Position: LLM Unlearning Benchmarks are Weak Measures of Progress
作者: Pratiksha Thaker, Shengyuan Hu, Neil Kale, Yash Maurya, Zhiwei Steven Wu, Virginia Smith
分类: cs.CL
发布日期: 2024-10-03 (更新: 2025-04-08)
备注: Appears in IEEE Secure and Trustworthy Machine Learning (SaTML) '25
💡 一句话要点
LLM卸载基准测试存在缺陷,无法有效衡量卸载进展
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM卸载 基准测试 隐私保护 安全 模型评估
📋 核心要点
- 现有LLM卸载基准测试存在缺陷,无法准确评估卸载方法的有效性,可能导致对卸载能力的过度乐观估计。
- 通过对现有基准进行简单修改,论文揭示了卸载方法在处理忘记信息和保留信息之间存在依赖关系时的脆弱性。
- 研究表明,现有基准中卸载目标的不明确性可能导致方法过度拟合测试查询,从而影响泛化能力。
📝 摘要(中文)
卸载方法有潜力通过事后移除敏感或有害信息来提高大型语言模型(LLM)的隐私和安全性。LLM卸载研究领域越来越倾向于使用经验基准来评估此类方法的有效性。本文发现,现有基准对候选卸载方法的有效性提供了过于乐观且可能具有误导性的看法。通过对一些流行的基准进行简单、良性的修改,我们揭示了据称已卸载的信息仍然可以访问,或者卸载过程对模型在保留信息上的性能的降低程度远大于原始基准所指示的情况。我们发现,现有基准特别容易受到修改的影响,这些修改甚至在忘记和保留的信息之间引入了松散的依赖关系。此外,我们表明,现有基准中卸载目标的不明确性很容易导致设计出的方法过度拟合给定的测试查询。基于我们的发现,我们敦促社区在将基准测试结果解释为可靠的进展衡量标准时保持谨慎,并提供了一些建议来指导未来的LLM卸载研究。
🔬 方法详解
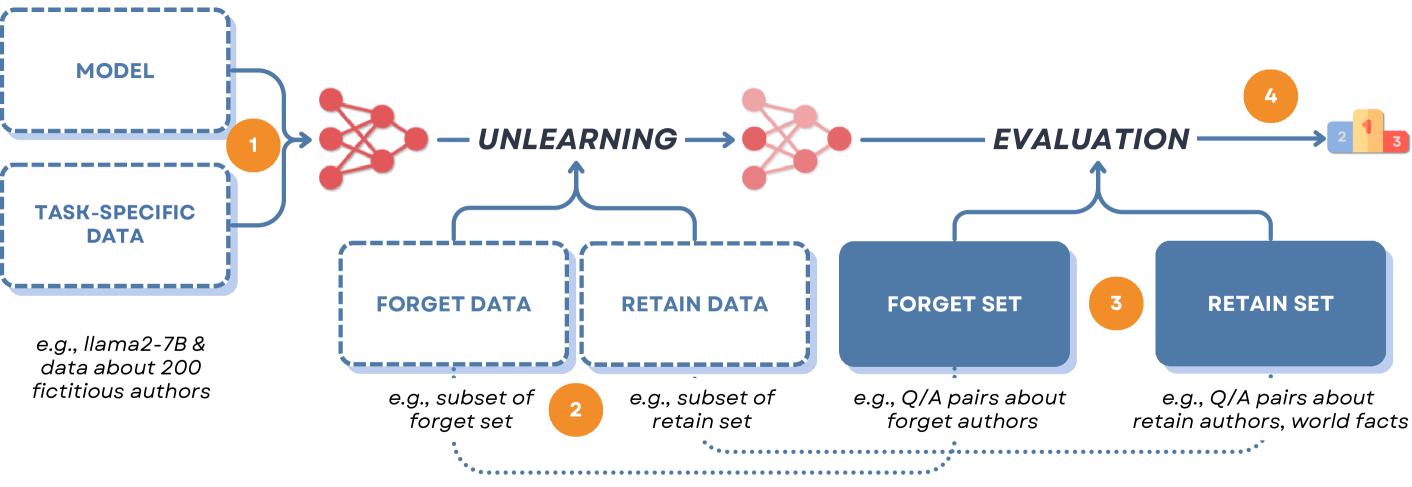
问题定义:现有的大型语言模型(LLM)卸载基准测试被广泛用于评估各种卸载方法的有效性。然而,这些基准测试可能无法真实反映卸载方法的实际性能,因为它们容易受到简单修改的影响,并且可能无法捕捉到忘记信息和保留信息之间的复杂依赖关系。现有方法的痛点在于,它们依赖于可能存在偏差或漏洞的基准测试,从而导致对卸载效果的误判。
核心思路:论文的核心思路是通过对现有基准测试进行简单而良性的修改,来暴露这些基准测试的弱点,并证明现有的卸载方法可能无法真正删除目标信息。通过引入这些修改,研究人员可以评估卸载方法在更具挑战性的场景下的表现,并更好地理解其局限性。这种方法旨在促使社区重新评估现有的卸载评估方法,并开发更可靠的基准测试。
技术框架:该研究没有提出新的卸载方法,而是侧重于评估现有卸载方法的有效性。其框架主要包括以下几个步骤:1) 选择现有的LLM卸载基准测试;2) 对这些基准测试进行简单修改,例如引入忘记信息和保留信息之间的松散依赖关系;3) 使用现有的卸载方法在修改后的基准测试上进行实验;4) 分析实验结果,评估卸载方法在修改后的基准测试上的表现,并与原始基准测试上的表现进行比较;5) 总结发现,并提出改进LLM卸载评估的建议。
关键创新:该研究的关键创新在于其对现有LLM卸载基准测试的批判性评估。通过揭示这些基准测试的弱点,该研究挑战了社区对现有卸载方法有效性的普遍看法。该研究还强调了在评估卸载方法时考虑忘记信息和保留信息之间依赖关系的重要性。
关键设计:论文的关键设计在于对现有基准测试的修改方式。这些修改旨在引入忘记信息和保留信息之间的松散依赖关系,或者增加卸载目标的不明确性。例如,可以通过将忘记信息与保留信息以某种方式关联起来,或者通过提供多个可能的卸载目标来增加卸载的难度。这些修改的设计需要仔细考虑,以确保它们既简单又有效,并且能够真实反映实际应用中可能遇到的挑战。
🖼️ 关键图片


📊 实验亮点
研究发现,对现有基准进行简单修改后,现有卸载方法的效果显著下降,甚至无法有效删除目标信息。例如,在引入忘记信息和保留信息之间的依赖关系后,模型的性能下降幅度远大于原始基准测试所显示的。这表明现有基准测试可能高估了卸载方法的实际能力。
🎯 应用场景
该研究成果对LLM的隐私保护和安全应用具有重要意义。更可靠的卸载评估方法能够帮助开发者选择和优化卸载算法,从而降低LLM泄露敏感信息的风险,提升模型在金融、医疗等领域的应用安全性。同时,该研究也为未来LLM卸载基准测试的设计提供了指导。
📄 摘要(原文)
Unlearning methods have the potential to improve the privacy and safety of large language models (LLMs) by removing sensitive or harmful information post hoc. The LLM unlearning research community has increasingly turned toward empirical benchmarks to assess the effectiveness of such methods. In this paper, we find that existing benchmarks provide an overly optimistic and potentially misleading view on the effectiveness of candidate unlearning methods. By introducing simple, benign modifications to a number of popular benchmarks, we expose instances where supposedly unlearned information remains accessible, or where the unlearning process has degraded the model's performance on retained information to a much greater extent than indicated by the original benchmark. We identify that existing benchmarks are particularly vulnerable to modifications that introduce even loose dependencies between the forget and retain information. Further, we show that ambiguity in unlearning targets in existing benchmarks can easily lead to the design of methods that overfit to the given test queries. Based on our findings, we urge the community to be cautious when interpreting benchmark results as reliable measures of progress, and we provide several recommendations to guide future LLM unlearning research.