Permutative Preference Alignment from Listwise Ranking of Human Judgments
作者: Yang Zhao, Yixin Wang, Mingzhang Yin
分类: cs.CL
发布日期: 2024-10-06 (更新: 2025-10-22)
备注: Published at EMNLP 2025 Main Conference
💡 一句话要点
提出PPA:基于列表排序的人工反馈偏好对齐方法,提升LLM排序能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好对齐 大型语言模型 列表排序 NDCG 人类反馈 强化学习 直接偏好优化
📋 核心要点
- 现有基于Bradley-Terry模型的偏好对齐方法在处理多个响应时,无法保证准确的列表排序,影响模型性能。
- 论文提出排列偏好对齐(PPA)方法,使用NDCG作为训练目标,优化LLM的排序能力,实现更精准的偏好对齐。
- 实验结果表明,PPA在多个评估集和基准测试中,均优于现有的成对和列表式方法,显著提升了排序准确性。
📝 摘要(中文)
将大型语言模型(LLM)与人类偏好对齐对于确保模型行为的可控性和合意性至关重要。目前的方法,如基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO),依赖于Bradley-Terry(B-T)模型来最大化成对选择的可能性。然而,当有多个响应可用时,B-T模型无法保证对响应进行准确的列表排序。为了解决这个问题,我们提出了一种新的离线列表式方法,即排列偏好对齐(PPA),该方法将归一化折损累积增益(NDCG)作为LLM对齐的替代训练目标。我们通过用可微代理损失逼近NDCG,开发了一种端到端的对齐算法。实验表明,PPA在评估集和通用基准(如AlpacaEval)上优于现有的成对和列表式方法。此外,我们证明了基于NDCG的方法比基于B-T的方法更有效地提高排序准确性,并为这种改进提供了理论解释。
🔬 方法详解
问题定义:现有基于Bradley-Terry (B-T) 模型的偏好对齐方法,例如RLHF和DPO,在处理多个模型输出时,无法保证生成结果的准确排序。B-T模型主要关注成对比较,忽略了整体排序结构,导致在多响应场景下性能受限。因此,如何提升LLM在多响应场景下的排序能力是一个关键问题。
核心思路:论文的核心思路是使用Normalized Discounted Cumulative Gain (NDCG) 作为训练目标,直接优化LLM的排序能力。NDCG是一种广泛使用的排序指标,能够更好地反映整体排序质量。通过将NDCG纳入训练过程,PPA旨在使LLM生成的响应列表更符合人类的偏好排序。
技术框架:PPA是一个离线列表式偏好对齐框架,主要包含以下步骤:1) 收集人类对多个模型响应的排序数据;2) 使用可微的NDCG代理损失函数,对LLM进行微调;3) 使用微调后的LLM生成响应,并根据NDCG进行排序。整个过程是端到端的,可以直接优化LLM的排序能力。
关键创新:PPA的关键创新在于使用NDCG作为LLM对齐的训练目标。与传统的基于B-T模型的方法不同,PPA直接优化排序指标,从而更有效地提升LLM在多响应场景下的排序能力。此外,论文还提出了一个可微的NDCG代理损失函数,使得可以使用梯度下降等优化算法进行训练。
关键设计:PPA使用一个可微的NDCG代理损失函数来近似NDCG。具体来说,论文采用了一种基于排列的损失函数,该函数考虑了所有可能的排列,并使用softmax函数来近似排序概率。此外,论文还使用了discount factor来强调排序列表中头部位置的重要性。具体的损失函数形式在论文中有详细描述,需要根据实际公式进行理解。
🖼️ 关键图片


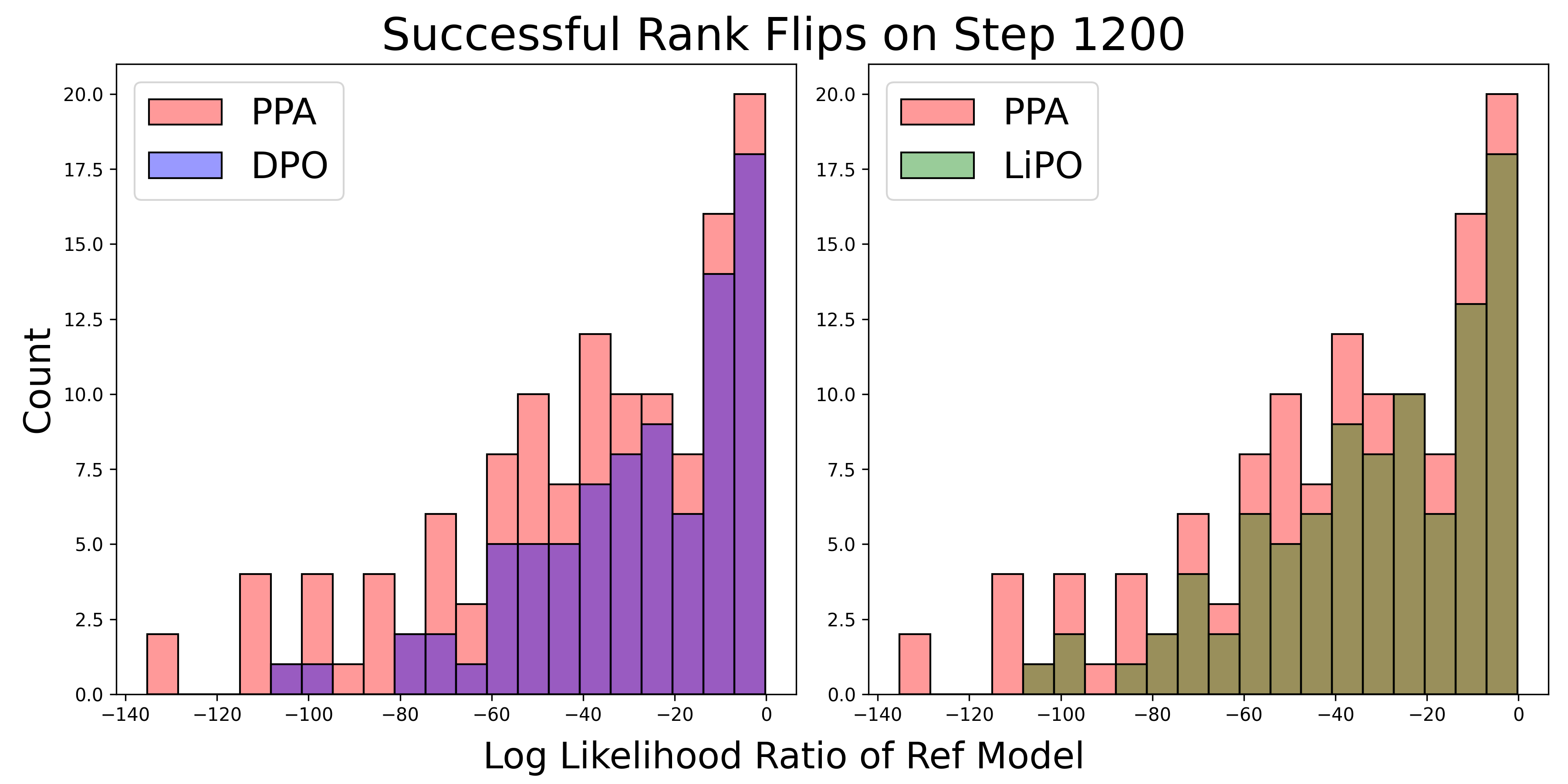
📊 实验亮点
实验结果表明,PPA在AlpacaEval等基准测试中优于现有的成对和列表式方法。例如,PPA在排序准确率方面取得了显著提升,超过了DPO等基线方法。此外,论文还通过实验验证了基于NDCG的方法比基于B-T的方法更有效地提高排序准确性,并从理论上解释了这种改进。
🎯 应用场景
PPA方法可应用于各种需要对LLM生成结果进行排序的场景,例如:问答系统、文本摘要、代码生成等。通过提升LLM的排序能力,可以提高用户满意度,并改善下游任务的性能。该研究对于提升LLM的实用性和可靠性具有重要意义,并为未来的偏好对齐研究提供了新的思路。
📄 摘要(原文)
Aligning Large Language Models (LLMs) with human preferences is crucial in ensuring desirable and controllable model behaviors. Current methods, such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), rely on the Bradley-Terry (B-T) model to maximize the likelihood of pairwise choices. However, when multiple responses are available, the B-T model fails to guarantee an accurate list ranking of the responses. To address this issue, we propose Permutative Preference Alignment (PPA), a novel offline listwise approach that incorporates the Normalized Discounted Cumulative Gain (NDCG), a widely-used ranking metric, as an alternative training objective for LLM alignment. We develop an end-to-end alignment algorithm by approximating NDCG with a differentiable surrogate loss. Experiments demonstrate that PPA outperforms existing pairwise and listwise methods on evaluation sets and general benchmarks such as AlpacaEval. Furthermore, we show that NDCG-based approaches improve ranking accuracy more effectively than B-T-based methods and provide a theoretical explanation for this improvement.