Visual Editing with LLM-based Tool Chaining: An Efficient Distillation Approach for Real-Time Applications
作者: Oren Sultan, Alex Khasin, Guy Shiran, Asnat Greenstein-Messica, Dafna Shahaf
分类: cs.CL, cs.AI
发布日期: 2024-10-03 (更新: 2024-10-10)
备注: EMNLP 2024
💡 一句话要点
提出一种基于LLM工具链的视觉编辑蒸馏方法,用于实时应用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉编辑 LLM 知识蒸馏 实时应用 工具链
📋 核心要点
- 现有大型LLM在视觉编辑任务中表现出色,但成本高、延迟大,难以满足实时应用需求。
- 采用蒸馏方法,利用大型教师LLM指导训练小型学生LLM,使其在保证性能的同时降低成本和延迟。
- 实验表明,学生模型能够匹配教师模型的性能,并且通过数据增强,在低数据情况下微调效果提升25%。
📝 摘要(中文)
本文提出了一种实用的蒸馏方法,用于微调LLM,使其能够在实时应用中调用工具。研究重点是视觉编辑任务,具体而言,通过解释用户以自然语言表达的风格请求(例如“黄金时段”),利用LLM选择合适的工具及其参数,以实现所需的视觉效果,从而修改图像和视频。研究发现,GPT-3.5-Turbo等专有LLM在此任务中显示出潜力,但其高成本和延迟使其不适合实时应用。该方法使用较大的教师LLM和行为信号来指导微调较小的学生LLM。引入了离线指标来评估学生LLM。在线和离线实验均表明,学生模型能够匹配教师模型(GPT-3.5-Turbo)的性能,从而显著降低成本和延迟。最后,研究表明,使用数据增强可以在低数据情况下将微调效果提高25%。
🔬 方法详解
问题定义:论文旨在解决视觉编辑任务中,大型语言模型(LLM)成本高、延迟大的问题,使其难以应用于实时场景。现有方法直接使用大型LLM进行推理,虽然效果好,但计算资源消耗大,响应速度慢,无法满足实时性要求。
核心思路:论文的核心思路是知识蒸馏,即利用一个性能优越但计算开销大的教师模型(GPT-3.5-Turbo)来指导训练一个较小的学生模型。学生模型学习教师模型的行为,从而在保证性能的同时,显著降低计算成本和延迟。
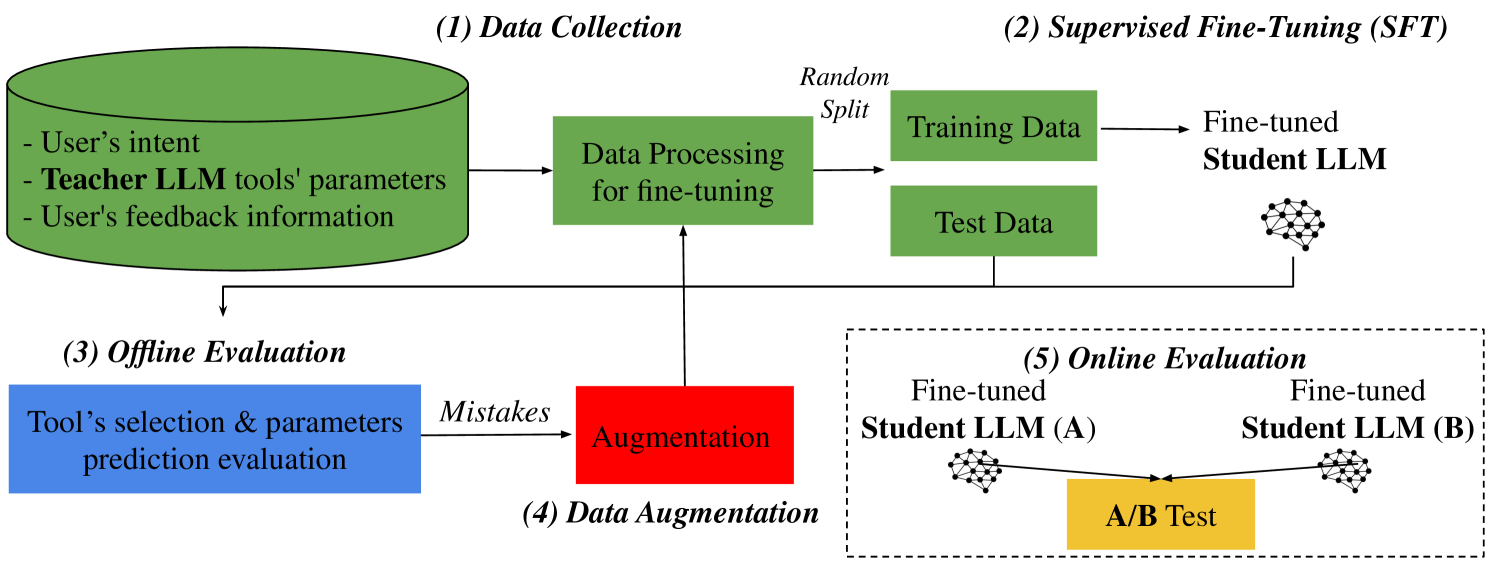
技术框架:整体框架包含以下几个主要阶段: 1. 数据生成:使用教师LLM处理用户输入的自然语言风格请求,生成相应的工具调用序列和参数。 2. 学生模型训练:使用生成的数据集对学生LLM进行微调,使其学习教师LLM的工具选择和参数设置策略。 3. 离线评估:设计离线指标评估学生LLM的性能,例如工具选择准确率、参数预测误差等。 4. 在线评估:在实际应用场景中测试学生LLM的性能,评估其延迟和用户体验。
关键创新:论文的关键创新在于针对视觉编辑任务,提出了一种有效的LLM蒸馏方法,并设计了相应的离线评估指标。此外,论文还探索了数据增强技术,以提高在低数据情况下的微调效果。与直接使用大型LLM相比,该方法能够在保证性能的前提下,显著降低成本和延迟。
关键设计:论文的关键设计包括: 1. 教师模型选择:选择GPT-3.5-Turbo作为教师模型,因为它在视觉编辑任务中表现出色。 2. 学生模型选择:选择一个较小的LLM作为学生模型,以降低计算成本和延迟。 3. 损失函数设计:使用交叉熵损失函数来训练学生模型,使其学习教师模型的工具选择策略。 4. 数据增强策略:采用数据增强技术,例如随机替换、同义词替换等,以提高在低数据情况下的微调效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过蒸馏的学生模型能够匹配教师模型GPT-3.5-Turbo的性能,同时显著降低了成本和延迟。此外,在低数据情况下,通过数据增强,微调效果提高了25%。这些结果验证了该方法的有效性和实用性。
🎯 应用场景
该研究成果可应用于各种实时视觉编辑应用,例如实时图像风格迁移、视频特效处理、智能图像增强等。通过降低LLM的计算成本和延迟,可以将其部署在移动设备或边缘服务器上,为用户提供更快速、更便捷的视觉编辑体验。该技术还有潜力应用于其他需要实时响应的自然语言处理任务。
📄 摘要(原文)
We present a practical distillation approach to fine-tune LLMs for invoking tools in real-time applications. We focus on visual editing tasks; specifically, we modify images and videos by interpreting user stylistic requests, specified in natural language ("golden hour"), using an LLM to select the appropriate tools and their parameters to achieve the desired visual effect. We found that proprietary LLMs such as GPT-3.5-Turbo show potential in this task, but their high cost and latency make them unsuitable for real-time applications. In our approach, we fine-tune a (smaller) student LLM with guidance from a (larger) teacher LLM and behavioral signals. We introduce offline metrics to evaluate student LLMs. Both online and offline experiments show that our student models manage to match the performance of our teacher model (GPT-3.5-Turbo), significantly reducing costs and latency. Lastly, we show that fine-tuning was improved by 25% in low-data regimes using augmentation.