Inner-Probe: Discovering Copyright-related Data Generation in LLM Architecture
作者: Qichao Ma, Rui-Jie Zhu, Peiye Liu, Renye Yan, Fahong Zhang, Ling Liang, Meng Li, Zhaofei Yu, Zongwei Wang, Yimao Cai, Tiejun Huang
分类: cs.CL
发布日期: 2024-10-06 (更新: 2026-01-01)
备注: Accepted by IEEE Transactions on Artificial Intelligence
💡 一句话要点
Inner-Probe:通过分析LLM内部结构发现版权相关数据生成的影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 版权检测 多头注意力 子数据集分析 对比学习
📋 核心要点
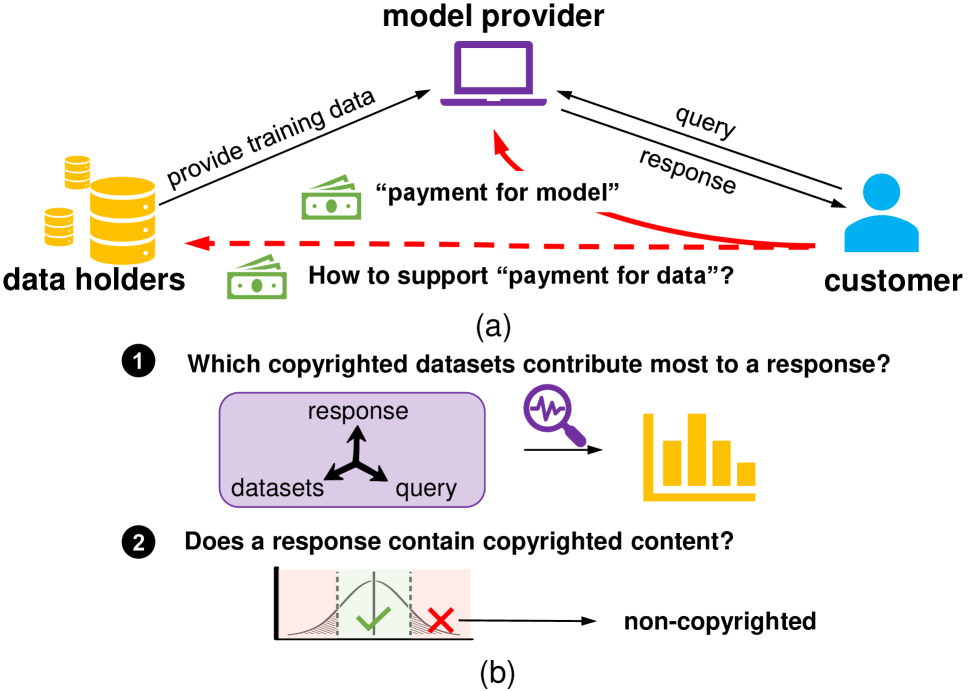
- 现有方法难以确定LLM生成文本受哪些特定版权子数据集的影响,且常将所有训练数据视为受版权保护。
- Inner-Probe利用LLM生成过程中的多头注意力(MHA)结果,通过监督学习和对比学习分析版权影响。
- 实验表明,Inner-Probe在子数据集贡献分析效率、准确率和非版权数据过滤AUC方面均优于现有方法。
📝 摘要(中文)
大型语言模型(LLM)利用广泛的知识库并展现出强大的文本生成能力。然而,它们对高质量版权数据集的依赖引发了对生成文本中版权侵权问题的担忧。目前的研究通常采用提示工程或语义分类器来识别受版权保护的内容,但这些方法存在两个显著的局限性:(1)难以确定哪个特定的子数据集(例如,特定作者的作品)影响了LLM的输出。(2)将整个训练数据库视为受版权保护的,从而忽略了非版权训练数据的存在。我们提出了Inner-Probe,一个轻量级框架,旨在评估受版权保护的子数据集对LLM生成文本的影响。与传统方法仅依赖文本不同,我们发现LLM输出生成期间的多头注意力(MHA)结果提供了更有效的信息。因此,Inner-Probe使用基于LSTM的轻量级网络,在监督下对MHA结果进行训练,从而进行子数据集贡献分析。利用这种先验知识,Inner-Probe通过使用无监督对比学习训练的连接全局投影器来实现非版权文本检测。Inner-Probe在Books3上的子数据集贡献分析中,效率比语义模型训练提高了3倍,在Pile上实现了比基线高15.04% - 58.7%的准确率,并且在非版权数据过滤方面AUC提高了0.104。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)生成文本时,如何评估特定版权子数据集对其输出的影响,并区分版权内容与非版权内容的问题。现有方法主要依赖于文本分析,如提示工程和语义分类,但这些方法无法精确定位影响LLM输出的特定子数据集,并且假设所有训练数据都受版权保护,忽略了非版权数据的存在。
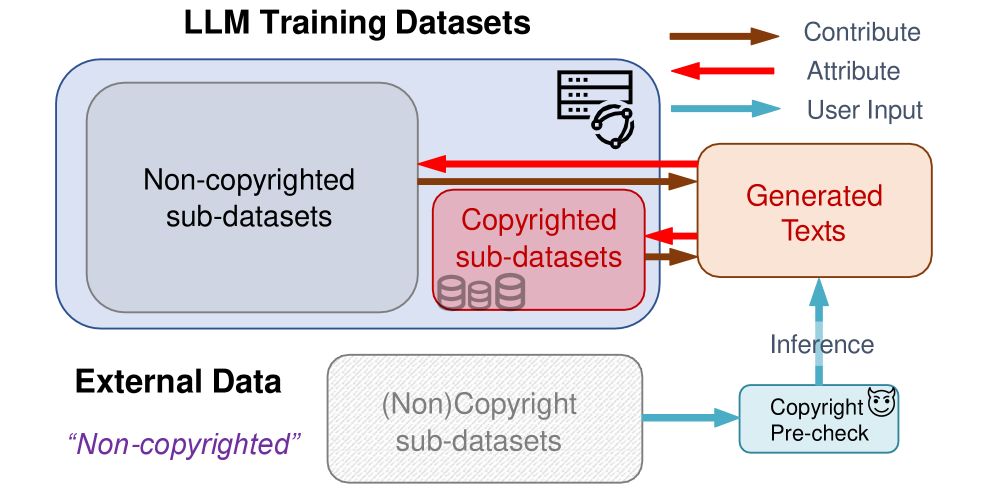
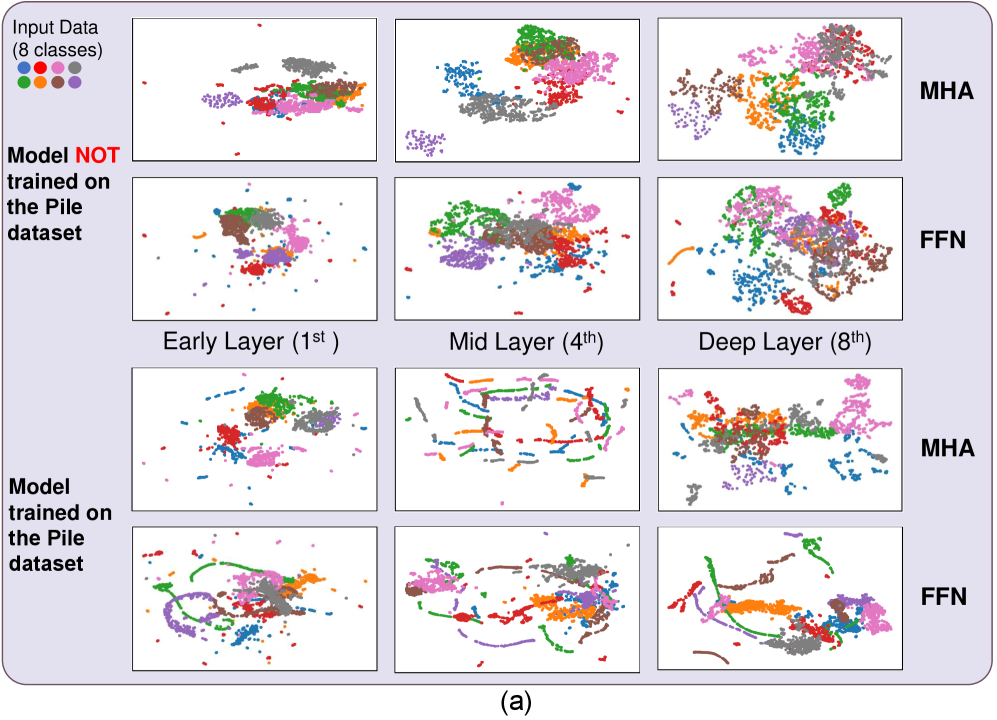
核心思路:论文的核心思路是利用LLM在生成文本过程中的内部信息,特别是多头注意力(MHA)机制的结果,来分析不同子数据集对生成文本的贡献。MHA结果能够反映LLM在生成过程中对不同知识来源的关注程度,因此可以用于推断哪些子数据集对最终输出产生了影响。此外,通过对比学习,区分版权内容和非版权内容。
技术框架:Inner-Probe框架包含两个主要模块:子数据集贡献分析和非版权文本检测。子数据集贡献分析模块首先提取LLM生成文本时的MHA结果,然后使用一个轻量级的LSTM网络,在监督学习的框架下,学习MHA结果与不同子数据集之间的关系,从而评估每个子数据集对生成文本的贡献。非版权文本检测模块则使用一个连接全局投影器,通过无监督对比学习,将文本嵌入到特征空间中,从而区分版权内容和非版权内容。
关键创新:论文的关键创新在于利用LLM内部的多头注意力机制(MHA)结果进行版权影响分析。与传统的仅依赖文本分析的方法不同,Inner-Probe能够更深入地了解LLM的生成过程,从而更准确地评估不同子数据集的贡献。此外,使用对比学习进行非版权文本检测,避免了对大量标注数据的依赖。
关键设计:在子数据集贡献分析模块中,LSTM网络的结构和训练方式是关键设计。LSTM网络需要能够有效地捕捉MHA结果中的时序信息,并学习MHA结果与子数据集之间的复杂关系。在非版权文本检测模块中,对比学习的损失函数和投影器的结构是关键设计。损失函数需要能够有效地将版权内容和非版权内容区分开来,而投影器需要能够将文本嵌入到合适的特征空间中。
🖼️ 关键图片
📊 实验亮点
Inner-Probe在Books3数据集上进行子数据集贡献分析时,效率比语义模型训练提高了3倍。在Pile数据集上,Inner-Probe的准确率比基线方法提高了15.04% - 58.7%。在非版权数据过滤方面,Inner-Probe的AUC提高了0.104,表明其能够更有效地识别非版权内容。
🎯 应用场景
Inner-Probe可应用于评估LLM生成内容中的版权风险,帮助开发者识别和避免潜在的侵权行为。此外,该方法还可以用于分析LLM的知识来源,了解不同数据集对模型行为的影响,从而优化训练数据和提高模型性能。未来,该技术可用于构建更安全、更可靠的LLM系统。
📄 摘要(原文)
Large Language Models (LLMs) utilize extensive knowledge databases and show powerful text generation ability. However, their reliance on high-quality copyrighted datasets raises concerns about copyright infringements in generated texts. Current research often employs prompt engineering or semantic classifiers to identify copyrighted content, but these approaches have two significant limitations: (1) Challenging to identify which specific subdataset (e.g., works from particular authors) influences an LLM's output. (2) Treating the entire training database as copyrighted, hence overlooking the inclusion of non-copyrighted training data. We propose Inner-Probe, a lightweight framework designed to evaluate the influence of copyrighted sub-datasets on LLM-generated texts. Unlike traditional methods relying solely on text, we discover that the results of multi-head attention (MHA) during LLM output generation provide more effective information. Thus, Inner-Probe performs sub-dataset contribution analysis using a lightweight LSTM based network trained on MHA results in a supervised manner. Harnessing such a prior, Inner-Probe enables non-copyrighted text detection through a concatenated global projector trained with unsupervised contrastive learning. Inner-Probe demonstrates 3x improved efficiency compared to semantic model training in sub-dataset contribution analysis on Books3, achieves 15.04% - 58.7% higher accuracy over baselines on the Pile, and delivers a 0.104 increase in AUC for non-copyrighted data filtering.