ReTok: Replacing Tokenizer to Enhance Representation Efficiency in Large Language Model
作者: Shuhao Gu, Mengdi Zhao, Bowen Zhang, Liangdong Wang, Jijie Li, Guang Liu
分类: cs.CL
发布日期: 2024-10-06
💡 一句话要点
ReTok:通过替换分词器提升大语言模型的表征效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 分词器 表征效率 长文本处理 模型优化
📋 核心要点
- 现有分词器在高压缩率方面存在局限性,导致大语言模型处理长文本时效率降低,训练和推理成本增加。
- 该论文提出替换大语言模型的分词器,并重新初始化输入输出层参数,以提升模型表征和处理效率。
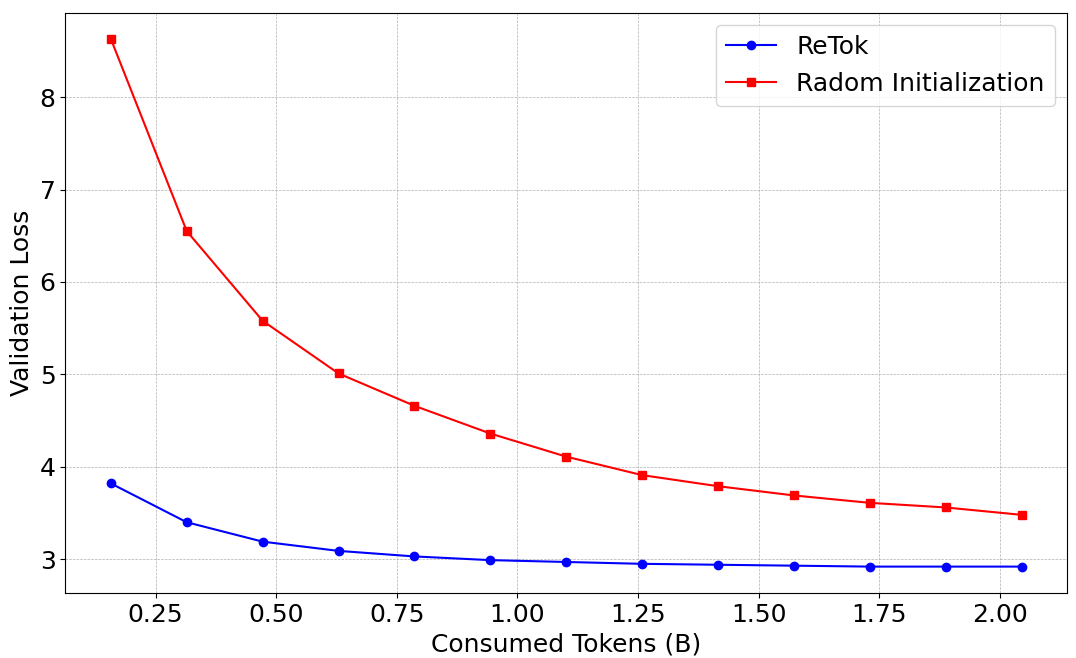
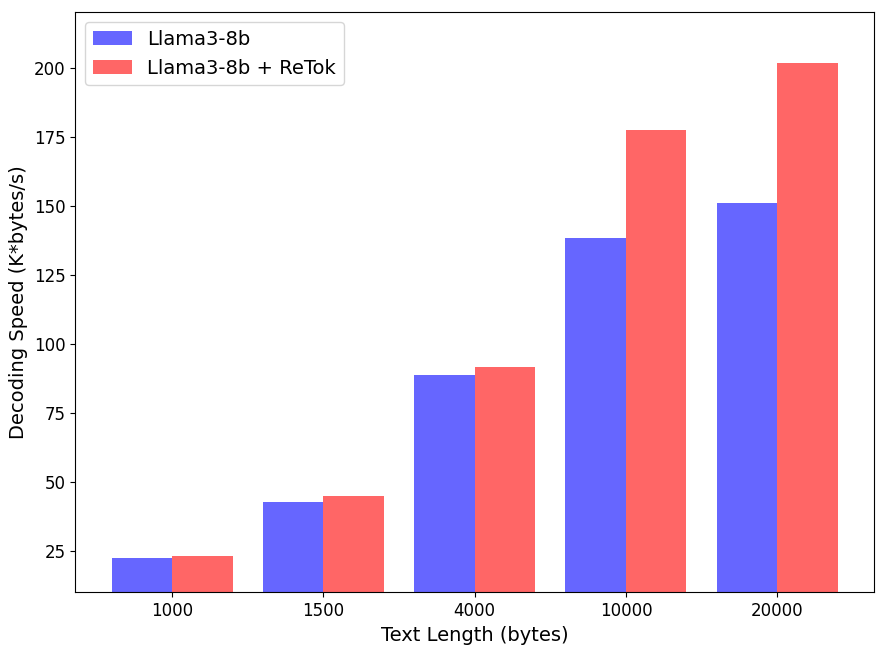
- 实验结果表明,该方法在保持模型性能的同时,显著提高了长文本的解码速度,验证了其有效性。
📝 摘要(中文)
分词器是大语言模型(LLMs)的关键组成部分,高压缩率的分词器可以提高模型的表征和处理效率。然而,分词器无法在所有场景下都保证高压缩率,平均输入和输出长度的增加会提高模型的训练和推理成本。因此,如何在保持模型性能的同时,以最小的成本提高模型的效率至关重要。本文提出了一种通过替换LLMs的分词器来提高模型表征和处理效率的方法。具体而言,我们建议替换并重新初始化模型输入和输出层的参数,使用原始模型的参数,并在固定其他参数的同时训练这些参数。我们在不同的LLMs上进行了实验,结果表明,我们的方法可以在替换分词器后保持模型的性能,同时显著提高长文本的解码速度。
🔬 方法详解
问题定义:论文旨在解决大语言模型中分词器压缩率不足导致的长文本处理效率低下的问题。现有分词器无法保证所有场景下的高压缩率,使得模型在处理长文本时,输入和输出长度增加,从而增加了训练和推理的计算成本。
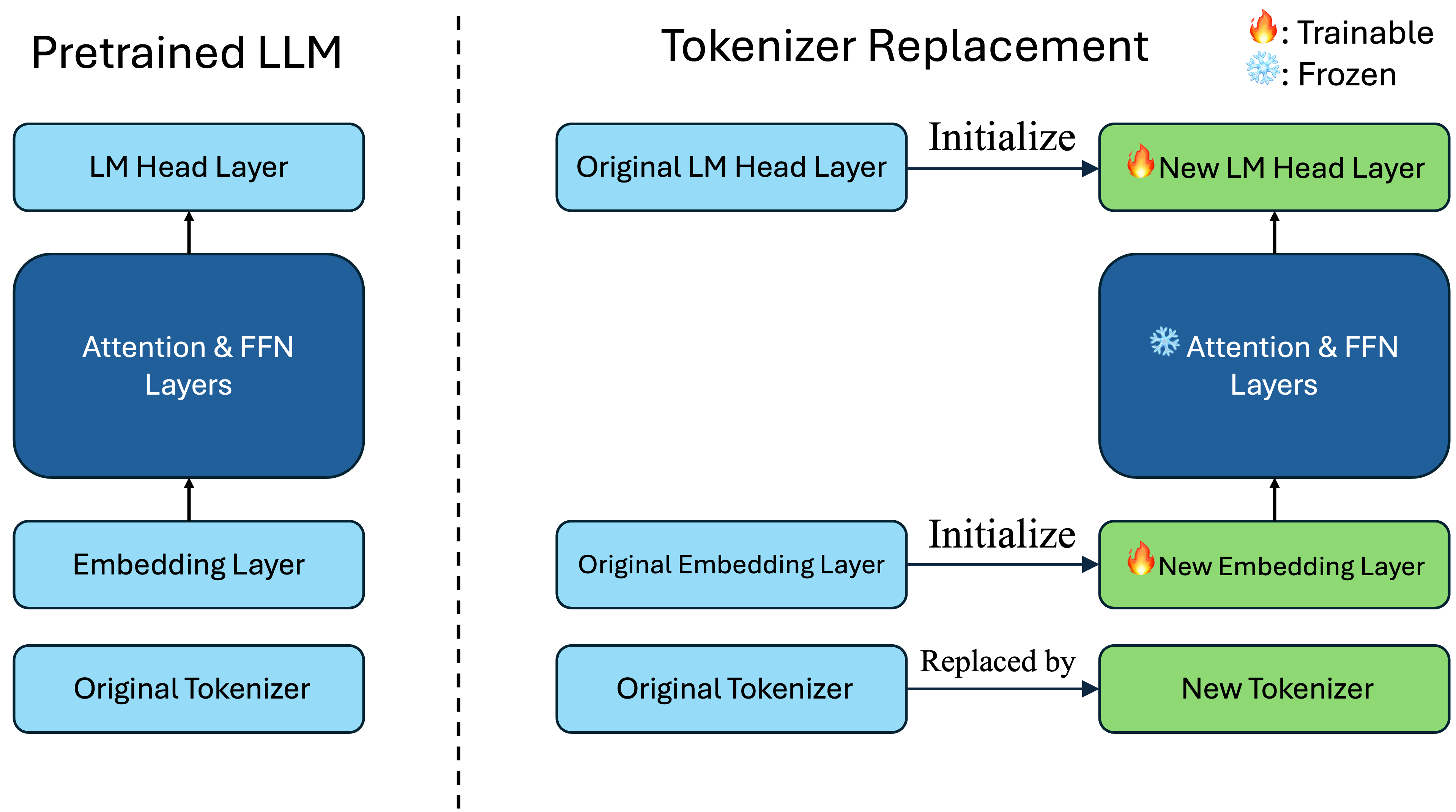
核心思路:论文的核心思路是通过替换现有分词器,并对模型的输入和输出层进行参数重初始化和微调,从而在不影响模型性能的前提下,提升模型的表征效率和处理速度。这种方法旨在找到一种低成本的方式来优化模型效率。
技术框架:该方法主要包含以下几个阶段:1) 选择新的分词器;2) 使用原始模型的参数初始化替换后的模型的输入和输出层;3) 固定模型其他参数,仅训练输入和输出层参数。这个过程可以看作是对模型进行微调,使其适应新的分词器。
关键创新:该方法的关键创新在于提出了一种简单有效的替换分词器的策略,通过参数重初始化和微调,使得模型能够快速适应新的分词器,并在保持性能的同时提升效率。与从头训练相比,该方法大大降低了计算成本。
关键设计:论文的关键设计在于如何初始化替换后的模型的输入和输出层参数。具体而言,使用原始模型的对应参数进行初始化,然后固定其他层参数,只对输入和输出层进行微调。这种设计保证了模型在替换分词器后能够快速恢复性能,并避免了从头训练带来的高昂成本。损失函数和网络结构等细节未在摘要中提及,具体实现未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法可以在替换分词器后保持模型的性能,同时显著提高长文本的解码速度。具体的性能提升数据和对比基线未在摘要中详细说明,需要参考论文全文。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的大语言模型应用场景,例如机器翻译、文本摘要、问答系统等。通过提升模型处理长文本的效率,可以降低计算成本,提高用户体验,并推动大语言模型在资源受限环境下的部署和应用。
📄 摘要(原文)
Tokenizer is an essential component for large language models (LLMs), and a tokenizer with a high compression rate can improve the model's representation and processing efficiency. However, the tokenizer cannot ensure high compression rate in all scenarios, and an increase in the average input and output lengths will increases the training and inference costs of the model. Therefore, it is crucial to find ways to improve the model's efficiency with minimal cost while maintaining the model's performance. In this work, we propose a method to improve model representation and processing efficiency by replacing the tokenizers of LLMs. We propose replacing and reinitializing the parameters of the model's input and output layers with the parameters of the original model, and training these parameters while keeping other parameters fixed. We conducted experiments on different LLMs, and the results show that our method can maintain the performance of the model after replacing the tokenizer, while significantly improving the decoding speed for long texts.