DAMRO: Dive into the Attention Mechanism of LVLM to Reduce Object Hallucination
作者: Xuan Gong, Tianshi Ming, Xinpeng Wang, Zhihua Wei
分类: cs.CL, cs.CV
发布日期: 2024-10-06 (更新: 2025-11-05)
备注: Accepted by EMNLP2024 (Main Conference), add GitHub link
🔗 代码/项目: GITHUB
💡 一句话要点
DAMRO:通过深入LVLM的注意力机制来减少物体幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型视觉语言模型 物体幻觉 注意力机制 免训练策略 视觉编码器 ViT CLS token
📋 核心要点
- 现有LVLM由于视觉编码器的缺陷,导致LLM解码器错误地关注背景信息,从而产生物体幻觉。
- DAMRO利用ViT的CLS token过滤掉背景中高注意力的异常tokens,从而在解码阶段减少其影响。
- 实验表明,DAMRO在多个基准测试中有效降低了LVLM的幻觉,提升了模型性能。
📝 摘要(中文)
大型视觉语言模型(LVLMs)取得了显著成功,但不可避免地存在幻觉问题。LVLMs中的视觉编码器和大型语言模型(LLM)解码器都基于Transformer,通过注意力机制提取视觉信息并生成文本输出。研究发现,LLM解码器对图像tokens的注意力分布与视觉编码器高度一致,且两者都倾向于关注图像中特定的背景tokens,而不是被提及的对象。这种非预期的注意力分布归因于视觉编码器本身的固有缺陷,它误导LLM过度强调冗余信息,从而产生物体幻觉。为了解决这个问题,我们提出了一种新颖的免训练策略DAMRO,即深入LVLM的注意力机制以减少物体幻觉。具体来说,我们的方法利用ViT的分类token(CLS)来过滤掉分散在背景中的高注意力异常tokens,然后在解码阶段消除它们的影响。我们在LLaVA-1.5、LLaVA-NeXT和InstructBLIP等LVLM上,使用POPE、CHAIR、MME和GPT-4V辅助评估等各种基准测试评估了我们的方法。结果表明,我们的方法显著降低了这些异常tokens的影响,从而有效缓解了LVLM的幻觉。
🔬 方法详解
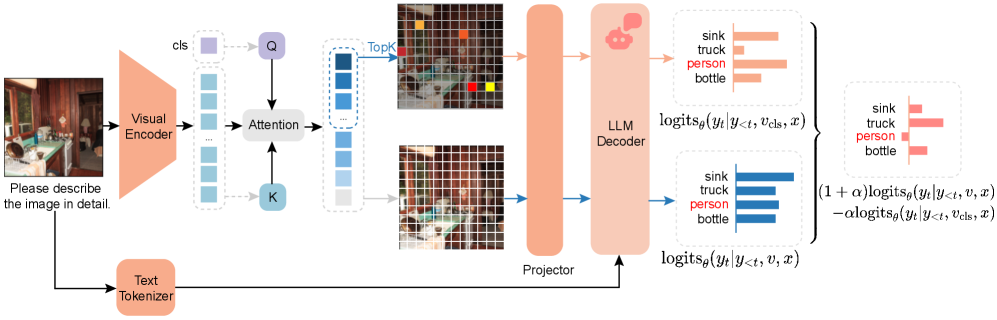
问题定义:LVLM在视觉信息理解中存在物体幻觉问题,即模型会生成图像中不存在的物体描述。现有方法未能有效解决视觉编码器对背景信息的过度关注,导致LLM解码器受到误导。
核心思路:DAMRO的核心思路是识别并抑制视觉编码器中对背景区域产生高注意力的tokens,从而减少LLM解码器对这些tokens的依赖,降低幻觉产生的可能性。通过过滤掉这些“异常”的注意力,使模型更多地关注图像中的实际物体。
技术框架:DAMRO是一种免训练策略,无需对现有LVLM进行额外的训练。其主要流程包括:1) 利用视觉编码器提取图像特征;2) 使用ViT的CLS token来评估每个图像token的重要性;3) 根据CLS token的评估结果,过滤掉高注意力的背景tokens;4) 将过滤后的特征输入LLM解码器生成文本描述。
关键创新:DAMRO的关键创新在于利用ViT的CLS token作为一种注意力过滤器,无需额外的训练数据或模型修改,即可有效识别并抑制视觉编码器中的异常注意力。这种方法简单有效,易于集成到现有的LVLM框架中。
关键设计:DAMRO的关键设计在于如何利用CLS token来确定哪些tokens应该被过滤。具体来说,论文可能采用了一种阈值方法,即设定一个注意力阈值,将注意力值高于该阈值的tokens视为异常tokens并进行过滤。阈值的具体数值可能需要根据不同的LVLM和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
DAMRO在LLaVA-1.5、LLaVA-NeXT和InstructBLIP等LVLM上进行了评估,并在POPE、CHAIR、MME等基准测试中取得了显著的性能提升。例如,在POPE基准测试中,DAMRO有效降低了模型产生幻觉的概率,提高了模型对真实物体的识别准确率。GPT-4V辅助评估也验证了DAMRO的有效性。
🎯 应用场景
DAMRO可以应用于各种需要可靠视觉信息理解的场景,例如自动驾驶、智能监控、医疗影像分析和机器人导航。通过减少物体幻觉,可以提高这些应用的安全性和准确性,并为用户提供更可靠的信息。
📄 摘要(原文)
Despite the great success of Large Vision-Language Models (LVLMs), they inevitably suffer from hallucination. As we know, both the visual encoder and the Large Language Model (LLM) decoder in LVLMs are Transformer-based, allowing the model to extract visual information and generate text outputs via attention mechanisms. We find that the attention distribution of LLM decoder on image tokens is highly consistent with the visual encoder and both distributions tend to focus on particular background tokens rather than the referred objects in the image. We attribute to the unexpected attention distribution to an inherent flaw in the visual encoder itself, which misguides LLMs to over emphasize the redundant information and generate object hallucination. To address the issue, we propose DAMRO, a novel training-free strategy that $D$ive into $A$ttention $M$echanism of LVLM to $R$educe $O$bject Hallucination. Specifically, our approach employs classification token (CLS) of ViT to filter out high-attention outlier tokens scattered in the background and then eliminate their influence during decoding stage. We evaluate our method on LVLMs including LLaVA-1.5, LLaVA-NeXT and InstructBLIP, using various benchmarks such as POPE, CHAIR, MME and GPT-4V Aided Evaluation. The results demonstrate that our approach significantly reduces the impact of these outlier tokens, thus effectively alleviating the hallucination of LVLMs. The code is released at https://github.com/coder-gx/DAMRO.