PersoBench: Benchmarking Personalized Response Generation in Large Language Models
作者: Saleh Afzoon, Usman Naseem, Amin Beheshti, Zahra Jamali
分类: cs.CL
发布日期: 2024-10-04
🔗 代码/项目: GITHUB
💡 一句话要点
PersoBench:用于评估大语言模型个性化回复生成能力的新基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化回复生成 大型语言模型 基准测试 角色感知对话 零样本学习
📋 核心要点
- 现有方法在评估大型语言模型(LLMs)生成个性化回复的能力方面存在不足,缺乏专门的基准测试。
- PersoBench基准通过在零样本设置下,评估LLMs在角色感知对话生成中的个性化能力,填补了这一空白。
- 实验结果表明,LLMs在流畅性和多样性方面表现良好,但在个性化和连贯性方面仍有提升空间,尤其是在考虑上下文和角色信息时。
📝 摘要(中文)
大型语言模型(LLMs)在对话能力方面表现出色,但其在提供个性化回复方面的能力尚不清楚。尽管最近的基准测试使用基于LLM的判断自动评估角色扮演环境中的角色一致性,但对回复生成中个性化的评估仍未得到充分探索。为了解决这个问题,我们提出了一个新的基准PersoBench,用于在零样本设置中评估LLMs在角色感知对话生成中的个性化能力。我们使用知名数据集和一系列指标评估了三个开源和三个闭源LLMs的性能。我们的分析在三个知名的角色感知数据集上进行,评估了回复质量的多个维度,包括流畅性、多样性、连贯性和个性化,涵盖了标准和思维链提示方法。我们的研究结果表明,虽然LLMs擅长生成流畅和多样化的回复,但在提供个性化和连贯的回复方面,考虑到对话上下文和提供的角色,它们还远不能令人满意。我们的基准测试实现可在https://github.com/salehafzoon/PersoBench上找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在个性化回复生成方面的评估问题。现有方法主要关注角色扮演中的角色一致性,而忽略了在对话生成中,LLM能否根据给定的角色信息和对话历史生成真正个性化的回复。现有的评估方法缺乏一个专门的基准来系统地评估LLM的个性化能力,这阻碍了LLM在该方向上的发展。
核心思路:论文的核心思路是构建一个专门的基准测试PersoBench,该基准包含多个角色感知对话数据集,并设计了一系列评估指标,用于衡量LLM生成的回复在流畅性、多样性、连贯性和个性化等多个维度上的表现。通过在PersoBench上评估不同的LLM,可以系统地了解LLM在个性化回复生成方面的优势和不足。
技术框架:PersoBench基准测试主要包含以下几个部分:1) 数据集:使用三个知名的角色感知对话数据集。2) 模型:评估多个开源和闭源的LLM。3) 提示方法:采用标准提示和思维链提示两种方法。4) 评估指标:使用一系列指标来评估回复的流畅性、多样性、连贯性和个性化。整体流程是,首先将数据集输入到LLM中,LLM生成回复,然后使用评估指标对回复进行评估,最后分析评估结果。
关键创新:论文的关键创新在于提出了PersoBench基准测试,这是第一个专门用于评估LLM在个性化回复生成方面能力的基准。该基准不仅包含了多个角色感知对话数据集,还设计了一系列评估指标,可以全面地评估LLM的个性化能力。此外,论文还对多个LLM进行了评估,并分析了它们在个性化回复生成方面的优势和不足。
关键设计:PersoBench的关键设计包括:1) 数据集选择:选择了三个知名的角色感知对话数据集,这些数据集包含了丰富的角色信息和对话历史。2) 评估指标:使用了多种评估指标,包括BLEU、ROUGE、BERTScore等,以及专门用于评估个性化的指标。3) 提示方法:采用了标准提示和思维链提示两种方法,以探索不同的提示方法对LLM性能的影响。4) 模型选择:选择了多个开源和闭源的LLM,以比较不同LLM的性能。
🖼️ 关键图片

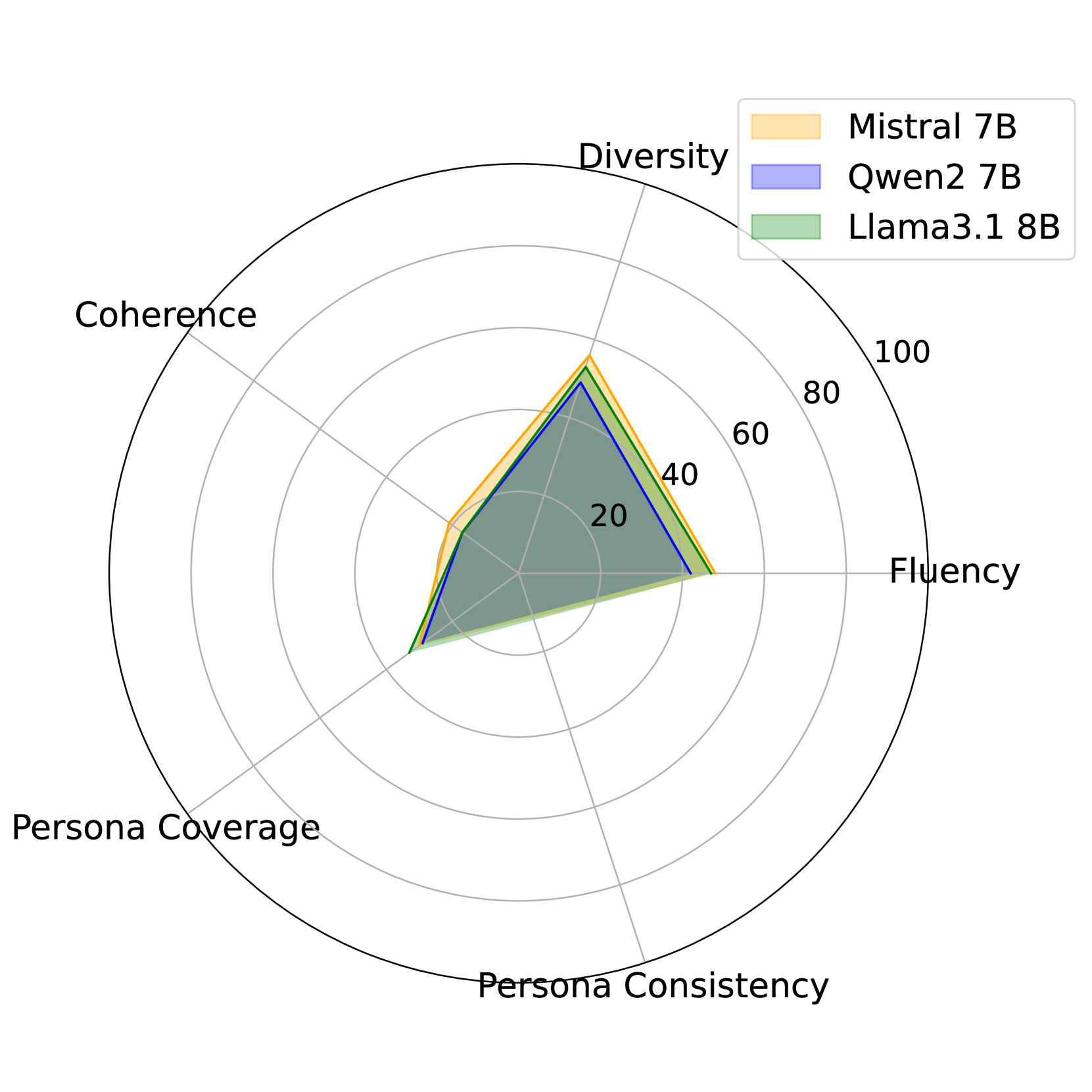
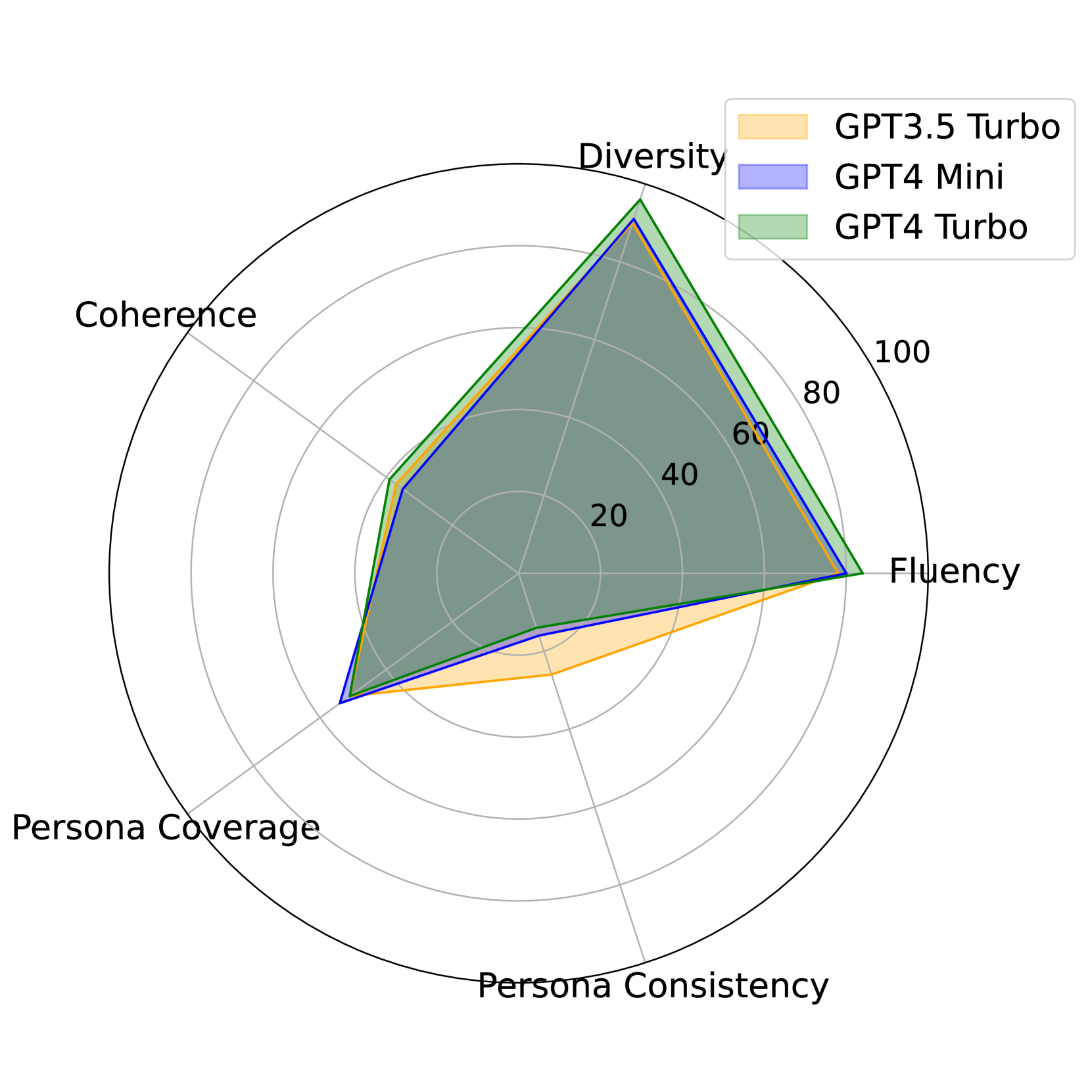
📊 实验亮点
实验结果表明,尽管LLMs在生成流畅和多样化的回复方面表现出色,但在提供个性化和连贯的回复方面仍有不足。具体来说,LLMs在个性化指标上的得分较低,表明它们难以根据给定的角色信息和对话历史生成真正个性化的回复。此外,思维链提示方法在一定程度上可以提高LLMs的个性化能力,但提升幅度有限。
🎯 应用场景
该研究成果可应用于智能对话系统、个性化推荐系统、虚拟助手等领域。通过PersoBench基准,可以更好地评估和提升LLM在生成个性化回复方面的能力,从而提高用户体验和满意度。未来,该基准可以扩展到更多领域和场景,例如医疗、教育等,为构建更加智能和个性化的AI系统提供支持。
📄 摘要(原文)
While large language models (LLMs) have exhibited impressive conversational capabilities, their proficiency in delivering personalized responses remains unclear. Although recent benchmarks automatically evaluate persona consistency in role-playing contexts using LLM-based judgment, the evaluation of personalization in response generation remains underexplored. To address this gap, we present a new benchmark, PersoBench, to evaluate the personalization ability of LLMs in persona-aware dialogue generation within a zero-shot setting. We assess the performance of three open-source and three closed-source LLMs using well-known datasets and a range of metrics. Our analysis, conducted on three well-known persona-aware datasets, evaluates multiple dimensions of response quality, including fluency, diversity, coherence, and personalization, across both standard and chain-of-thought prompting methods. Our findings reveal that while LLMs excel at generating fluent and diverse responses, they are far from satisfactory in delivering personalized and coherent responses considering both the conversation context and the provided personas. Our benchmark implementation is available at https://github.com/salehafzoon/PersoBench.