ProtoMed-LLM: An Automatic Evaluation Framework for Large Language Models in Medical Protocol Formulation
作者: Seungjun Yi, Jaeyoung Lim, Juyong Yoon
分类: cs.CL
发布日期: 2024-10-06 (更新: 2025-04-11)
备注: Oral Presentation at the 2025 Conference on Health IT and Analytics (CHITA 2025)
💡 一句话要点
ProtoMed-LLM:用于评估医学协议生成中大型语言模型的自动化框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 科学协议制定 自动化评估 伪代码生成 生物学协议
📋 核心要点
- 现有科学协议制定任务(SPFT)的LLM评估依赖人工,效率低且成本高,缺乏自动化和灵活性。
- ProtoMed-LLM框架利用GPT-4生成伪代码作为基线,Llama-3作为评估器,实现SPFT的自动化评估。
- 实验结果表明,GPT和Cohere在SPFT任务中表现优异,同时发布了新的生物协议数据集BIOPROT 2.0。
📝 摘要(中文)
本文提出ProtoMed-LLM,一个灵活的自动化框架,用于评估大型语言模型(LLM)在科学协议制定任务(SPFT)中的能力。该框架通过提示目标模型和GPT-4从生物学协议中提取伪代码(仅使用预定义的实验室操作),并使用LLAM-EVAL评估目标模型的输出。GPT-4生成的伪代码作为基线,Llama-3作为评估器。LLAM-EVAL是一种基于提示的可调整评估方法,在评估模型、材料和标准方面具有显著的灵活性,且无需成本。论文评估了GPT变体、Llama、Mixtral、Gemma、Cohere和Gemini等模型。结果表明,GPT和Cohere在科学协议制定方面表现出色。此外,论文还引入了BIOPROT 2.0数据集,其中包含生物学协议和相应的伪代码,可用于辅助LLM进行SPFT的制定和评估。该工作可扩展到评估LLM在各个领域中SPFT的能力,以及其他需要为特定目标生成协议的领域。
🔬 方法详解
问题定义:目前,评估大型语言模型在科学协议制定任务(SPFT)中的能力主要依赖于人工评估,这既耗时又昂贵,并且缺乏客观性和可重复性。现有的评估方法难以适应不同领域和不同类型的协议,缺乏灵活性。因此,需要一种自动化的、灵活的、可扩展的评估框架来解决这些问题。
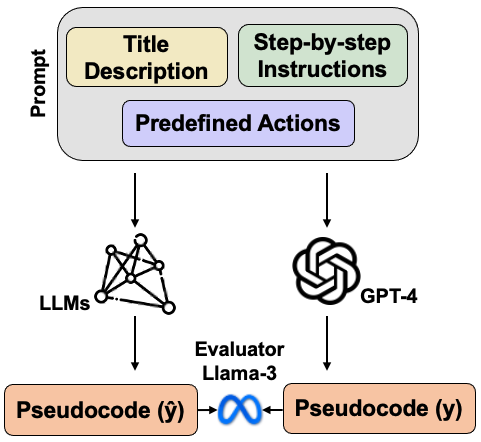
核心思路:ProtoMed-LLM的核心思路是利用大型语言模型本身的能力来评估其他大型语言模型在SPFT中的表现。具体来说,使用GPT-4生成高质量的伪代码作为基准答案,然后使用LLAM-EVAL框架,以Llama-3作为评估器,将目标模型的输出与GPT-4生成的伪代码进行比较,从而实现自动化的评估。这种方法避免了人工评估的主观性,并提高了评估的效率和可扩展性。
技术框架:ProtoMed-LLM框架主要包含以下几个模块:1) 协议输入模块:接收生物学协议作为输入。2) 伪代码生成模块:使用GPT-4从生物学协议中提取伪代码,作为基准答案。3) 目标模型推理模块:使用目标模型(如GPT变体、Llama等)从生物学协议中生成伪代码。4) LLAM-EVAL评估模块:使用Llama-3作为评估器,将目标模型的输出与GPT-4生成的伪代码进行比较,计算评估指标。5) 结果输出模块:输出评估结果,包括各个模型的性能指标。
关键创新:该论文的关键创新在于提出了一个完全自动化的评估框架ProtoMed-LLM,该框架利用LLM本身的能力进行评估,避免了人工评估的主观性和高成本。此外,LLAM-EVAL框架具有很高的灵活性,可以根据不同的评估需求调整评估模型、评估材料和评估标准。BIOPROT 2.0数据集的发布也为LLM在SPFT中的研究提供了宝贵的数据资源。
关键设计:LLAM-EVAL框架的关键设计在于使用提示工程(Prompt Engineering)来指导评估模型(Llama-3)进行评估。通过精心设计的提示,可以引导评估模型关注目标模型输出的正确性、完整性、一致性等方面。此外,BIOPROT 2.0数据集包含了生物学协议和对应的伪代码,为LLM的训练和评估提供了高质量的数据。论文中没有明确提及损失函数和网络结构等技术细节,这部分可能依赖于所使用的LLM的默认设置。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT和Cohere在科学协议制定任务中表现出色,验证了ProtoMed-LLM框架的有效性。同时,BIOPROT 2.0数据集的发布为该领域的研究提供了重要的数据支持。LLAM-EVAL框架的灵活性和低成本也使其具有很高的应用价值。
🎯 应用场景
该研究成果可广泛应用于自动化科学研究领域,加速生物、化学等领域的实验流程设计与优化。通过自动评估LLM在协议生成方面的能力,可以快速筛选出适用于特定任务的模型,降低研发成本,提高科研效率。未来,该框架可扩展到其他需要协议生成的领域,如医疗、工程等。
📄 摘要(原文)
Automated generation of scientific protocols executable by robots can significantly accelerate scientific research processes. Large Language Models (LLMs) excel at Scientific Protocol Formulation Tasks (SPFT), but the evaluation of their capabilities rely on human evaluation. Here, we propose a flexible, automatic framework to evaluate LLMs' capability on SPFT: ProtoMed-LLM. This framework prompts the target model and GPT-4 to extract pseudocode from biology protocols using only predefined lab actions and evaluates the output of the target model using LLAM-EVAL, the pseudocode generated by GPT-4 serving as a baseline and Llama-3 acting as the evaluator. Our adaptable prompt-based evaluation method, LLAM-EVAL, offers significant flexibility in terms of evaluation model, material, criteria, and is free of cost. We evaluate GPT variations, Llama, Mixtral, Gemma, Cohere, and Gemini. Overall, we find that GPT and Cohere are powerful scientific protocol formulators. We also introduce BIOPROT 2.0, a dataset with biology protocols and corresponding pseudocodes, which can aid LLMs in formulation and evaluation of SPFT. Our work is extensible to assess LLMs on SPFT across various domains and other fields that require protocol generation for specific goals.