Diagnosing Robotics Systems Issues with Large Language Models
作者: Jordis Emilia Herrmann, Aswath Mandakath Gopinath, Mikael Norrlof, Mark Niklas Müller
分类: cs.CL, cs.AI, cs.LG, cs.RO
发布日期: 2024-10-06
💡 一句话要点
利用大语言模型诊断机器人系统问题,实现高效根因分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人系统诊断 大型语言模型 根因分析 QLoRA微调 系统日志分析
📋 核心要点
- 工业机器人系统问题诊断耗时且依赖专家,现有方法难以快速定位根本原因。
- 利用大语言模型分析机器人系统日志,通过微调实现高效的根因分析。
- 实验表明,QLoRA微调的7B模型优于GPT-4,且成本更低,人工评估结果与参考标签相似。
📝 摘要(中文)
快速解决工业应用中报告的问题对于最小化经济影响至关重要。然而,所需的数据分析使得诊断根本原因成为一项具有挑战性和耗时的任务,即使对于专家来说也是如此。相比之下,大型语言模型(LLM)擅长分析大量数据。事实上,AI-Ops 领域的先前工作证明了它们在分析 IT 系统方面的有效性。在这里,我们将这项工作扩展到具有挑战性且很大程度上未被探索的机器人系统领域。为此,我们创建了 SYSDIAGBENCH,这是一个用于机器人技术的专有系统诊断基准,包含超过 2500 个报告的问题。我们利用 SYSDIAGBENCH 来研究 LLM 在根本原因分析中的性能,考虑了一系列模型大小和自适应技术。我们的结果表明,QLoRA 微调足以让一个 7B 参数的模型在诊断准确性方面优于 GPT-4,同时更具成本效益。我们通过人工专家研究验证了我们的 LLM-as-a-judge 结果,发现我们最好的模型获得了与我们的参考标签相似的批准率。
🔬 方法详解
问题定义:论文旨在解决机器人系统故障诊断中,人工分析耗时且成本高昂的问题。现有方法依赖专家经验,难以快速准确地定位根本原因,尤其是在面对大量系统日志和复杂故障模式时。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的数据分析和推理能力,将机器人系统故障诊断问题转化为一个文本理解和推理任务。通过训练LLM理解系统日志、错误报告等信息,从而自动识别故障的根本原因。
技术框架:论文构建了一个名为SYSDIAGBENCH的机器人系统诊断基准数据集,包含超过2500个已报告的问题。然后,研究者使用该数据集对不同大小的LLM进行微调,并评估其在根因分析任务上的性能。具体流程包括:数据预处理、模型选择、微调训练、性能评估和人工验证。
关键创新:论文的关键创新在于将LLM应用于机器人系统故障诊断领域,并证明了其有效性。此外,论文还发现,通过QLoRA(Quantization-aware Low-Rank Adaptation)等高效微调技术,可以使用较小的模型(7B参数)达到甚至超过大型模型(如GPT-4)的性能,从而降低计算成本。
关键设计:论文使用了QLoRA进行模型微调,这是一种参数高效的微调方法,可以在保持模型性能的同时显著减少训练所需的计算资源。此外,论文还采用了LLM-as-a-judge的方法,即使用LLM来评估其他模型的输出,并使用人工专家评估来验证LLM评估的可靠性。
🖼️ 关键图片
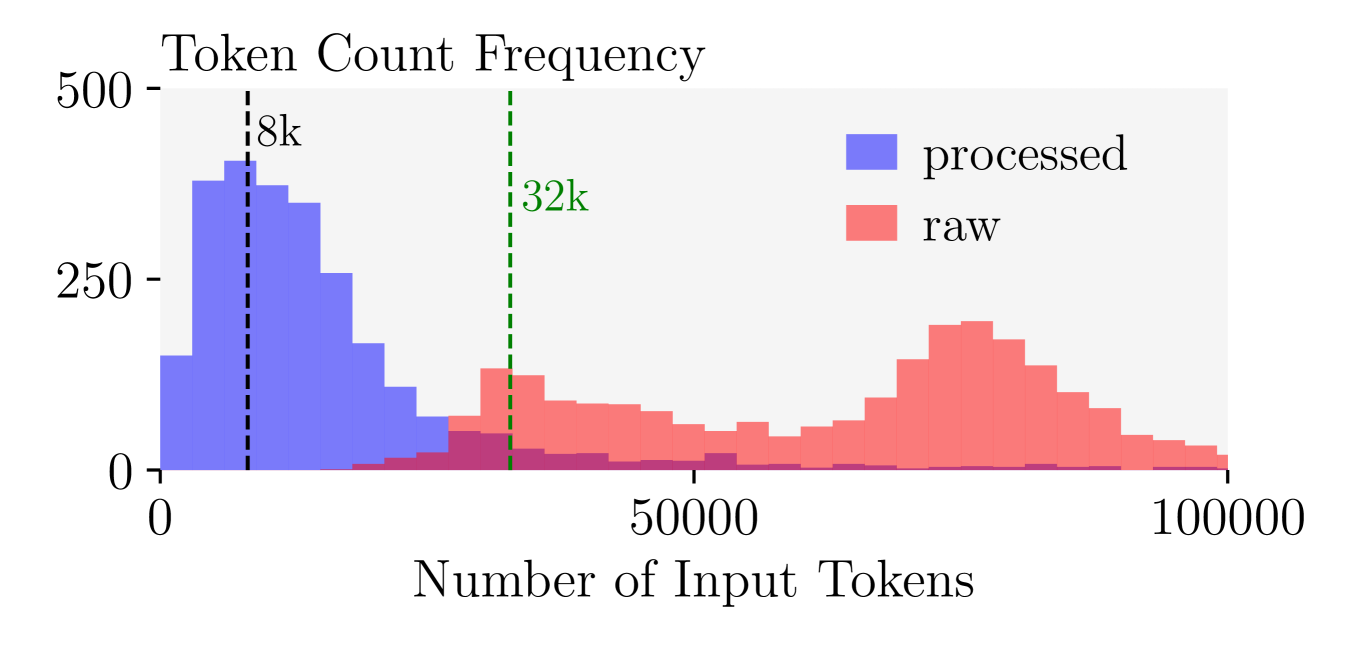

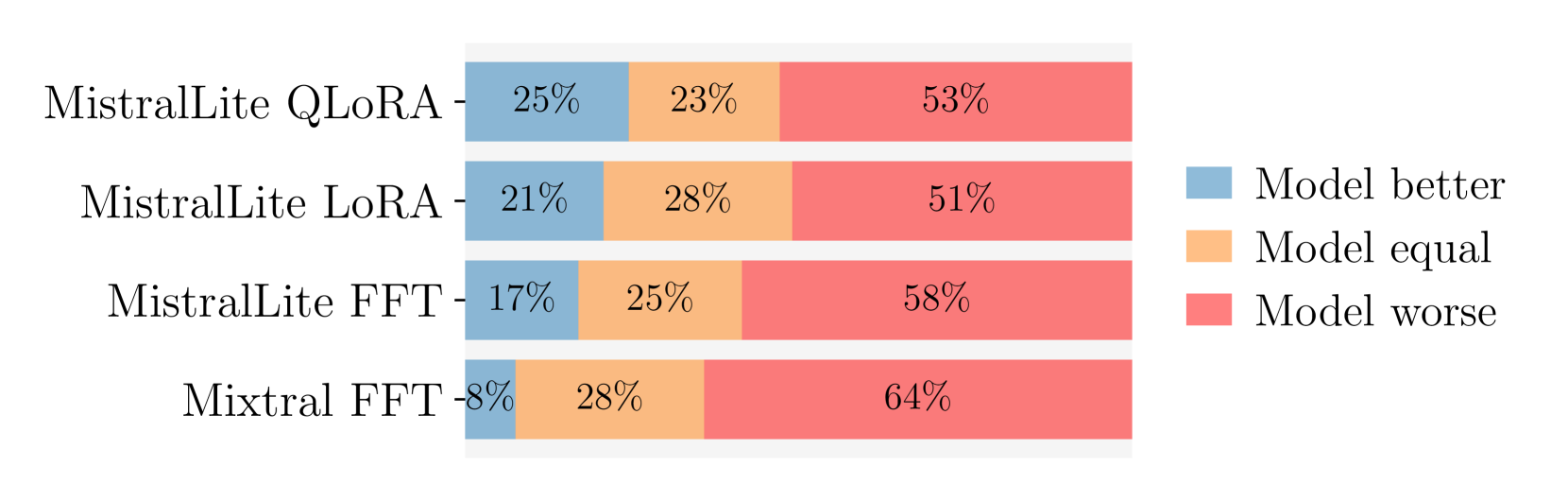
📊 实验亮点
实验结果表明,通过QLoRA微调的7B参数模型在SYSDIAGBENCH基准测试中,诊断准确性优于GPT-4,同时显著降低了计算成本。人工专家评估验证了该模型的输出质量,其批准率与参考标签相似,表明该模型具有实际应用价值。
🎯 应用场景
该研究成果可应用于工业机器人、自动化生产线等领域,实现机器人系统故障的快速诊断和修复,减少停机时间,提高生产效率。未来,可以将该方法扩展到其他复杂系统,如智能交通、智能电网等,实现智能化运维和故障预测。
📄 摘要(原文)
Quickly resolving issues reported in industrial applications is crucial to minimize economic impact. However, the required data analysis makes diagnosing the underlying root causes a challenging and time-consuming task, even for experts. In contrast, large language models (LLMs) excel at analyzing large amounts of data. Indeed, prior work in AI-Ops demonstrates their effectiveness in analyzing IT systems. Here, we extend this work to the challenging and largely unexplored domain of robotics systems. To this end, we create SYSDIAGBENCH, a proprietary system diagnostics benchmark for robotics, containing over 2500 reported issues. We leverage SYSDIAGBENCH to investigate the performance of LLMs for root cause analysis, considering a range of model sizes and adaptation techniques. Our results show that QLoRA finetuning can be sufficient to let a 7B-parameter model outperform GPT-4 in terms of diagnostic accuracy while being significantly more cost-effective. We validate our LLM-as-a-judge results with a human expert study and find that our best model achieves similar approval ratings as our reference labels.