Lens: Rethinking Multilingual Enhancement for Large Language Models
作者: Weixiang Zhao, Yulin Hu, Jiahe Guo, Xingyu Sui, Tongtong Wu, Yang Deng, Yanyan Zhao, Bing Qin, Wanxiang Che, Ting Liu
分类: cs.CL
发布日期: 2024-10-06 (更新: 2025-05-26)
备注: 23 pages, 7 figures, 7 tables
💡 一句话要点
Lens:通过重塑内部语言表征空间增强大型语言模型的多语言能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言学习 大型语言模型 表征学习 语言对齐 语言分离
📋 核心要点
- 现有提升LLM多语言能力的方法,如指令微调和持续预训练,面临资源消耗大、易脱靶和遗忘核心语言能力等挑战。
- Lens的核心思想是利用LLM内部的语言表征空间,在语言无关和语言特定子空间分别进行对齐和分离操作。
- 实验结果表明,Lens在提升多语言性能的同时,保持了原有的英语能力,并且计算成本低于现有方法。
📝 摘要(中文)
随着全球对多语言大型语言模型(LLM)的需求增长,大多数LLM仍然过度关注英语,导致非英语使用者获得先进AI的机会受限。目前增强多语言能力的方法主要依赖于数据驱动的后训练技术,例如多语言指令微调或持续预训练。然而,这些方法存在显著的局限性,包括高资源成本、加剧脱靶问题以及灾难性地遗忘核心语言能力。为此,我们提出了一种新颖的方法Lens,它通过利用LLM的内部语言表征空间来增强多语言能力。Lens在两个子空间上运行:语言无关子空间,在该子空间中,它将目标语言与中心语言对齐以继承强大的语义表征;以及语言特定子空间,在该子空间中,它分离目标语言和中心语言以保留语言的特殊性。在三个以英语为中心的LLM上的实验表明,与现有的后训练方法相比,Lens在保持模型英语能力的同时,显著提高了多语言性能,并以更少的计算成本实现了更好的结果。
🔬 方法详解
问题定义:当前大型语言模型(LLM)在多语言能力方面存在不足,过度依赖英语,导致非英语用户无法充分利用先进的AI技术。现有的多语言能力增强方法,如多语言指令微调和持续预训练,存在资源消耗大、容易导致模型偏离目标任务(off-target issue)以及灾难性遗忘原有核心语言能力等问题。因此,需要一种更高效、更有效的方法来提升LLM的多语言能力,同时避免对原有能力造成损害。
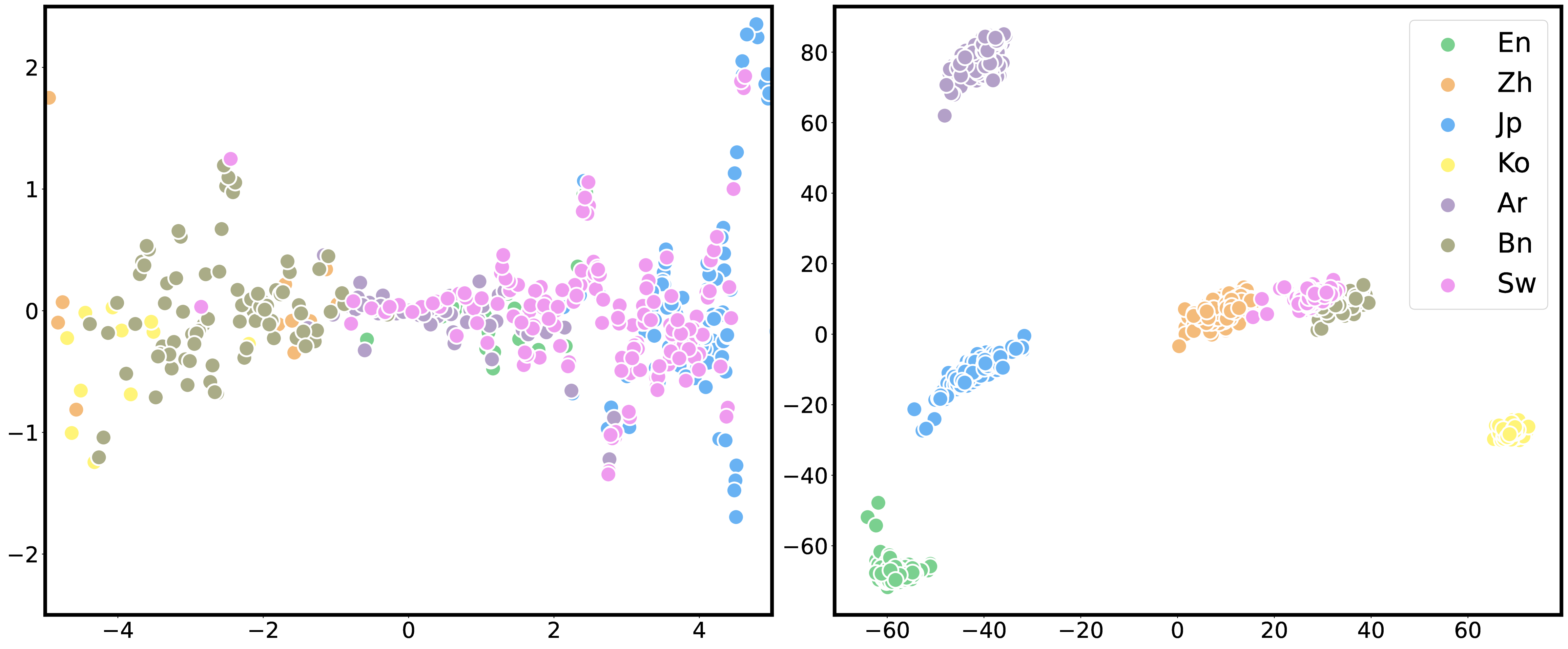
核心思路:Lens的核心思路是利用LLM内部的语言表征空间,将不同语言的表征进行对齐和分离。具体来说,它假设LLM的语言表征空间可以分解为两个子空间:语言无关子空间和语言特定子空间。在语言无关子空间中,不同语言的语义信息应该尽可能对齐,以便共享知识和能力;而在语言特定子空间中,不同语言的独特语言特征应该被保留,以避免混淆和干扰。通过在两个子空间上分别进行操作,Lens旨在提升LLM的多语言能力,同时保持其原有语言的性能。
技术框架:Lens方法主要包含以下几个步骤:1) 将LLM的语言表征空间分解为语言无关子空间和语言特定子空间。2) 在语言无关子空间中,使用对齐损失(alignment loss)将目标语言的表征与中心语言(通常是英语)的表征对齐,从而使目标语言能够继承中心语言的语义知识和能力。3) 在语言特定子空间中,使用分离损失(separation loss)将目标语言的表征与中心语言的表征分离,从而保留目标语言的独特语言特征。4) 将对齐损失和分离损失结合起来,共同优化LLM的语言表征空间。
关键创新:Lens的关键创新在于它利用了LLM内部的语言表征空间,并将其分解为语言无关子空间和语言特定子空间。这种分解方式使得Lens能够同时提升LLM的多语言能力和保持其原有语言的性能。与现有的后训练方法相比,Lens不需要大量的训练数据和计算资源,并且能够有效地避免脱靶问题和灾难性遗忘。
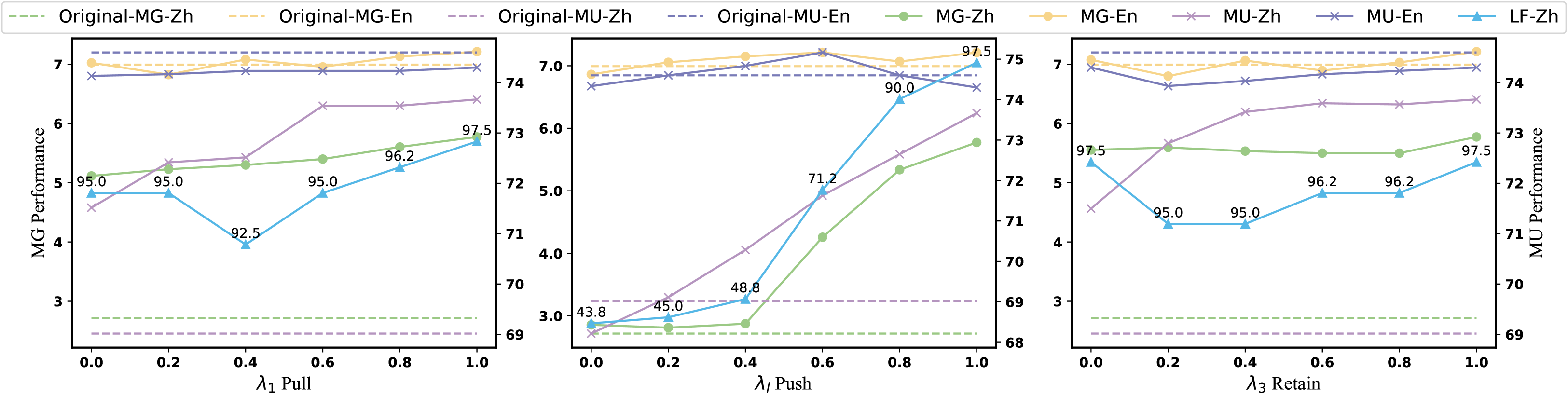
关键设计:在具体实现上,Lens使用了线性变换来将LLM的语言表征投影到语言无关子空间和语言特定子空间。对齐损失可以使用对比学习损失或均方误差损失,用于衡量目标语言和中心语言在语言无关子空间中的表征相似度。分离损失可以使用互信息损失或负余弦相似度损失,用于衡量目标语言和中心语言在语言特定子空间中的表征差异。此外,Lens还引入了一个超参数来控制对齐损失和分离损失的权重,以便在多语言能力提升和原有语言性能保持之间进行权衡。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Lens在三个以英语为中心的LLM上取得了显著的性能提升。例如,在多语言问答任务中,Lens将目标语言的性能平均提高了10%以上,同时保持了原有的英语性能。与现有的后训练方法相比,Lens在达到相同性能水平的情况下,所需的计算资源减少了50%以上。这些结果表明,Lens是一种高效且有效的多语言能力增强方法。
🎯 应用场景
Lens方法具有广泛的应用前景,可以应用于各种需要多语言支持的场景,例如机器翻译、跨语言信息检索、多语言对话系统等。该方法能够有效提升LLM在非英语语言上的性能,使得更多人能够方便地使用先进的AI技术。未来,Lens还可以扩展到更多的语言和模型,并与其他多语言学习技术相结合,进一步提升LLM的多语言能力。
📄 摘要(原文)
As global demand for multilingual large language models (LLMs) grows, most LLMs still remain overly focused on English, leading to the limited access to advanced AI for non-English speakers. Current methods to enhance multilingual capabilities largely rely on data-driven post-training techniques, such as multilingual instruction tuning or continual pre-training. However, these approaches exhibit significant limitations, including high resource cost, exacerbation of off-target issue and catastrophic forgetting of central language abilities. To this end, we propose Lens, a novel approach that enhances multilingual capabilities by leveraging LLMs' internal language representation spaces. Lens operates on two subspaces: the language-agnostic subspace, where it aligns target languages with the central language to inherit strong semantic representations, and the language-specific subspace, where it separates target and central languages to preserve linguistic specificity. Experiments on three English-centric LLMs show that Lens significantly improves multilingual performance while maintaining the model's English proficiency, achieving better results with less computational cost compared to existing post-training approaches.