Fine-Grained Prediction of Reading Comprehension from Eye Movements
作者: Omer Shubi, Yoav Meiri, Cfir Avraham Hadar, Yevgeni Berzak
分类: cs.CL
发布日期: 2024-10-06
备注: Accepted to EMNLP
期刊: Proc. 2024 Conf. Empirical Methods in Natural Language Processing (EMNLP), pp. 3372-3391, Miami, FL, USA, Assoc. Comput. Linguist., 2024
DOI: 10.18653/v1/2024.emnlp-main.198
💡 一句话要点
提出多模态模型,利用眼动数据预测阅读理解的细粒度表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 眼动追踪 阅读理解 多模态学习 语言模型 认知科学
📋 核心要点
- 现有方法难以从眼动数据中细粒度地预测阅读理解,尤其是在单题层面上。
- 论文提出利用多模态语言模型,融合文本信息和眼动数据,预测阅读理解能力。
- 实验表明,眼动数据蕴含预测阅读理解的有效信息,模型在泛化性上表现良好。
📝 摘要(中文)
本文旨在研究人类阅读理解能力是否能通过阅读时的眼动数据进行评估。作者利用大规模眼动追踪数据,这些数据来源于专门用于阅读理解行为分析的文本材料。研究聚焦于一个细粒度的、很大程度上未被解决的任务:即基于阅读段落后针对单个问题的眼动数据来预测阅读理解能力。作者提出了三种新的多模态语言模型,并与文献中的现有模型进行比较。评估结果表明,尽管这项任务极具挑战性,但眼动数据包含可用于细粒度预测阅读理解的有用信号。代码和数据将公开。
🔬 方法详解
问题定义:论文旨在解决如何利用阅读过程中的眼动数据,对阅读理解能力进行细粒度预测的问题。现有的方法通常关注整体的阅读理解水平,缺乏对单个问题理解程度的精确评估。此外,如何有效地融合眼动数据和文本信息也是一个挑战。
核心思路:论文的核心思路是利用多模态学习,将眼动数据和文本信息结合起来,训练模型来预测阅读理解能力。作者认为,眼动数据反映了读者在阅读过程中的认知活动,与阅读理解的程度密切相关。通过学习眼动数据和文本之间的关联,可以更准确地评估阅读理解水平。
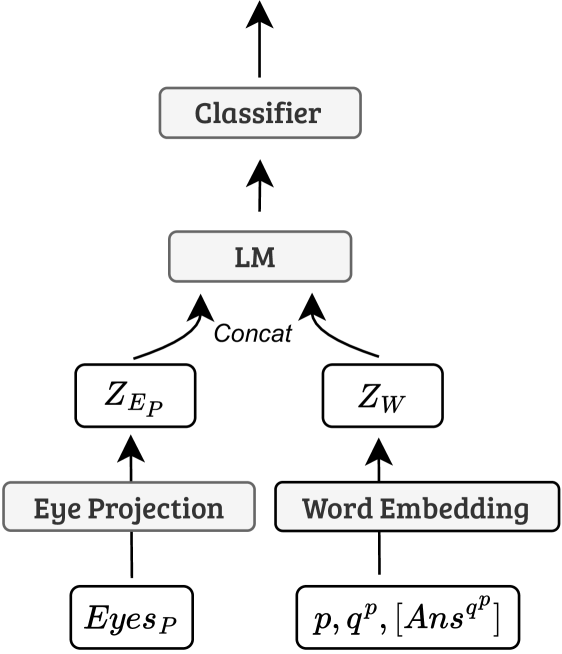
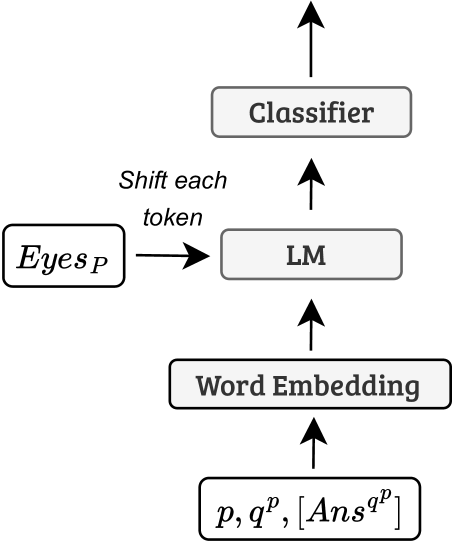
技术框架:论文提出了三种新的多模态语言模型。整体框架包括以下几个主要步骤:1) 数据预处理:对眼动数据和文本数据进行清洗和转换,提取有用的特征。2) 特征融合:将眼动特征和文本特征进行融合,形成多模态表示。3) 模型训练:使用融合后的特征训练模型,预测阅读理解能力。4) 模型评估:在不同的数据集和阅读模式下评估模型的性能。
关键创新:论文的关键创新在于提出了新的多模态语言模型,能够有效地融合眼动数据和文本信息,从而实现对阅读理解能力的细粒度预测。与现有方法相比,该方法能够更准确地评估单个问题的理解程度,并具有更好的泛化能力。
关键设计:论文中涉及的关键设计包括:1) 眼动特征的选择:选择了与阅读理解相关的眼动指标,如注视时长、注视次数、扫视幅度等。2) 文本特征的提取:使用了预训练的语言模型(如BERT)来提取文本特征。3) 融合策略:采用了不同的融合策略,如拼接、注意力机制等,来融合眼动特征和文本特征。4) 损失函数:使用了交叉熵损失函数来训练模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的多模态模型在预测阅读理解能力方面取得了显著的成果。模型在泛化到新的文本材料、新的参与者以及两者的组合方面都表现出良好的性能。在普通阅读和信息搜寻两种不同的阅读模式下,模型均优于现有的基线模型,证明了眼动数据在细粒度阅读理解预测中的有效性。具体的性能提升数据未知,需要在论文中进一步查找。
🎯 应用场景
该研究成果可应用于智能教育领域,例如开发个性化阅读辅导系统,根据学生的眼动数据实时评估其阅读理解水平,并提供针对性的指导。此外,该技术还可用于评估文本的可读性,优化信息检索系统,以及辅助认知科学研究。
📄 摘要(原文)
Can human reading comprehension be assessed from eye movements in reading? In this work, we address this longstanding question using large-scale eyetracking data over textual materials that are geared towards behavioral analyses of reading comprehension. We focus on a fine-grained and largely unaddressed task of predicting reading comprehension from eye movements at the level of a single question over a passage. We tackle this task using three new multimodal language models, as well as a battery of prior models from the literature. We evaluate the models' ability to generalize to new textual items, new participants, and the combination of both, in two different reading regimes, ordinary reading and information seeking. The evaluations suggest that although the task is highly challenging, eye movements contain useful signals for fine-grained prediction of reading comprehension. Code and data will be made publicly available.