ActPlan-1K: Benchmarking the Procedural Planning Ability of Visual Language Models in Household Activities
作者: Ying Su, Zhan Ling, Haochen Shi, Jiayang Cheng, Yauwai Yim, Yangqiu Song
分类: cs.CL
发布日期: 2024-10-04
备注: 13 pages, 9 figures, 8 tables, accepted to EMNLP 2024 main conference
💡 一句话要点
ActPlan-1K:用于评估视觉语言模型在家庭活动中程序规划能力的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 程序规划 多模态学习 家庭活动 基准测试
📋 核心要点
- 现有视觉语言模型在处理多模态输入进行程序规划时能力不足,尤其是在家庭活动场景下。
- ActPlan-1K基准旨在评估视觉语言模型在多模态输入和反事实情境下的程序规划能力。
- 实验表明,现有视觉语言模型在生成人类水平的程序计划方面仍有挑战,并提供了自动评估指标。
📝 摘要(中文)
大型语言模型(LLMs)因其强大的推理能力而被广泛应用于处理文本任务描述,并在具身AI任务中完成程序规划。然而,当考虑多模态任务输入时,视觉语言模型(VLMs)的表现如何,目前还缺乏研究。此外,评估模型在替代任务情境下的推理能力的 counterfactual planning 也未得到充分利用。为了评估多模态和 counterfactual 方面的规划能力,我们提出了 ActPlan-1K。ActPlan-1K是一个基于ChatGPT和家庭活动模拟器iGibson2构建的多模态规划基准。该基准包含153项活动和1,187个实例。每个实例描述一项活动,包含自然语言任务描述和来自模拟器的多个环境图像。每个实例的黄金计划是在提供的场景中对对象执行的动作序列。我们在典型的VLM上评估了正确性和常识满足度。结果表明,当前的VLM在为正常活动和 counterfactual 活动生成人类水平的程序计划方面仍然存在困难。我们进一步通过在BLEURT模型上进行微调,提供了自动评估指标,以促进未来对我们基准的研究。
🔬 方法详解
问题定义:现有的大型语言模型在具身AI任务中,主要依赖文本描述进行程序规划,忽略了视觉信息的重要性。视觉语言模型虽然能够处理多模态信息,但在复杂家庭活动场景下的程序规划能力仍有待评估。此外,现有方法缺乏对模型在不同情境下的推理能力(counterfactual planning)的考察。
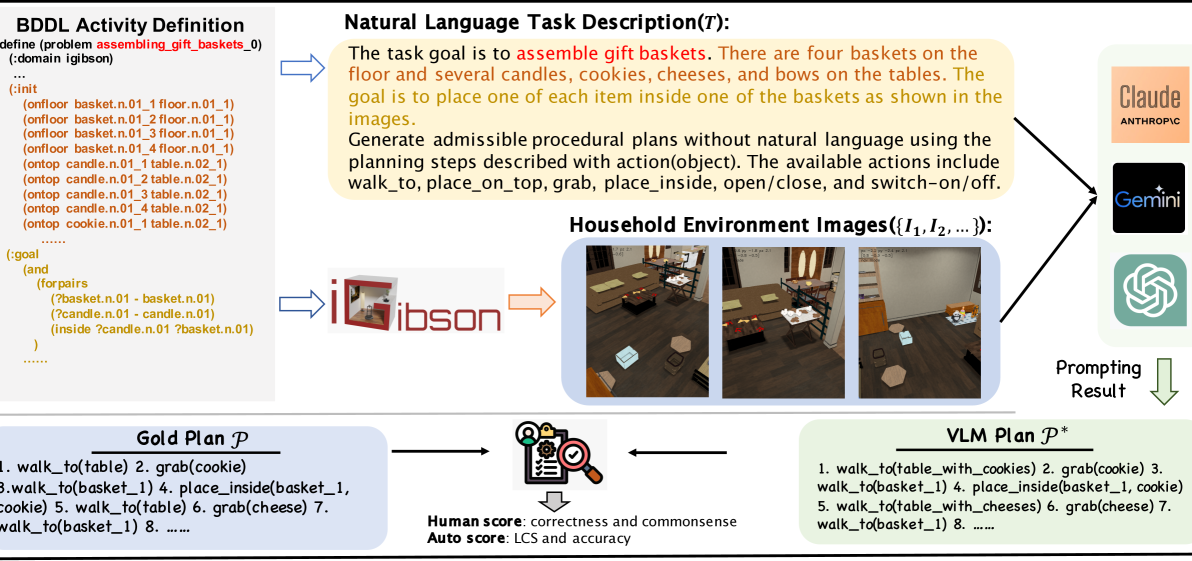
核心思路:ActPlan-1K的核心思路是构建一个包含多模态输入(文本描述和环境图像)的家庭活动程序规划基准,并引入反事实情境,以全面评估视觉语言模型的规划能力。通过提供黄金计划(动作序列),可以定量评估模型生成的计划的正确性和常识性。
技术框架:ActPlan-1K基准的构建主要包含以下几个阶段:1) 活动选择:选择153项常见的家庭活动。2) 实例生成:利用ChatGPT生成1187个活动实例,每个实例包含自然语言任务描述。3) 环境图像生成:使用iGibson2模拟器生成与任务描述相关的环境图像。4) 黄金计划标注:人工标注每个实例的黄金计划,即在给定场景中完成任务所需的动作序列。5) 自动评估指标:通过在BLEURT模型上进行微调,开发自动评估指标,用于评估模型生成的计划的质量。
关键创新:ActPlan-1K的关键创新在于:1) 提出了一个多模态的程序规划基准,包含文本描述和环境图像,更贴近真实场景。2) 引入了反事实情境,可以评估模型在不同情境下的推理能力。3) 提供了自动评估指标,方便未来研究。
关键设计:在数据生成方面,利用ChatGPT生成多样化的任务描述,并使用iGibson2模拟器生成逼真的环境图像。在评估方面,除了人工评估外,还通过微调BLEURT模型,设计了自动评估指标,以提高评估效率和客观性。具体BLEURT微调的参数设置和损失函数等细节,论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的视觉语言模型在ActPlan-1K基准上表现不佳,无法生成人类水平的程序计划。这表明,视觉语言模型在处理复杂多模态输入和进行情境推理方面仍有很大的提升空间。该基准的发布为未来的研究提供了一个有力的工具。
🎯 应用场景
ActPlan-1K基准可用于训练和评估视觉语言模型在家庭服务机器人、智能家居等领域的应用。通过提高模型在复杂环境下的程序规划能力,可以实现更智能、更自主的机器人助手,提升用户体验,并降低人工干预的需求。该基准的发布将促进相关领域的研究进展。
📄 摘要(原文)
Large language models~(LLMs) have been adopted to process textual task description and accomplish procedural planning in embodied AI tasks because of their powerful reasoning ability. However, there is still lack of study on how vision language models~(VLMs) behave when multi-modal task inputs are considered. Counterfactual planning that evaluates the model's reasoning ability over alternative task situations are also under exploited. In order to evaluate the planning ability of both multi-modal and counterfactual aspects, we propose ActPlan-1K. ActPlan-1K is a multi-modal planning benchmark constructed based on ChatGPT and household activity simulator iGibson2. The benchmark consists of 153 activities and 1,187 instances. Each instance describing one activity has a natural language task description and multiple environment images from the simulator. The gold plan of each instance is action sequences over the objects in provided scenes. Both the correctness and commonsense satisfaction are evaluated on typical VLMs. It turns out that current VLMs are still struggling at generating human-level procedural plans for both normal activities and counterfactual activities. We further provide automatic evaluation metrics by finetuning over BLEURT model to facilitate future research on our benchmark.