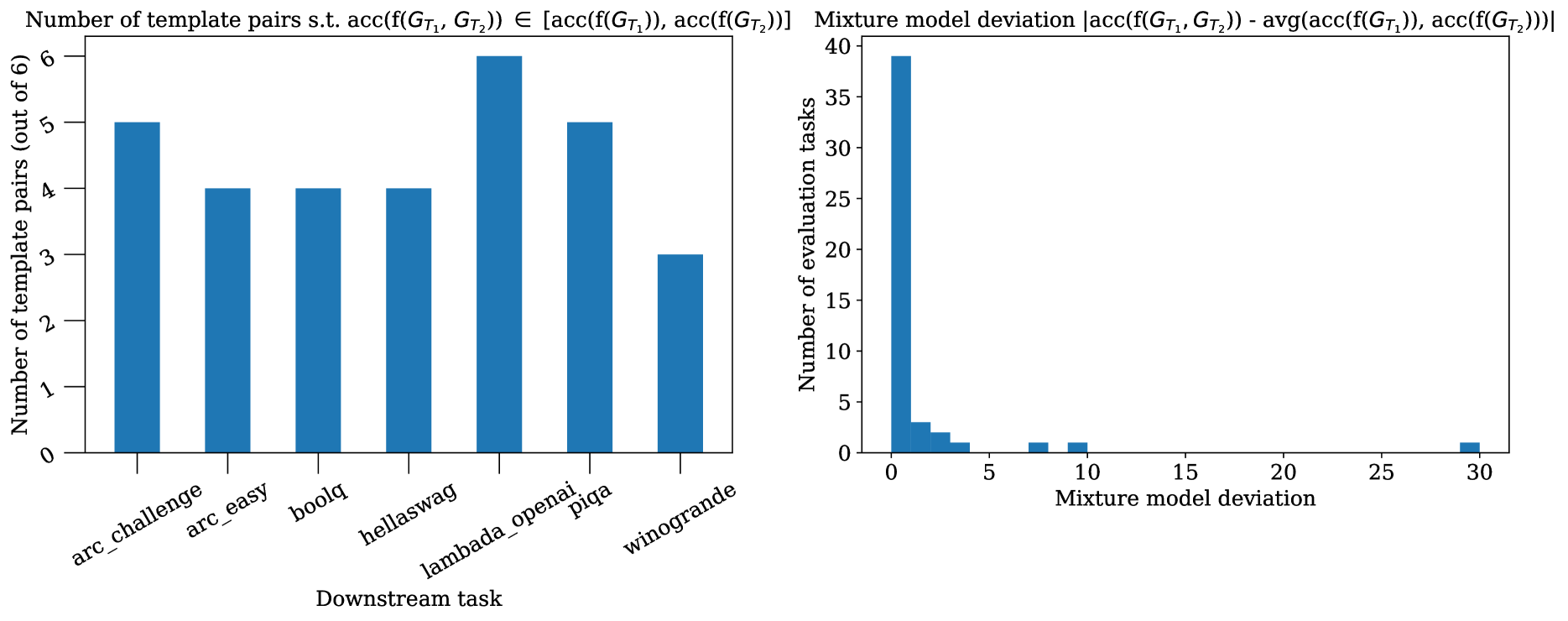
关键创新:Cookbook的关键创新在于其程序化的数据生成方法。与传统的手动标注或LLM生成数据相比,Cookbook能够以更低的成本和更高的效率生成大量的训练数据,并且避免了隐私和法律风险。此外,Cookbook还能够自动优化多任务学习的数据混合比例,从而进一步提升模型性能。
关键设计:Cookbook的关键设计包括:1) 数据生成模板的设计:模板需要能够生成具有一定结构性和多样性的数据,以促进LLM的学习。2) 多任务数据混合算法:该算法需要能够根据不同任务的性能,自动调整来自不同模板的数据混合比例,以实现最佳的整体性能。3) 性能评估指标:论文提出了一个指标来验证性能提升是否主要归功于模型生成结果更好地遵循模板规则。
🖼️ 关键图片

📊 实验亮点
Cookbook在多个实验中表现出色。在特定任务上,使用Cookbook生成的数据集进行微调,能够将模型准确率提高高达52.7个百分点。在GPT4ALL多任务评估套件上,使用Cookbook生成的数据集微调的Mistral-7B模型,其平均准确率优于其他7B参数的指令调优模型,并在8个任务中的3个任务上表现最佳。
🎯 应用场景
Cookbook框架可应用于各种需要提升LLM生成能力的场景,例如代码生成、文本摘要、机器翻译等。它尤其适用于数据获取受限或存在隐私风险的领域。该框架能够降低数据标注成本,加速LLM的开发和部署,并促进LLM在更多领域的应用。
📄 摘要(原文)
Fine-tuning large language models (LLMs) on instruction datasets is a common way to improve their generative capabilities. However, instruction datasets can be expensive and time-consuming to manually curate, and while LLM-generated data is less labor-intensive, it may violate user privacy agreements or terms of service of LLM providers. Therefore, we seek a way of constructing instruction datasets with samples that are not generated by humans or LLMs but still improve LLM generative capabilities. In this work, we introduce Cookbook, a framework that programmatically generates training data consisting of simple patterns over random tokens, resulting in a scalable, cost-effective approach that avoids legal and privacy issues. First, Cookbook uses a template -- a data generating Python function -- to produce training data that encourages the model to learn an explicit pattern-based rule that corresponds to a desired task. We find that fine-tuning on Cookbook-generated data is able to improve performance on its corresponding task by up to 52.7 accuracy points. Second, since instruction datasets improve performance on multiple downstream tasks simultaneously, Cookbook algorithmically learns how to mix data from various templates to optimize performance on multiple tasks. On the standard multi-task GPT4ALL evaluation suite, Mistral-7B fine-tuned using a Cookbook-generated dataset attains the best accuracy on average compared to other 7B parameter instruction-tuned models and is the best performing model on 3 out of 8 tasks. Finally, we analyze when and why Cookbook improves performance and present a metric that allows us to verify that the improvement is largely explained by the model's generations adhering better to template rules.