Towards Reproducible LLM Evaluation: Quantifying Uncertainty in LLM Benchmark Scores
作者: Robert E. Blackwell, Jon Barry, Anthony G. Cohn
分类: cs.CL
发布日期: 2024-10-04 (更新: 2025-06-27)
备注: 4 pages, 1 figure
💡 一句话要点
量化LLM基准测试不确定性,提升评估可复现性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM评估 不确定性量化 可复现性 基准测试
📋 核心要点
- 现有LLM评估benchmark缺乏对模型随机性的考量,导致评估结果的不确定性难以量化。
- 论文提出通过重复实验来量化LLM基准测试中的不确定性,并分析重复次数对评估结果的影响。
- 研究表明,重复实验能够有效降低评估结果的方差,并为LLM评估提供更可靠的置信区间。
📝 摘要(中文)
大型语言模型(LLM)具有随机性,即使在温度设置为零并使用固定随机种子的情况下,并非所有模型都能给出确定性的答案。然而,很少有基准研究尝试量化这种不确定性,部分原因是重复实验的时间和成本。本文使用专门设计用于测试LLM对基本方向推理能力的基准,探讨了重复实验对平均分数和预测区间的影响。我们提出了一种经济高效地量化基准分数不确定性的简单方法,并为可复现的LLM评估提出建议。
🔬 方法详解
问题定义:论文旨在解决LLM基准测试中由于模型随机性导致评估结果不确定性的问题。现有方法通常只进行单次或少数几次实验,无法有效量化评估结果的方差,使得评估结果的可信度和可复现性受到质疑。尤其是在零样本或少样本学习场景下,这种随机性带来的影响更为显著。
核心思路:论文的核心思路是通过多次重复实验,收集LLM在同一基准测试上的多个结果,然后利用统计方法分析这些结果的分布,从而量化评估结果的不确定性。通过计算平均分数和预测区间,可以更准确地评估LLM的性能,并提高评估结果的可信度。这种方法的核心在于通过增加样本量来降低抽样误差,从而更准确地估计总体参数。
技术框架:论文的技术框架主要包括以下几个步骤:1. 选择合适的LLM和基准测试任务(本文选择了测试LLM基本方向推理能力的基准)。2. 设置实验参数,包括温度(temperature)和随机种子(random seed)。3. 对每个LLM在同一基准测试上进行多次重复实验,记录每次实验的结果。4. 使用统计方法分析实验结果,计算平均分数、标准差和预测区间。5. 根据分析结果,提出关于可复现LLM评估的建议。
关键创新:论文的关键创新在于强调了LLM评估中量化不确定性的重要性,并提出了一种简单有效的量化方法。与现有方法相比,该方法不需要复杂的模型或算法,只需要通过增加实验次数即可提高评估结果的可靠性。此外,论文还探讨了重复实验次数与评估结果不确定性之间的关系,为实际应用中选择合适的实验次数提供了参考。
关键设计:论文的关键设计在于选择了一个对LLM随机性较为敏感的基准测试任务,即测试LLM基本方向推理能力的任务。此外,论文还关注了温度和随机种子等实验参数的设置,并建议在评估LLM时固定这些参数,以减少实验结果的方差。在统计分析方面,论文使用了常见的平均分数、标准差和预测区间等指标来量化评估结果的不确定性。
🖼️ 关键图片

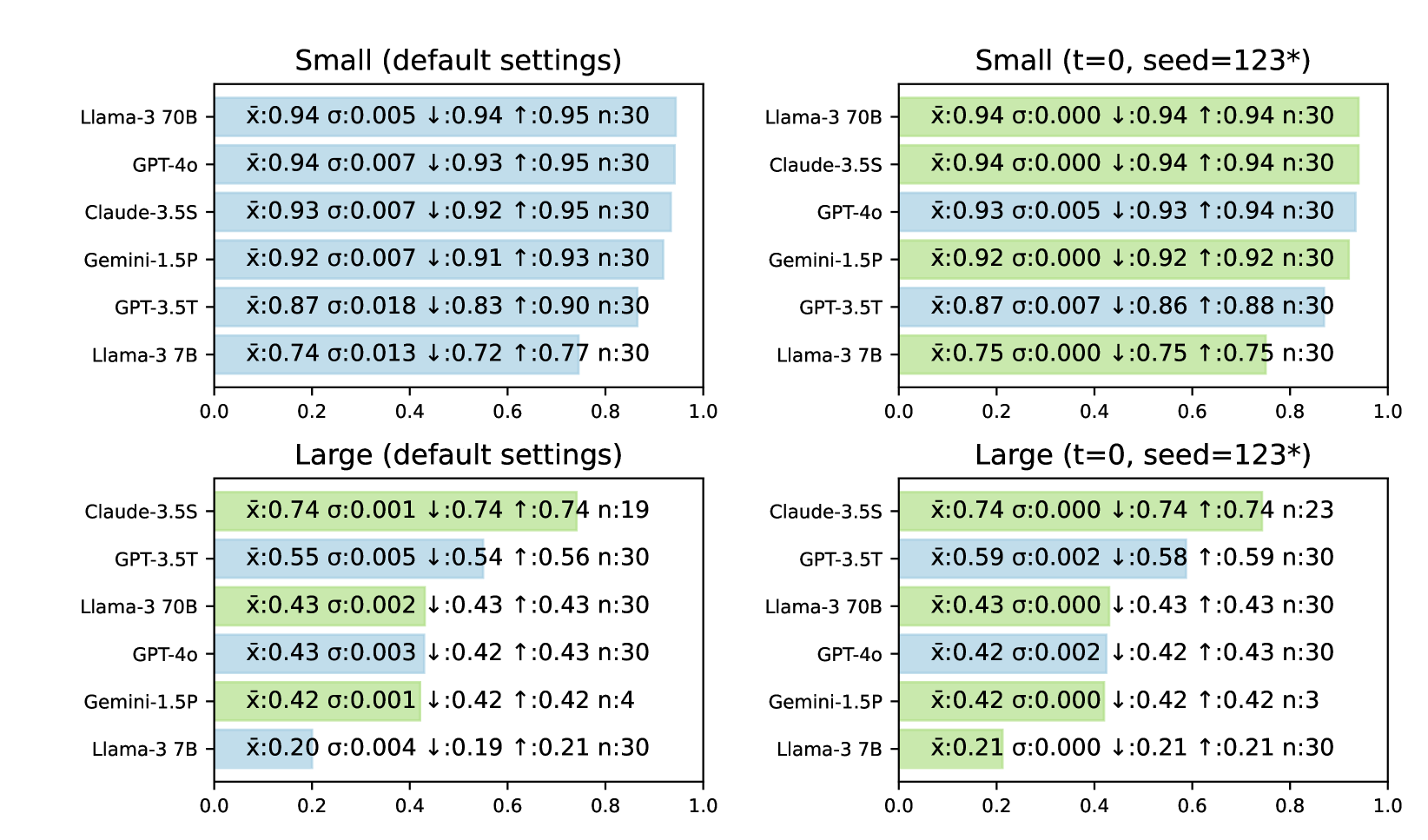

📊 实验亮点
论文通过实验证明,重复实验能够有效降低LLM基准测试结果的方差,并提供更可靠的置信区间。研究结果表明,增加实验次数可以显著提高评估结果的稳定性,从而提高评估结果的可信度。具体性能数据未知,但论文强调了量化不确定性的重要性,并提供了一种简单有效的方法。
🎯 应用场景
该研究成果可应用于各种LLM的评估和选择场景,例如在企业内部选择合适的LLM来完成特定任务,或者在学术界比较不同LLM的性能。通过量化评估结果的不确定性,可以更客观地评估LLM的性能,并避免因随机性导致的误判。此外,该研究还可以为LLM的开发和优化提供指导,例如通过降低模型的随机性来提高其性能的稳定性。
📄 摘要(原文)
Large language models (LLMs) are stochastic, and not all models give deterministic answers, even when setting temperature to zero with a fixed random seed. However, few benchmark studies attempt to quantify uncertainty, partly due to the time and cost of repeated experiments. We use benchmarks designed for testing LLMs' capacity to reason about cardinal directions to explore the impact of experimental repeats on mean score and prediction interval. We suggest a simple method for cost-effectively quantifying the uncertainty of a benchmark score and make recommendations concerning reproducible LLM evaluation.