Better Instruction-Following Through Minimum Bayes Risk
作者: Ian Wu, Patrick Fernandes, Amanda Bertsch, Seungone Kim, Sina Pakazad, Graham Neubig
分类: cs.CL, cs.AI
发布日期: 2024-10-03 (更新: 2025-02-25)
备注: Accepted to ICLR 2025 (Spotlight); Camera Ready
💡 一句话要点
通过最小贝叶斯风险提升指令跟随能力,并利用自训练降低推理成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令跟随 大型语言模型 最小贝叶斯风险 LLM评判器 自训练 直接偏好优化 AlpacaEval MT-Bench
📋 核心要点
- 现有指令跟随LLM的评估和改进面临挑战,需要更有效的方法来提升其性能。
- 本文提出使用最小贝叶斯风险解码,利用LLM评判器从候选输出中选择高质量的输出。
- 实验表明,MBR解码显著提升了LLM在AlpacaEval和MT-Bench上的性能,且自训练能进一步提升效率。
📝 摘要(中文)
本文提出利用最小贝叶斯风险(MBR)解码来提升指令跟随大型语言模型(LLM)的性能。研究表明,使用基于参考的LLM评判器进行MBR解码,在AlpacaEval和MT-Bench上,相比于贪婪解码、使用无参考评判器的best-of-N解码以及使用词汇和嵌入式度量的MBR解码,性能均有显著提升。这些提升在参数高达70B的LLM上保持一致,表明较小的LLM评判器可以用来监督更大的LLM。为了在保留MBR解码带来的性能提升的同时,降低额外的测试时间成本,本文探索了在MBR解码输出上进行迭代自训练。结果表明,使用直接偏好优化(Direct Preference Optimisation)进行自训练可以带来显著的性能提升,使得自训练模型使用贪婪解码通常能够匹配甚至超过其基础模型使用MBR解码的性能。
🔬 方法详解
问题定义:论文旨在解决如何提升指令跟随LLM的性能,并降低推理成本的问题。现有方法,如贪婪解码和best-of-N解码,在生成高质量输出方面存在局限性。同时,使用大型LLM进行推理的计算成本很高,限制了其在实际应用中的部署。
核心思路:论文的核心思路是利用最小贝叶斯风险(MBR)解码,结合LLM评判器,选择一组候选输出中质量最高的输出。MBR解码通过最小化预期风险来选择最优输出,而LLM评判器则提供了一种可扩展且准确的评估方法。此外,通过自训练,可以将MBR解码带来的性能提升转移到更高效的贪婪解码模型中。
技术框架:整体框架包含两个主要阶段:1) 使用MBR解码提升性能:首先,为每个输入生成N个候选输出。然后,使用LLM评判器对这些候选输出进行评估,并使用MBR解码选择最佳输出。2) 使用自训练降低推理成本:在MBR解码生成的输出上进行自训练,使用直接偏好优化(DPO)来训练模型,使其能够使用贪婪解码生成高质量的输出。
关键创新:最重要的技术创新点在于结合了MBR解码和LLM评判器,以及利用自训练将性能提升转移到更高效的解码方法上。与传统的基于词汇或嵌入的度量相比,LLM评判器能够更准确地评估输出的质量。自训练则允许在不增加推理成本的情况下,获得与MBR解码相当甚至更好的性能。
关键设计:关键设计包括:1) LLM评判器的选择和prompt设计,确保其能够准确评估输出的质量。2) MBR解码中的风险函数设计,通常使用负的LLM评判器得分作为风险。3) 自训练中使用直接偏好优化(DPO),DPO是一种高效的偏好学习方法,可以直接优化模型的策略,使其生成更符合人类偏好的输出。
🖼️ 关键图片
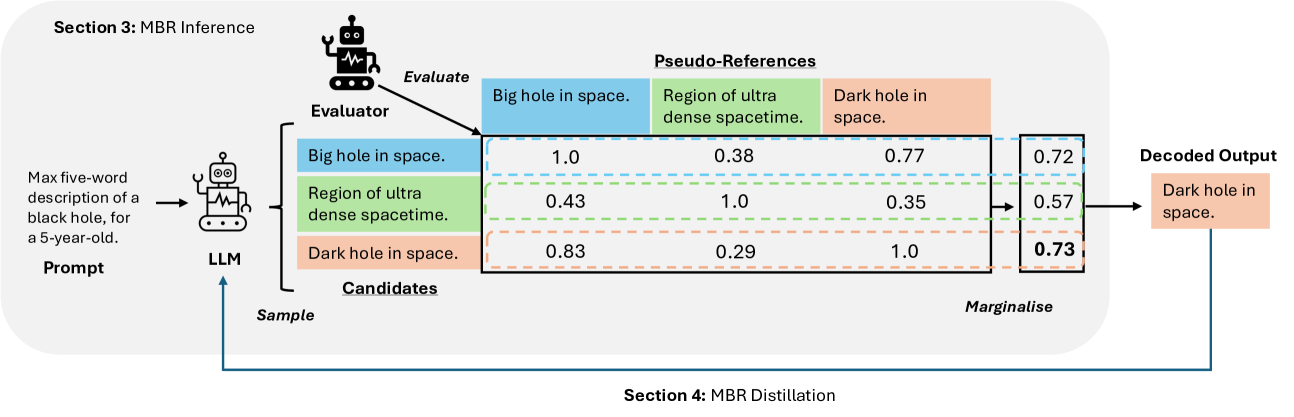

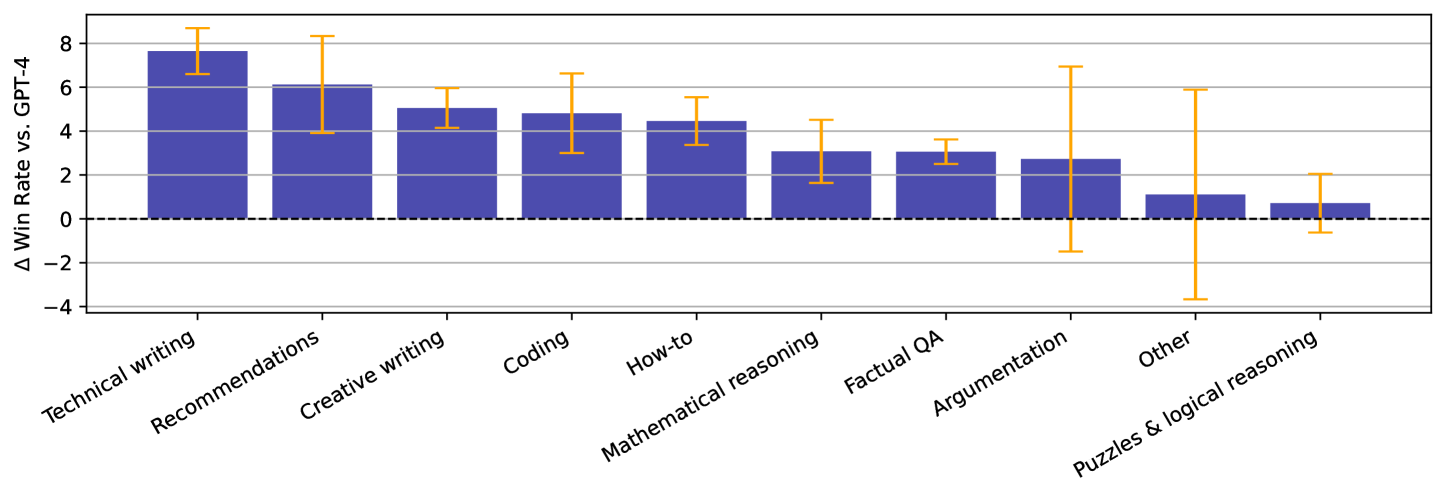
📊 实验亮点
实验结果表明,使用基于参考的LLM评判器进行MBR解码,在AlpacaEval和MT-Bench上,相比于贪婪解码、使用无参考评判器的best-of-N解码以及使用词汇和嵌入式度量的MBR解码,性能均有显著提升。通过自训练,模型在使用贪婪解码时,通常能够匹配甚至超过其基础模型使用MBR解码的性能,从而在不增加推理成本的情况下,获得更高的性能。
🎯 应用场景
该研究成果可应用于各种需要高质量指令跟随的场景,例如智能助手、聊天机器人、代码生成等。通过MBR解码和自训练,可以提升这些应用在复杂任务上的性能,并降低部署成本,使其更易于在资源受限的环境中使用。未来的研究可以探索如何进一步优化LLM评判器和自训练方法,以获得更好的性能和效率。
📄 摘要(原文)
General-purpose LLM judges capable of human-level evaluation provide not only a scalable and accurate way of evaluating instruction-following LLMs but also new avenues for supervising and improving their performance. One promising way of leveraging LLM judges for supervision is through Minimum Bayes Risk (MBR) decoding, which uses a reference-based evaluator to select a high-quality output from amongst a set of candidate outputs. In the first part of this work, we explore using MBR decoding as a method for improving the test-time performance of instruction-following LLMs. We find that MBR decoding with reference-based LLM judges substantially improves over greedy decoding, best-of-N decoding with reference-free judges and MBR decoding with lexical and embedding-based metrics on AlpacaEval and MT-Bench. These gains are consistent across LLMs with up to 70B parameters, demonstrating that smaller LLM judges can be used to supervise much larger LLMs. Then, seeking to retain the improvements from MBR decoding while mitigating additional test-time costs, we explore iterative self-training on MBR-decoded outputs. We find that self-training using Direct Preference Optimisation leads to significant performance gains, such that the self-trained models with greedy decoding generally match and sometimes exceed the performance of their base models with MBR decoding.