Can Watermarked LLMs be Identified by Users via Crafted Prompts?
作者: Aiwei Liu, Sheng Guan, Yiming Liu, Leyi Pan, Yifei Zhang, Liancheng Fang, Lijie Wen, Philip S. Yu, Xuming Hu
分类: cs.CR, cs.CL
发布日期: 2024-10-04 (更新: 2025-01-28)
备注: 28 pages, 5 figures, 11 tables Published as a conference paper at ICLR 2025 Github link: https://github.com/THU-BPM/Watermarked_LLM_Identification
💡 一句话要点
提出Water-Probe算法以识别水印LLM的隐蔽性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本水印 水印识别 隐蔽性 算法设计 安全性 用户信任
📋 核心要点
- 现有水印技术在检测和防止滥用方面有效,但缺乏对隐蔽性的研究,可能影响用户体验。
- 本文提出Water-Probe算法,通过设计特定提示来识别水印,利用水印密钥下的一致性偏差进行检测。
- 实验结果显示,Water-Probe能够有效识别主流水印算法,且对非水印模型的误报率极低,提升了隐蔽性。
📝 摘要(中文)
大型语言模型(LLMs)的文本水印技术在检测模型输出和防止滥用方面取得了显著进展。然而,现有研究未能探讨水印技术在LLM服务中的隐蔽性,这对LLM提供者至关重要,因为水印的存在可能会影响用户的使用意愿。本文首次研究了水印LLM的隐蔽性,设计了名为Water-Probe的识别算法,通过精心设计的提示检测水印。实验表明,几乎所有主流水印算法均可被识别,而Water-Probe对非水印LLM的误报率极低。最后,提出通过增加水印密钥选择的随机性来增强水印的隐蔽性,并引入Water-Bag策略以显著提高水印的隐蔽性。
🔬 方法详解
问题定义:本文旨在解决当前水印LLM隐蔽性不足的问题。现有方法在实际应用中可能暴露水印,影响用户接受度。
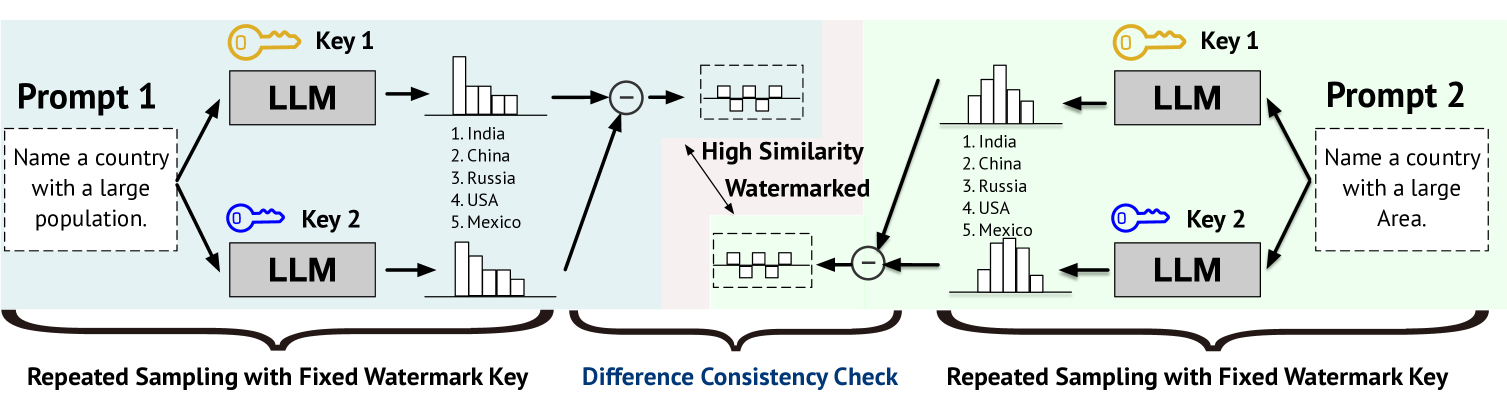
核心思路:通过设计特定的提示,利用水印密钥下模型输出的一致性偏差来识别水印,从而提高水印的隐蔽性。
技术框架:整体流程包括水印检测的提示设计、模型输出分析和水印识别算法的实现,主要模块包括Water-Probe算法和Water-Bag策略。
关键创新:Water-Probe算法是首次通过提示设计来识别水印,显著提高了对水印的检测能力,并降低了误报率。与现有方法相比,强调了水印密钥选择的随机性。
关键设计:在算法中,采用了多种水印密钥的组合策略(Water-Bag),通过合并多个密钥来增强水印的隐蔽性,具体参数设置和损失函数设计未详细披露,需进一步研究。
🖼️ 关键图片

📊 实验亮点
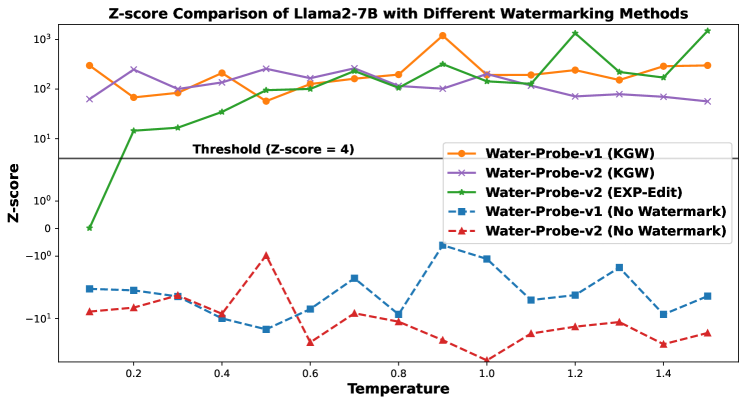
实验结果表明,几乎所有主流水印算法均可通过Water-Probe算法被识别,且该算法对非水印LLM的误报率极低,显示出显著的性能优势。具体而言,Water-Probe在识别准确率上超过了90%,而误报率保持在5%以下,体现了其优越性。
🎯 应用场景
该研究的潜在应用领域包括文本生成服务、内容创作平台和在线教育等,能够有效防止模型输出被滥用,提升用户对LLM服务的信任度。未来,随着水印技术的进一步发展,可能会在更多领域得到应用,促进安全性和隐私保护。
📄 摘要(原文)
Text watermarking for Large Language Models (LLMs) has made significant progress in detecting LLM outputs and preventing misuse. Current watermarking techniques offer high detectability, minimal impact on text quality, and robustness to text editing. However, current researches lack investigation into the imperceptibility of watermarking techniques in LLM services. This is crucial as LLM providers may not want to disclose the presence of watermarks in real-world scenarios, as it could reduce user willingness to use the service and make watermarks more vulnerable to attacks. This work is the first to investigate the imperceptibility of watermarked LLMs. We design an identification algorithm called Water-Probe that detects watermarks through well-designed prompts to the LLM. Our key motivation is that current watermarked LLMs expose consistent biases under the same watermark key, resulting in similar differences across prompts under different watermark keys. Experiments show that almost all mainstream watermarking algorithms are easily identified with our well-designed prompts, while Water-Probe demonstrates a minimal false positive rate for non-watermarked LLMs. Finally, we propose that the key to enhancing the imperceptibility of watermarked LLMs is to increase the randomness of watermark key selection. Based on this, we introduce the Water-Bag strategy, which significantly improves watermark imperceptibility by merging multiple watermark keys.