Margin Matching Preference Optimization: Enhanced Model Alignment with Granular Feedback
作者: Kyuyoung Kim, Ah Jeong Seo, Hao Liu, Jinwoo Shin, Kimin Lee
分类: cs.CL
发布日期: 2024-10-04 (更新: 2025-06-28)
备注: EMNLP 2024 Findings
💡 一句话要点
提出边际匹配偏好优化以解决模型对齐问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对齐技术 边际匹配 强化学习 模型优化 质量评估 实验验证
📋 核心要点
- 现有对齐方法通常依赖简单的二元标签,无法有效捕捉输出之间的相对质量差异。
- 本文提出边际匹配偏好优化(MMPO),通过引入相对质量边际来优化模型策略和奖励模型。
- 实验结果显示,MMPO在多个基准测试中显著优于基线方法,尤其在RewardBench上表现出色。
📝 摘要(中文)
大型语言模型(LLMs)通过人类反馈的强化学习等对齐技术得到了显著发展。然而,现有方法通常依赖简单的二元标签,无法捕捉输出之间的细微质量差异。为了解决这一问题,本文提出了边际匹配偏好优化(MMPO)方法,该方法将相对质量边际纳入优化中,从而改善LLM策略和奖励模型。通过基于Bradley-Terry模型设计软目标概率,并使用标准交叉熵目标进行训练,实验结果表明,MMPO在多个基准测试中表现优于基线方法,尤其是在RewardBench上,7B模型的表现达到了最新的状态,且更具抗过拟合能力。
🔬 方法详解
问题定义:现有的对齐方法在处理输出偏好时,通常只使用简单的二元标签,导致无法充分反映输出之间的细微质量差异。这种方法的局限性影响了模型的整体性能和对齐效果。
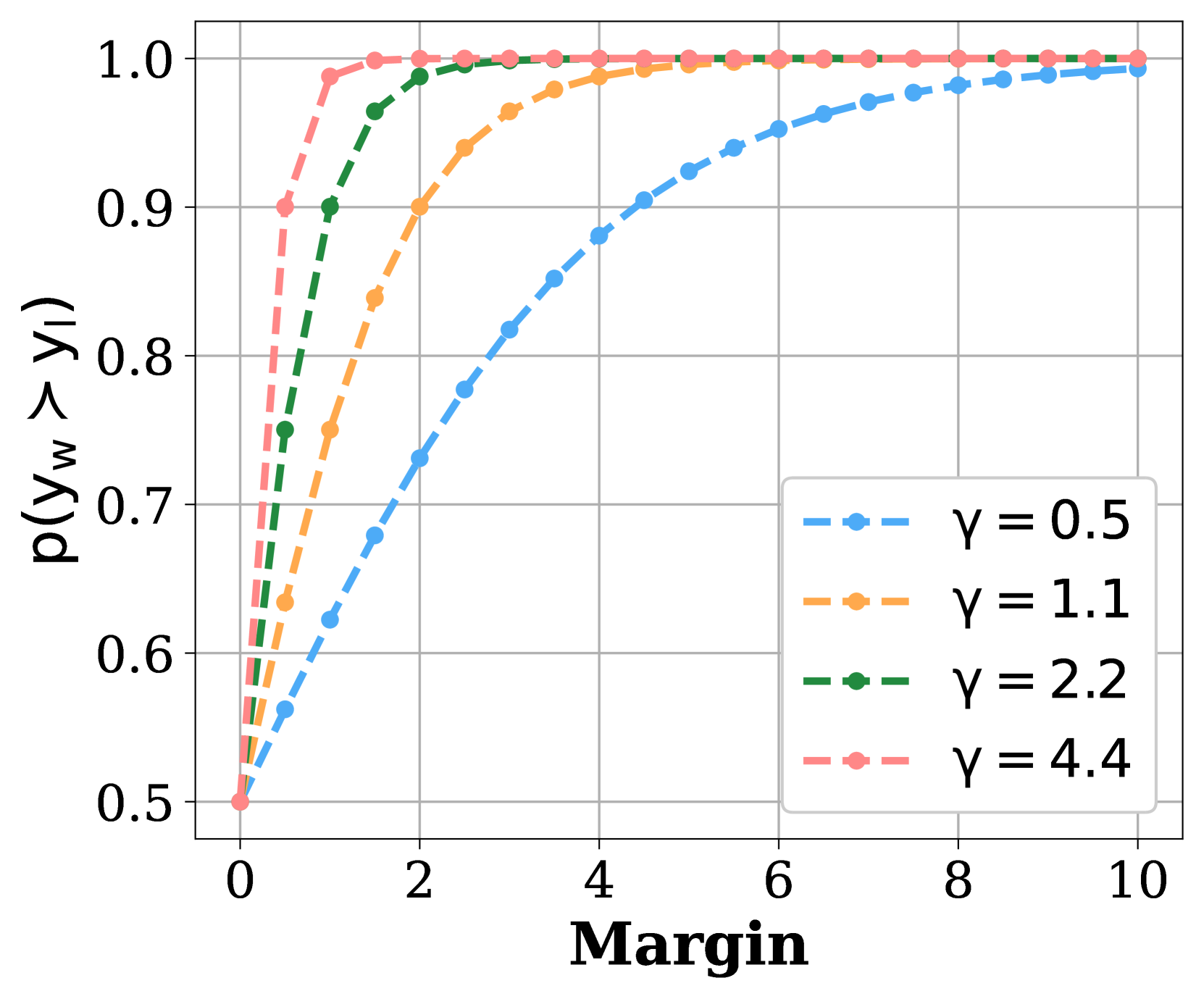
核心思路:本文提出的MMPO方法通过引入相对质量边际,优化模型的策略和奖励模型。具体而言,MMPO利用Bradley-Terry模型设计软目标概率,从而更精确地反映输出的相对质量。
技术框架:MMPO的整体架构包括数据收集、边际计算、软目标概率生成和模型训练四个主要模块。首先,从人类和AI反馈中收集数据,然后计算输出之间的质量边际,接着生成软目标概率,最后使用标准交叉熵目标进行模型训练。
关键创新:MMPO的核心创新在于将相对质量边际纳入优化过程,这与传统方法的二元标签策略形成鲜明对比。通过这种方式,模型能够更好地捕捉输出之间的细微差异,从而提升对齐效果。
关键设计:在模型训练中,MMPO采用了标准的交叉熵损失函数,并通过Bradley-Terry模型计算软目标概率。此外,模型的参数设置经过精心设计,以确保在训练过程中能够有效地反映输出的相对质量。
🖼️ 关键图片

📊 实验亮点
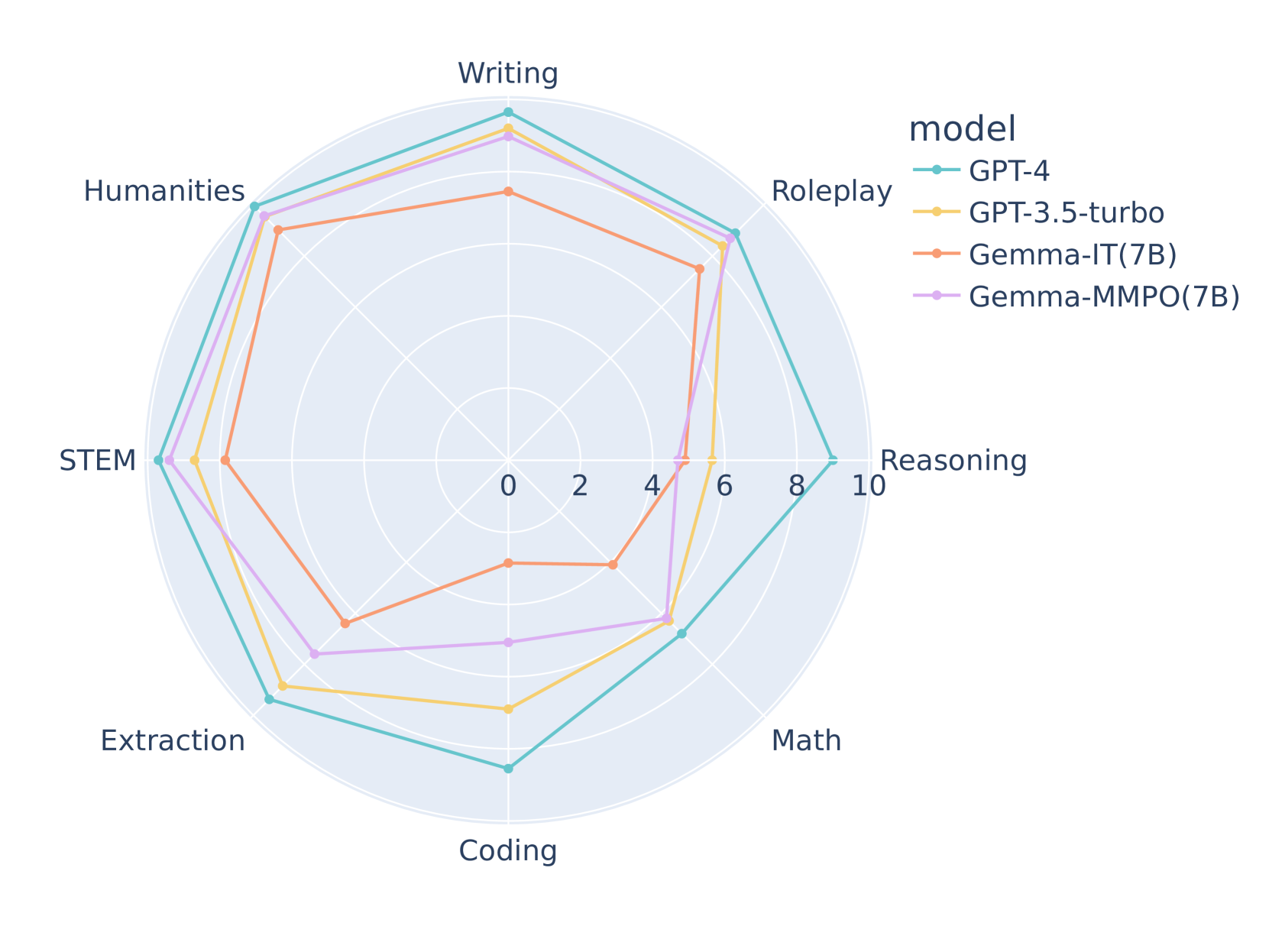
实验结果表明,MMPO在多个基准测试中表现优于基线方法,尤其是在RewardBench上,7B模型的性能达到了最新的状态,超越了同规模的其他模型。此外,MMPO展现出更强的抗过拟合能力,导致模型的校准效果更佳。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和推荐系统等。通过提升模型对齐效果,MMPO能够帮助构建更智能的AI系统,改善用户体验,并在多种实际场景中发挥重要作用。未来,随着技术的不断发展,MMPO可能会在更多领域中得到应用,推动AI技术的进一步进步。
📄 摘要(原文)
Large language models (LLMs) fine-tuned with alignment techniques, such as reinforcement learning from human feedback, have been instrumental in developing some of the most capable AI systems to date. Despite their success, existing methods typically rely on simple binary labels, such as those indicating preferred outputs in pairwise preferences, which fail to capture the subtle differences in relative quality between pairs. To address this limitation, we introduce an approach called Margin Matching Preference Optimization (MMPO), which incorporates relative quality margins into optimization, leading to improved LLM policies and reward models. Specifically, given quality margins in pairwise preferences, we design soft target probabilities based on the Bradley-Terry model, which are then used to train models with the standard cross-entropy objective. Experiments with both human and AI feedback data demonstrate that MMPO consistently outperforms baseline methods, often by a substantial margin, on popular benchmarks including MT-bench and RewardBench. Notably, the 7B model trained with MMPO achieves state-of-the-art performance on RewardBench as of June 2024, outperforming other models of the same scale. Our analysis also shows that MMPO is more robust to overfitting, leading to better-calibrated models.