Toward Secure Tuning: Mitigating Security Risks from Instruction Fine-Tuning
作者: Yanrui Du, Sendong Zhao, Jiawei Cao, Ming Ma, Danyang Zhao, Shuren Qi, Fenglei Fan, Ting Liu, Bing Qin
分类: cs.CL
发布日期: 2024-10-06 (更新: 2025-02-17)
💡 一句话要点
提出SWAT安全调优策略,缓解指令微调中大语言模型的安全风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 大语言模型 安全调优 对抗攻击 模块分析
📋 核心要点
- 指令微调提升LLM性能,但引入了安全漏洞,现有防御侧重预训练和后训练,缺乏训练过程中的安全保障。
- SWAT策略通过分析模块参数对安全特征的影响,识别鲁棒模块子集,并优先训练这些模块以降低安全风险。
- 实验表明,SWAT在多种数据集和LLM上有效降低了安全风险,同时保持了任务性能,且能与现有方法结合。
📝 摘要(中文)
指令微调已成为定制大语言模型(LLMs)以适应特定应用的关键技术。然而,最近的研究强调了微调LLM中存在的重大安全漏洞。现有的防御工作更多地集中在预训练和后训练方法上,而对训练中的方法探索不足。为了填补这一空白,我们提出了一种名为SWAT的新型安全调优策略。通过分析模块级参数(例如Q/K/V/O)如何影响安全特征空间的漂移,我们识别出一个鲁棒的模块子集,称为Mods_Rob。我们的SWAT策略首先预热Mods_Rob,以捕获具有最小安全风险的低级特征,然后训练所有参数以实现最佳任务性能。本质上,该策略将早期学习负担更多地从全局参数转移到Mods_Rob,从而减少了非鲁棒子集的更新幅度。在各种数据集、场景和LLM上,我们的策略已证明在减轻安全风险同时保持任务性能方面取得了显著成功。重要的是,它可以与预训练和后训练方法无缝集成,从而带来更大的改进。
🔬 方法详解
问题定义:指令微调后的LLM容易受到对抗攻击和恶意指令的利用,产生有害或不安全的输出。现有的防御方法主要集中在预训练阶段的数据清洗和后训练阶段的对抗训练,忽略了微调过程中参数更新对模型安全性的影响。因此,如何在微调过程中减轻LLM的安全风险是一个亟待解决的问题。
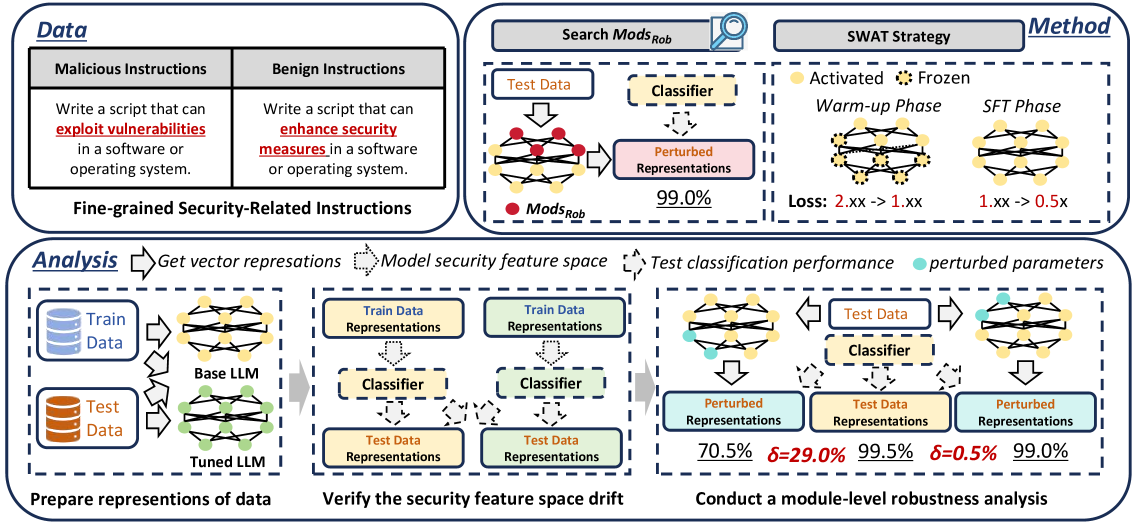
核心思路:该论文的核心思路是识别并优先训练对安全风险影响较小的模块参数,从而在微调初期就降低模型暴露于安全漏洞的可能性。通过分析不同模块参数对安全特征空间的影响,找到一个“鲁棒”的模块子集(Mods_Rob),这些模块的学习能够捕获低级特征,同时最小化安全风险。
技术框架:SWAT(Secure Warming-up and Tuning)策略包含两个主要阶段:1) 预热阶段:仅训练识别出的鲁棒模块子集Mods_Rob,使其学习到基础的任务相关特征,同时避免引入过多的安全风险。2) 调优阶段:在预热阶段的基础上,训练所有参数,以进一步提升任务性能。这种两阶段的训练方式旨在将学习负担从全局参数转移到Mods_Rob,从而减少非鲁棒参数的更新幅度。
关键创新:该论文的关键创新在于提出了模块级别的安全风险分析方法,并基于此设计了SWAT安全调优策略。与传统的全局微调方法不同,SWAT能够有选择性地训练模型参数,从而在保证任务性能的同时,显著降低模型的安全风险。这种方法为指令微调的安全防御提供了一个新的视角。
关键设计:论文的关键设计包括:1) 鲁棒模块识别:通过实验分析不同模块(如Q/K/V/O矩阵)的参数更新对安全特征空间的影响,从而确定Mods_Rob。具体的分析方法未知,需要参考论文细节。2) 预热阶段的训练策略:在预热阶段,只更新Mods_Rob的参数,其他参数保持不变。3) 调优阶段的训练策略:在预热阶段的基础上,更新所有参数,可以使用标准的微调方法,例如Adam优化器和交叉熵损失函数。具体的参数设置未知,需要参考论文细节。
🖼️ 关键图片


📊 实验亮点
SWAT策略在多个数据集、场景和LLM上进行了验证,结果表明其能够显著降低安全风险,同时保持任务性能。具体的数据和提升幅度需要在论文中查找。重要的是,SWAT可以与现有的预训练和后训练方法无缝集成,从而进一步提升模型的安全性。
🎯 应用场景
该研究成果可应用于各种需要使用指令微调来定制LLM的场景,例如智能客服、内容生成、代码生成等。通过SWAT策略,可以在保证模型性能的同时,降低模型被恶意利用的风险,提高LLM在实际应用中的安全性。该研究对提升LLM的可信度和安全性具有重要意义。
📄 摘要(原文)
Instruction fine-tuning has emerged as a critical technique for customizing Large Language Models (LLMs) to specific applications. However, recent studies have highlighted significant security vulnerabilities in fine-tuned LLMs. Existing defense efforts focus more on pre-training and post-training methods, yet there remains underexplored in in-training methods. To fill this gap, we introduce a novel secure-tuning strategy called SWAT. By analyzing how module-level parameters (e.g. Q/K/V/O) affect the security feature space drift, we identify a robust subset of modules, termed Mods_Rob. Our SWAT strategy begins by warming up Mods_Rob to capture low-level features with minimal security risks, followed by training all parameters to achieve optimal task performance. Essentially, this strategy shifts the early learning burden more from global parameters to Mods_Rob, reducing update magnitudes of the non-robust subset. Across various datasets, scenarios, and LLMs, our strategy has demonstrated significant success in mitigating security risks while preserving task performance. Importantly, it can be seamlessly integrated with pre-training and post-training methods, leading to greater improvements.