The LLM Effect: Are Humans Truly Using LLMs, or Are They Being Influenced By Them Instead?
作者: Alexander S. Choi, Syeda Sabrina Akter, JP Singh, Antonios Anastasopoulos
分类: cs.CL, cs.HC
发布日期: 2024-10-07
备注: Accepted to EMNLP Main 2024. First two authors contributed equally
💡 一句话要点
研究表明LLM辅助分析虽提速,但可能引入锚定偏差,影响分析深度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人机协作 锚定偏差 用户研究 主题发现 政策分析 效率提升 认知偏差
📋 核心要点
- 现有分析任务耗时费力,依赖人类专家,效率较低,且可能存在主观偏差。
- 该研究探索人机协作模式,将LLM引入主题发现和分配任务,观察其对分析过程的影响。
- 实验表明,LLM能提速任务完成,但也可能引入锚定偏差,影响分析的深度和细致程度。
📝 摘要(中文)
大型语言模型(LLM)在各种分析任务中展现出接近人类水平的能力,促使研究人员利用它们进行耗时费力的分析。然而,它们在政策研究等领域处理高度专业化和开放式任务的能力仍存在疑问。本文通过一项结构化的用户研究,重点关注人机协作,调查了LLM在专业任务中的效率和准确性。该研究分两个阶段进行——主题发现和主题分配——将LLM与专家标注者相结合,以观察LLM建议对通常仅由人类进行的分析的影响。结果表明,LLM生成的主题列表与人类生成的主题列表有显著重叠,但在遗漏特定于文档的主题方面存在轻微问题。然而,LLM建议可能会显著提高任务完成速度,但同时也引入了锚定偏差,可能影响分析的深度和细微差别,从而引发了关于提高效率与有偏分析风险之间权衡的关键问题。
🔬 方法详解
问题定义:论文旨在研究在专业领域(如政策研究)中,使用LLM辅助人类专家进行分析时,LLM的影响。现有方法主要依赖人工分析,效率低且易受主观因素影响。直接使用LLM可能无法保证分析的深度和准确性,因此需要探索人机协作模式,并评估LLM的潜在偏差。
核心思路:核心思路是观察LLM的建议如何影响人类专家的分析过程。通过对比人类独立分析和接受LLM建议后的分析结果,评估LLM的效率提升和潜在偏差。重点关注LLM是否会引入锚定效应,限制人类专家的思考范围。
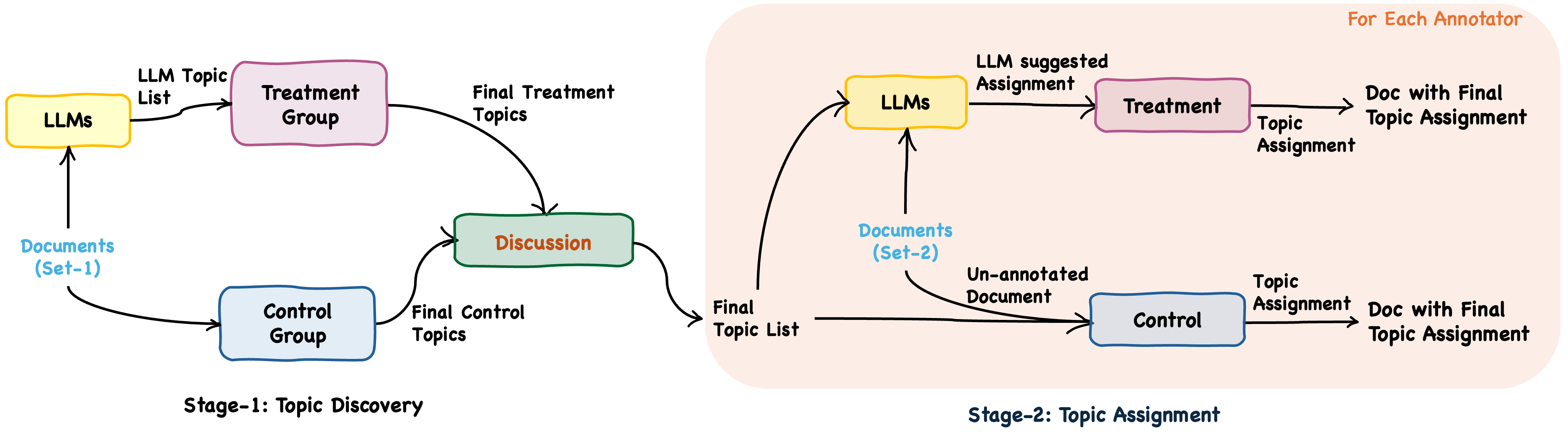
技术框架:研究采用两阶段的用户研究框架:1) 主题发现:人类专家和LLM分别生成主题列表;2) 主题分配:人类专家将文档分配到主题,分别在没有LLM建议和有LLM建议的情况下进行。通过对比两个阶段的结果,分析LLM的影响。研究中使用了特定的LLM模型(具体模型名称未知)作为建议提供者。
关键创新:该研究的创新点在于,它不是简单地评估LLM的性能,而是关注LLM如何影响人类专家的分析过程。通过用户研究,揭示了LLM在提高效率的同时,可能引入锚定偏差的风险,这对于理解人机协作的潜在问题具有重要意义。研究强调了在专业领域应用LLM时,需要谨慎权衡效率和分析质量。
关键设计:研究的关键设计包括:1) 对比实验:设置对照组(无LLM建议)和实验组(有LLM建议),以评估LLM的影响;2) 用户研究:通过招募领域专家参与实验,收集真实的用户反馈;3) 量化分析:使用重叠度指标评估LLM生成的主题列表与人类生成的主题列表的相似性;4) 偏差分析:分析LLM建议是否会影响人类专家对主题的理解和分配。
🖼️ 关键图片

📊 实验亮点
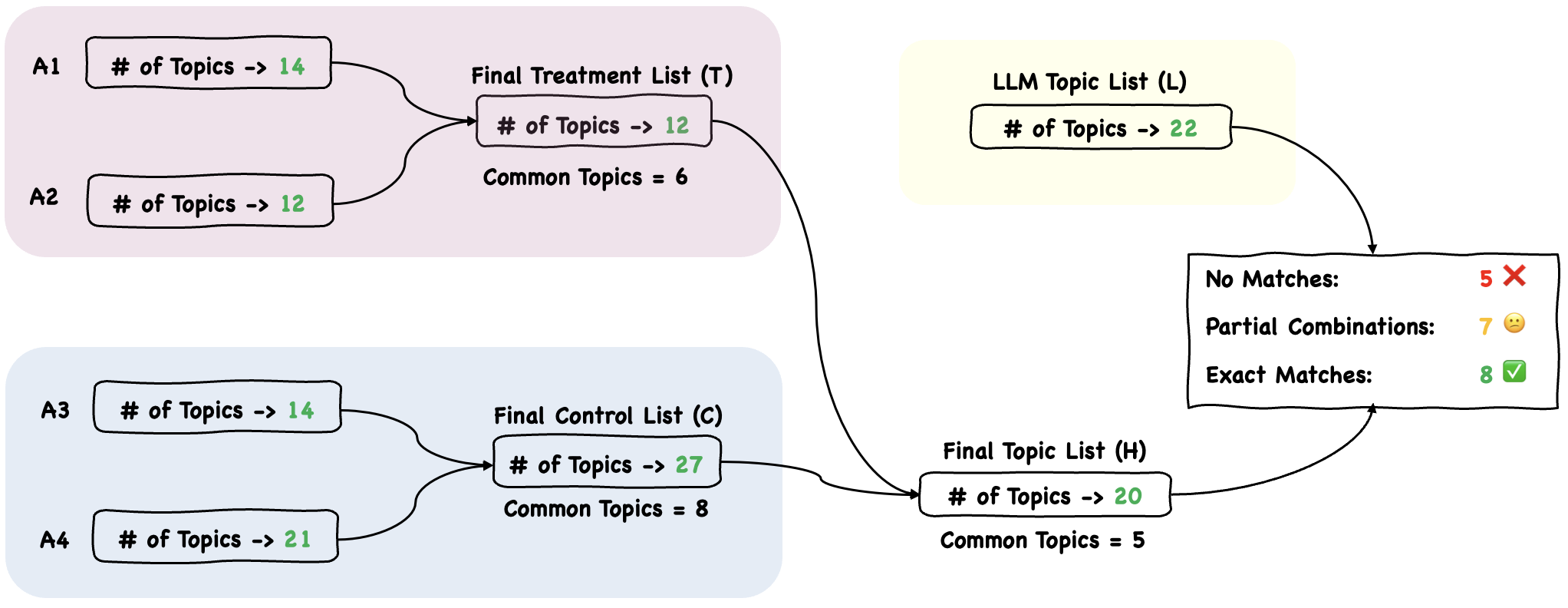
实验结果表明,LLM生成的主题列表与人类生成的主题列表有显著重叠,表明LLM在主题发现方面具有一定的能力。然而,LLM建议虽然能显著提高任务完成速度,但也可能引入锚定偏差,影响分析的深度和细微差别。具体的性能提升数据和偏差影响程度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于政策分析、市场调研、情报分析等领域,帮助相关从业者更好地利用LLM提高工作效率。同时,该研究也提醒人们在使用LLM时需要警惕潜在的锚定偏差,避免过度依赖LLM的建议,从而保证分析的深度和客观性。未来,可以探索更有效的策略来减轻LLM的偏差影响,例如提供多样化的建议或引入批判性思维训练。
📄 摘要(原文)
Large Language Models (LLMs) have shown capabilities close to human performance in various analytical tasks, leading researchers to use them for time and labor-intensive analyses. However, their capability to handle highly specialized and open-ended tasks in domains like policy studies remains in question. This paper investigates the efficiency and accuracy of LLMs in specialized tasks through a structured user study focusing on Human-LLM partnership. The study, conducted in two stages-Topic Discovery and Topic Assignment-integrates LLMs with expert annotators to observe the impact of LLM suggestions on what is usually human-only analysis. Results indicate that LLM-generated topic lists have significant overlap with human generated topic lists, with minor hiccups in missing document-specific topics. However, LLM suggestions may significantly improve task completion speed, but at the same time introduce anchoring bias, potentially affecting the depth and nuance of the analysis, raising a critical question about the trade-off between increased efficiency and the risk of biased analysis.