From Reading to Compressing: Exploring the Multi-document Reader for Prompt Compression
作者: Eunseong Choi, Sunkyung Lee, Minjin Choi, June Park, Jongwuk Lee
分类: cs.CL, cs.AI
发布日期: 2024-10-05 (更新: 2024-12-31)
备注: Findings of the Association for Computational Linguistics: EMNLP 2024; 21 pages; 10 figures and 7 tables. Code available at https://github.com/eunseongc/R2C
💡 一句话要点
提出R2C模型,利用多文档阅读器进行提示压缩,提升大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示压缩 大型语言模型 Fusion-in-Decoder 交叉注意力 全局上下文
📋 核心要点
- 现有提示压缩方法难以兼顾全局上下文捕获和压缩器有效训练。
- R2C利用FiD架构的交叉注意力机制,无需伪标签即可识别并保留关键信息。
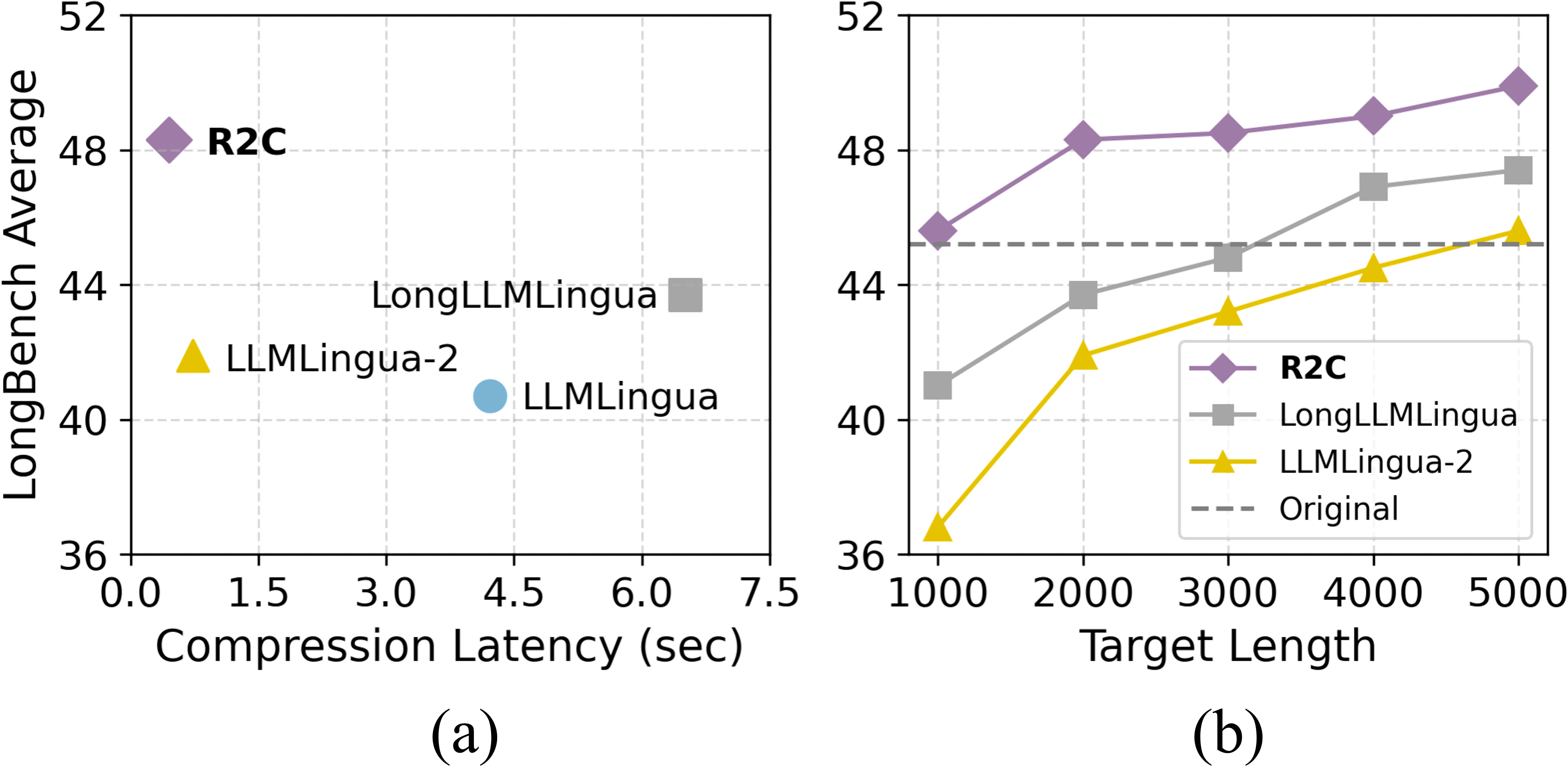
- 实验表明,R2C在大幅压缩提示长度的同时,显著提升了LLM在领域外任务的性能。
📝 摘要(中文)
大型语言模型(LLMs)通过先进的提示技术在各种任务中取得了显著的性能提升。然而,提示长度的增加导致了高昂的计算成本,并且常常掩盖了关键信息。提示压缩已被提出以缓解这些问题,但它面临着(i)捕获全局上下文和(ii)有效训练压缩器的挑战。为了应对这些挑战,我们引入了一种新颖的提示压缩方法,即Reading To Compressing(R2C),它利用Fusion-in-Decoder(FiD)架构来识别提示中的重要信息。具体来说,FiD的交叉注意力分数被用于辨别提示中的关键块和句子。R2C有效地捕获了全局上下文,而不会损害语义一致性,同时避免了为训练压缩器而生成伪标签的必要性。经验结果表明,R2C保留了关键上下文,在减少80%提示长度的同时,通过在领域外评估中将LLM性能提高了6%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中由于提示长度过长导致的高计算成本和关键信息模糊问题。现有的提示压缩方法通常难以同时捕获全局上下文和有效地训练压缩器,导致压缩后的提示丢失重要信息,影响LLM的性能。
核心思路:论文的核心思路是利用Fusion-in-Decoder(FiD)架构的多文档阅读能力,通过其交叉注意力机制来识别提示中的重要信息。FiD模型能够同时处理多个文档,并学习它们之间的关系,从而更好地理解全局上下文。通过分析FiD的交叉注意力分数,可以确定提示中哪些部分对最终预测最为重要,进而保留这些关键信息进行压缩。
技术框架:R2C方法主要包含以下几个步骤:1) 将原始提示输入到FiD模型中;2) 利用FiD模型的交叉注意力分数来评估提示中每个chunk或句子的重要性;3) 根据重要性得分选择保留的chunk或句子,形成压缩后的提示;4) 将压缩后的提示输入到LLM中进行下游任务。整个框架无需额外的训练数据或伪标签,可以直接应用于现有的LLM。
关键创新:R2C的关键创新在于利用FiD模型的交叉注意力机制来指导提示压缩,避免了传统方法中需要生成伪标签进行训练的步骤。这种方法能够更有效地捕获全局上下文,并保留提示中的关键信息,从而在压缩提示长度的同时,提升LLM的性能。此外,R2C方法具有通用性,可以应用于不同的LLM和下游任务。
关键设计:论文中,FiD模型采用预训练的T5模型作为backbone。交叉注意力分数的计算方式为:将提示分割成多个chunk或句子,然后计算每个chunk或句子与decoder之间的交叉注意力权重。重要性得分可以简单地定义为交叉注意力权重的平均值或最大值。压缩率可以通过设置一个阈值来控制,只保留重要性得分高于阈值的chunk或句子。
🖼️ 关键图片


📊 实验亮点
实验结果表明,R2C方法在减少80%提示长度的同时,在领域外评估中将LLM的性能提高了6%。这一结果表明,R2C能够有效地保留关键上下文,并在压缩提示长度的同时,提升LLM的泛化能力。此外,R2C方法无需额外的训练数据或伪标签,可以直接应用于现有的LLM,具有很强的实用性。
🎯 应用场景
R2C方法可广泛应用于各种需要使用LLM的场景,尤其是在资源受限或对延迟敏感的应用中,例如移动设备上的智能助手、边缘计算环境下的自然语言处理任务等。通过压缩提示长度,R2C可以降低计算成本、减少延迟,并提高LLM的可用性。此外,R2C还可以用于提高LLM的鲁棒性,使其对噪声和无关信息更加不敏感。
📄 摘要(原文)
Large language models (LLMs) have achieved significant performance gains using advanced prompting techniques over various tasks. However, the increasing length of prompts leads to high computational costs and often obscures crucial information. Prompt compression has been proposed to alleviate these issues, but it faces challenges in (i) capturing the global context and (ii) training the compressor effectively. To tackle these challenges, we introduce a novel prompt compression method, namely Reading To Compressing (R2C), utilizing the Fusion-in-Decoder (FiD) architecture to identify the important information in the prompt. Specifically, the cross-attention scores of the FiD are used to discern essential chunks and sentences from the prompt. R2C effectively captures the global context without compromising semantic consistency while detouring the necessity of pseudo-labels for training the compressor. Empirical results show that R2C retains key contexts, enhancing the LLM performance by 6% in out-of-domain evaluations while reducing the prompt length by 80%.