Efficient Inference for Large Language Model-based Generative Recommendation
作者: Xinyu Lin, Chaoqun Yang, Wenjie Wang, Yongqi Li, Cunxiao Du, Fuli Feng, See-Kiong Ng, Tat-Seng Chua
分类: cs.IR, cs.CL
发布日期: 2024-10-07 (更新: 2025-02-26)
备注: Accepted by ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出AtSpeed框架,加速基于大语言模型的生成式推荐系统推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式推荐 大语言模型 推测解码 模型加速 top-K推荐
📋 核心要点
- 基于LLM的生成式推荐推理速度慢,自回归解码带来高延迟,严重制约了实际应用。
- AtSpeed框架通过提升draft模型与目标LLM的top-K序列对齐,并放宽验证策略,减少LLM调用。
- 实验表明,AtSpeed在严格top-K验证下加速近2倍,宽松采样验证下加速高达2.5倍。
📝 摘要(中文)
基于大语言模型的生成式推荐取得了显著成功,但其部署成本高昂,特别是自回归解码导致的推理延迟过高。推测解码(SD)是一种有前景的无损LLM解码加速方案。然而,将SD应用于生成式推荐面临独特的挑战,因为需要通过束搜索生成top-K个项目(即K个不同的token序列)作为推荐列表。这导致SD中更严格的验证,即目标LLM的所有top-K序列必须在每个解码步骤中都被draft模型成功draft。为了缓解这个问题,我们考虑1) 提升draft模型和目标LLM之间的top-K序列对齐,以及2) 放宽验证策略以减少不必要的LLM调用。为此,我们提出了一个名为AtSpeed的对齐框架,该框架提出了AtSpeed-S优化目标,用于在严格的top-K验证下进行top-K对齐。此外,我们引入了一种宽松的采样验证策略,允许接受高概率的非top-K drafted序列,从而显著减少LLM调用。相应地,我们提出了AtSpeed-R,用于在这种宽松的采样验证下进行top-K对齐。在两个真实世界数据集上的实验结果表明,AtSpeed显著加速了基于LLM的生成式推荐,例如,在严格的top-K验证下接近2倍的加速,在宽松的采样验证下高达2.5倍的加速。代码和数据集已发布。
🔬 方法详解
问题定义:论文旨在解决基于大语言模型的生成式推荐系统中,由于自回归解码导致的推理速度慢的问题。现有方法,特别是直接应用推测解码(Speculative Decoding, SD),在生成top-K推荐列表时面临严格的验证要求,导致效率提升有限。痛点在于需要保证draft模型生成的top-K序列与目标LLM的top-K序列完全一致,否则需要调用耗时的目标LLM进行验证。
核心思路:论文的核心思路是通过优化draft模型,使其生成的序列更接近目标LLM的top-K序列,从而减少目标LLM的调用次数。此外,通过放宽验证策略,允许接受draft模型生成的高概率但非top-K序列,进一步降低LLM的调用频率。这样可以在保证推荐质量的前提下,显著提升推理速度。
技术框架:AtSpeed框架包含两个主要变体:AtSpeed-S和AtSpeed-R。AtSpeed-S采用严格的top-K验证,优化目标是提升draft模型与目标LLM在top-K序列上的对齐程度。AtSpeed-R则采用宽松的采样验证策略,允许接受高概率的非top-K序列。整体流程包括:首先使用draft模型生成候选序列,然后根据验证策略决定是否接受该序列,如果被拒绝,则调用目标LLM进行修正。
关键创新:论文的关键创新在于提出了AtSpeed框架,该框架通过以下两点显著提升了生成式推荐的推理速度:1) 提出了AtSpeed-S优化目标,用于在严格的top-K验证下提升draft模型与目标LLM的top-K序列对齐程度;2) 引入了宽松的采样验证策略,允许接受高概率的非top-K序列,从而减少了对目标LLM的调用。
关键设计:AtSpeed-S的关键设计在于其优化目标,该目标旨在最小化draft模型生成的top-K序列与目标LLM生成的top-K序列之间的差异。AtSpeed-R的关键设计在于其宽松的采样验证策略,该策略基于序列的概率分布,允许接受一定概率范围内的非top-K序列。具体的概率阈值需要根据实验进行调整,以平衡推理速度和推荐质量。
🖼️ 关键图片


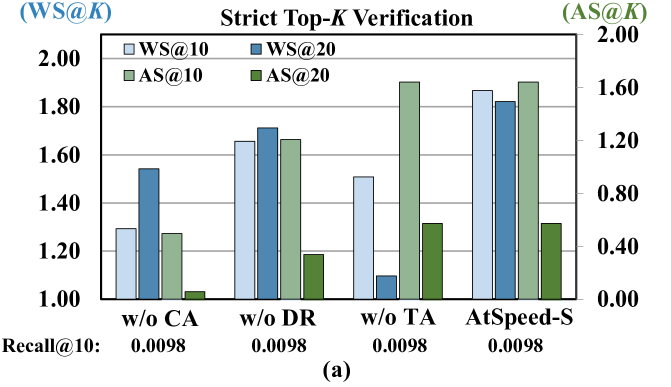
📊 实验亮点
实验结果表明,AtSpeed在两个真实世界数据集上显著加速了基于LLM的生成式推荐。在严格的top-K验证下,AtSpeed实现了接近2倍的加速。在宽松的采样验证下,AtSpeed实现了高达2.5倍的加速。这些结果表明,AtSpeed是一种有效的LLM推理加速方法,可以显著提升生成式推荐系统的性能。
🎯 应用场景
该研究成果可应用于各种需要快速生成推荐列表的场景,例如电商推荐、新闻推荐、视频推荐等。通过降低LLM推理延迟,可以显著提升用户体验,并降低在线服务的运营成本。未来,该方法可以进一步扩展到其他生成式任务中,例如文本摘要、机器翻译等。
📄 摘要(原文)
Large Language Model (LLM)-based generative recommendation has achieved notable success, yet its practical deployment is costly particularly due to excessive inference latency caused by autoregressive decoding. For lossless LLM decoding acceleration, Speculative Decoding (SD) has emerged as a promising solution. However, applying SD to generative recommendation presents unique challenges due to the requirement of generating top-K items (i.e., K distinct token sequences) as a recommendation list by beam search. This leads to more stringent verification in SD, where all the top-K sequences from the target LLM must be successfully drafted by the draft model at each decoding step. To alleviate this, we consider 1) boosting top-K sequence alignment between the draft model and the target LLM, and 2) relaxing the verification strategy to reduce trivial LLM calls. To this end, we propose an alignment framework named AtSpeed, which presents the AtSpeed-S optimization objective for top-K alignment under the strict top-K verification. Moreover, we introduce a relaxed sampling verification strategy that allows high-probability non-top-K drafted sequences to be accepted, significantly reducing LLM calls. Correspondingly, we propose AtSpeed-R for top-K alignment under this relaxed sampling verification. Empirical results on two real-world datasets demonstrate that AtSpeed significantly accelerates LLM-based generative recommendation, e.g., near 2x speedup under strict top-K verification and up to 2.5x speedup under relaxed sampling verification. The codes and datasets are released at https://github.com/Linxyhaha/AtSpeed.