SAG: Style-Aligned Article Generation via Model Collaboration
作者: Chenning Xu, Fangxun Shu, Dian Jin, Jinghao Wei, Hao Jiang
分类: cs.CL
发布日期: 2024-10-04
💡 一句话要点
提出SAG:一种基于模型协作的风格对齐文章生成方法,显著提升生成质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 风格化生成 模型协作 大型语言模型 小型语言模型 监督微调 自我改进 指令遵循
📋 核心要点
- 现有大型语言模型在风格化内容生成方面存在局限性,闭源模型优化受限,开源模型训练成本高昂。
- 论文提出一种协作训练框架SAG,冻结大型语言模型,微调小型语言模型,并引入自我改进方法。
- 实验结果表明,该方法在风格对齐文章生成方面取得了显著提升,ROUGE-L和BLEU-4指标均优于GPT-4。
📝 摘要(中文)
大型语言模型(LLMs)的兴起增加了对个性化和风格化内容生成的需求。然而,像GPT-4这样的闭源模型在优化机会方面存在局限性,而像Qwen-72B这样的开源替代方案,其巨大的训练成本和不灵活性也带来了相当大的挑战。另一方面,小型语言模型(SLMs)在理解复杂指令和将学习能力转移到新环境中存在困难,通常表现出更明显的局限性。本文提出了一种新颖的协作训练框架,利用LLM和SLM的优势进行风格化文章生成,超越了单独使用任何一种模型的性能。我们冻结LLM以利用其强大的指令遵循能力,然后使用特定风格的数据对SLM进行监督微调。此外,我们引入了一种自我改进方法来增强风格一致性。我们新的基准测试NoteBench全面评估了风格对齐生成。大量实验表明,我们的方法实现了最先进的性能,与GPT-4相比,ROUGE-L提高了0.78,BLEU-4提高了0.55,同时保持了较低的事实性和忠实性幻觉率。
🔬 方法详解
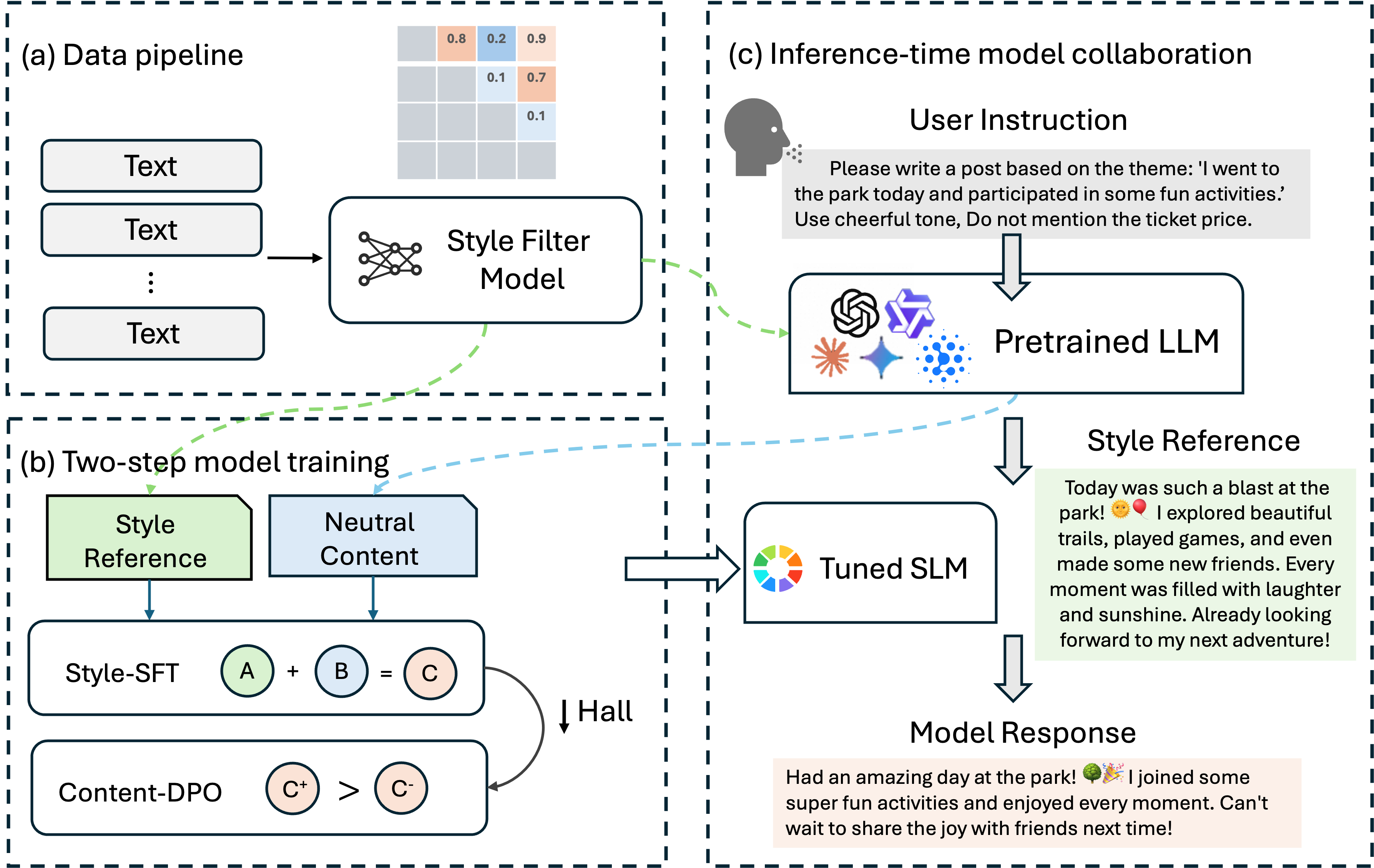
问题定义:论文旨在解决风格化文章生成的问题。现有方法,特别是直接使用大型语言模型或小型语言模型,在风格控制、生成质量和训练成本之间难以取得平衡。大型语言模型虽然能力强大,但闭源模型难以优化,开源模型训练成本高昂。小型语言模型虽然训练成本较低,但在理解复杂指令和风格迁移方面存在不足。
核心思路:论文的核心思路是利用大型语言模型和小型语言模型的优势,通过协作训练的方式实现高质量的风格化文章生成。具体来说,利用大型语言模型强大的指令遵循能力,指导小型语言模型进行风格学习,同时避免直接训练大型语言模型带来的高昂成本。
技术框架:整体框架包含以下几个主要阶段:1) LLM冻结与指导:冻结大型语言模型,利用其强大的指令理解能力生成风格化的训练数据。2) SLM监督微调:使用风格特定的数据对小型语言模型进行监督微调,使其学习目标风格。3) 自我改进:引入自我改进机制,通过迭代优化,进一步提升生成文章的风格一致性。
关键创新:论文的关键创新在于提出了一种基于模型协作的训练框架,将大型语言模型的指令遵循能力与小型语言模型的快速适应能力相结合。此外,引入的自我改进机制能够有效提升生成文章的风格一致性,这是现有方法中较少关注的。
关键设计:论文的关键设计包括:1) 风格数据构建:使用大型语言模型生成高质量的风格化训练数据,用于指导小型语言模型的学习。2) 监督微调策略:采用合适的监督微调策略,使小型语言模型能够有效地学习目标风格。3) 自我改进机制:设计合适的奖励函数和优化算法,鼓励小型语言模型生成更符合目标风格的文章。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在NoteBench基准测试上取得了显著的性能提升,与GPT-4相比,ROUGE-L提高了0.78,BLEU-4提高了0.55,同时保持了较低的事实性和忠实性幻觉率。这些数据表明,该方法在风格对齐文章生成方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于个性化内容生成、营销文案创作、新闻报道风格转换等领域。通过风格对齐的文章生成,可以满足用户对特定风格内容的需求,提高内容生成的效率和质量,并为内容创作带来新的可能性。未来,该方法有望应用于更多语言和风格,并与其他技术相结合,实现更智能化的内容生成。
📄 摘要(原文)
Large language models (LLMs) have increased the demand for personalized and stylish content generation. However, closed-source models like GPT-4 present limitations in optimization opportunities, while the substantial training costs and inflexibility of open-source alternatives, such as Qwen-72B, pose considerable challenges. Conversely, small language models (SLMs) struggle with understanding complex instructions and transferring learned capabilities to new contexts, often exhibiting more pronounced limitations. In this paper, we present a novel collaborative training framework that leverages the strengths of both LLMs and SLMs for style article generation, surpassing the performance of either model alone. We freeze the LLMs to harness their robust instruction-following capabilities and subsequently apply supervised fine-tuning on the SLM using style-specific data. Additionally, we introduce a self-improvement method to enhance style consistency. Our new benchmark, NoteBench, thoroughly evaluates style-aligned generation. Extensive experiments show that our approach achieves state-of-the-art performance, with improvements of 0.78 in ROUGE-L and 0.55 in BLEU-4 scores compared to GPT-4, while maintaining a low hallucination rate regarding factual and faithfulness.