Debate, Deliberate, Decide (D3): A Cost-Aware Adversarial Framework for Reliable and Interpretable LLM Evaluation
作者: Abir Harrasse, Chaithanya Bandi, Hari Bandi
分类: cs.CL, cs.LG, cs.MA
发布日期: 2024-10-07 (更新: 2026-01-23)
期刊: EACL 2026
💡 一句话要点
提出D3框架,通过多智能体辩论实现可靠、可解释且低成本的大语言模型评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 多智能体系统 对抗性框架 可解释性 成本敏感 辩论 LLM
📋 核心要点
- 现有LLM评估方法存在不一致性、偏差以及缺乏透明决策标准等问题,难以保证评估结果的可靠性。
- D3框架通过构建多智能体辩论环境,利用角色专业化的智能体进行结构化辩论,从而产生更可靠和可解释的评估结果。
- 实验表明,D3在多个数据集上与人类判断具有更好的一致性,并能有效降低评估偏差,同时通过预算停止实现成本效益。
📝 摘要(中文)
本文提出了一种名为Debate, Deliberate, Decide (D3)的成本敏感的对抗性多智能体框架,用于解决大语言模型(LLM)评估中存在的不一致性、偏差以及缺乏透明决策标准的问题。D3通过组织角色专业化的智能体(辩护者、法官和可选的陪审团)进行结构化辩论,从而产生可靠且可解释的评估结果。D3实例化了两种互补的协议:(1) 多辩护者单轮评估(MORE),通过每个答案的k个并行辩护来放大信号;(2) 单辩护者多轮评估(SAMRE),在显式的token预算和收敛性检查下迭代地改进论证。我们开发了一个概率模型来分析得分差距,该模型可以表征迭代辩论下的可靠性和收敛性,并解释并行辩护带来的分离增益。理论分析表明,在温和的假设下,第r轮差距的后验分布集中在真实差异附近,并且错误排序的概率消失;此外,跨k个辩护者进行聚合可以显著提高预期的得分分离。实验结果表明,D3在MT-Bench、AlignBench和AUTO-J等数据集上与人类判断具有最先进的一致性(准确性和Cohen's kappa),并通过匿名化和角色多样化减少了位置和冗余偏差,并通过预算停止实现了良好的成本-准确性平衡。消融研究和定性分析进一步验证了辩论、聚合和匿名化的贡献。这些结果表明,D3是一种可靠、可解释且成本敏感的LLM评估方法。
🔬 方法详解
问题定义:现有的大语言模型(LLM)评估方法存在不一致性、偏差和缺乏透明的决策标准等问题。这些问题导致评估结果难以信赖,并且难以理解LLM做出特定决策的原因。现有的自动化评估方法往往依赖于单一的判断标准,容易受到位置偏差和冗余信息的影响,并且缺乏对评估过程的解释性。
核心思路:D3框架的核心思路是通过模拟人类辩论的过程,利用多个智能体扮演不同的角色(辩护者、法官、陪审团),围绕LLM的输出进行多轮辩论。通过辩论,可以更全面地评估LLM的优缺点,并提供可解释的评估过程。此外,D3还引入了成本意识,通过预算停止机制,在保证评估质量的前提下,降低评估成本。
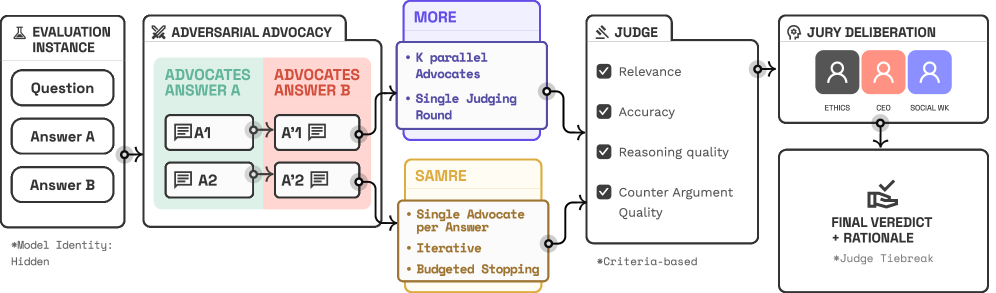
技术框架:D3框架包含以下几个主要模块: 1. 多辩护者单轮评估(MORE):对每个LLM的输出,并行启动多个辩护者,从不同的角度进行辩护,从而放大信号。 2. 单辩护者多轮评估(SAMRE):让单个辩护者与法官进行多轮辩论,逐步完善论证,直到达到预定的token预算或收敛条件。 3. 概率模型:用于分析得分差距,评估辩论的可靠性和收敛性,并解释并行辩护带来的增益。 4. 角色扮演:不同的智能体扮演不同的角色,例如辩护者负责支持LLM的输出,法官负责评估辩论的质量,陪审团(可选)负责提供额外的意见。
关键创新:D3框架的关键创新在于: 1. 多智能体辩论:通过模拟人类辩论的过程,更全面地评估LLM的优缺点,并提供可解释的评估过程。 2. 成本意识:通过预算停止机制,在保证评估质量的前提下,降低评估成本。 3. 概率模型:用于分析辩论的可靠性和收敛性,并提供理论支持。
关键设计: 1. Token预算:SAMRE协议中,为辩论设置了token预算,防止辩论无限进行,从而控制评估成本。 2. 收敛性检查:SAMRE协议中,通过检查得分差距的变化来判断辩论是否收敛,如果收敛,则提前停止辩论。 3. 匿名化:为了减少位置偏差和冗余信息的影响,D3框架对LLM的输出进行了匿名化处理。 4. 角色多样化:不同的智能体扮演不同的角色,从而避免单一视角的偏差。
🖼️ 关键图片

📊 实验亮点
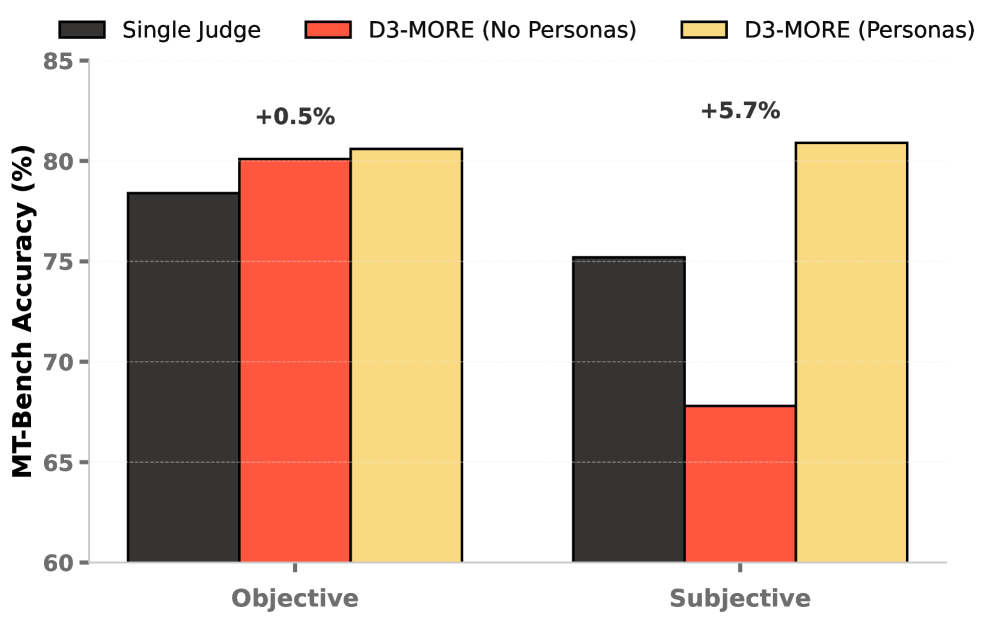
实验结果表明,D3框架在MT-Bench、AlignBench和AUTO-J等数据集上与人类判断具有最先进的一致性(准确性和Cohen's kappa)。通过匿名化和角色多样化,D3有效降低了位置和冗余偏差。此外,D3通过预算停止机制实现了良好的成本-准确性平衡,在保证评估质量的前提下,降低了评估成本。
🎯 应用场景
D3框架可应用于各种需要评估大语言模型的场景,例如模型选择、模型优化、模型安全评估等。该框架能够提供更可靠、可解释且低成本的评估结果,有助于提高LLM的开发和应用效率,并降低潜在风险。未来,D3框架可以扩展到其他类型的AI系统评估中。
📄 摘要(原文)
The evaluation of Large Language Models (LLMs) remains challenging due to inconsistency, bias, and the absence of transparent decision criteria in automated judging. We present Debate, Deliberate, Decide (D3), a cost-aware, adversarial multi-agent framework that orchestrates structured debate among role-specialized agents (advocates, a judge, and an optional jury) to produce reliable and interpretable evaluations. D3 instantiates two complementary protocols: (1) Multi-Advocate One-Round Evaluation (MORE), which elicits k parallel defenses per answer to amplify signal via diverse advocacy, and (2) Single-Advocate Multi-Round Evaluation (SAMRE) with budgeted stopping, which iteratively refines arguments under an explicit token budget and convergence checks. We develop a probabilistic model of score gaps that (i) characterizes reliability and convergence under iterative debate and (ii) explains the separation gains from parallel advocacy. Under mild assumptions, the posterior distribution of the round-r gap concentrates around the true difference and the probability of mis-ranking vanishes; moreover, aggregating across k advocates provably increases expected score separation. We complement theory with a rigorous experimental suite across MT-Bench, AlignBench, and AUTO-J, showing state-of-the-art agreement with human judgments (accuracy and Cohen's kappa), reduced positional and verbosity biases via anonymization and role diversification, and a favorable cost-accuracy frontier enabled by budgeted stopping. Ablations and qualitative analyses isolate the contributions of debate, aggregation, and anonymity. Together, these results establish D3 as a principled, practical recipe for reliable, interpretable, and cost-aware LLM evaluation.