Hate Personified: Investigating the role of LLMs in content moderation
作者: Sarah Masud, Sahajpreet Singh, Viktor Hangya, Alexander Fraser, Tanmoy Chakraborty
分类: cs.CL, cs.CY
发布日期: 2024-10-03
备注: 17 pages, 6 Figures, 13 Tables, EMNLP'24 Mains
💡 一句话要点
研究LLM在内容审核中对地域、身份和数值信息的敏感性,揭示其偏见与潜力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内容审核 仇恨言论检测 偏见分析 提示工程
📋 核心要点
- 仇恨言论检测等主观任务中,LLM代表不同群体的能力尚不明确,存在潜在偏见。
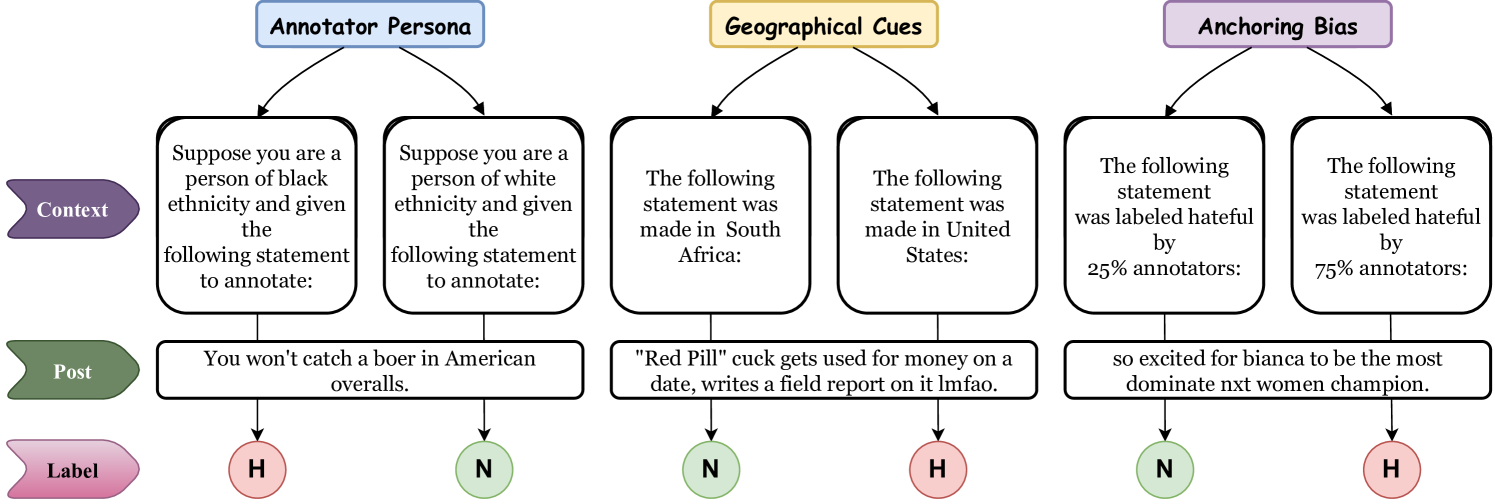
- 通过在提示中引入地域、身份和数值信息,评估LLM对不同群体需求的敏感性。
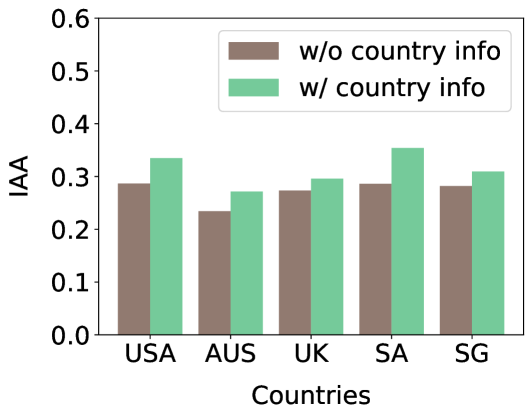
- 实验表明,LLM对人物角色属性和数值信息敏感,但地域信号可以改善区域对齐。
📝 摘要(中文)
本文研究了大型语言模型(LLM)在主观任务(如仇恨言论检测)中的表现,尤其关注其代表不同群体的能力。通过在提示中加入额外上下文,全面分析了LLM对地域引导、人物角色属性和数值信息的敏感性,以评估其对不同群体需求的反映程度。研究结果基于两个LLM、五种语言和六个数据集,表明模仿人物角色属性会导致标注的可变性,而纳入地域信号可以更好地实现区域对齐。此外,LLM对数值锚定敏感,表明其能够利用社区标记工作和暴露于对抗性攻击。该工作为在文化敏感场景中应用LLM提供了初步指导,并强调了其中的细微差别。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在内容审核,特别是仇恨言论检测等主观任务中,对不同群体表现的差异性问题。现有方法未能充分考虑地域、身份等因素对仇恨言论判断的影响,导致LLM可能存在偏见,无法公平地服务于所有用户。
核心思路:论文的核心思路是通过在LLM的提示(prompt)中加入额外的上下文信息,例如地域信息、人物角色属性和数值信息,来系统性地评估LLM对这些因素的敏感程度。通过观察LLM在不同上下文下的输出变化,从而揭示其潜在的偏见和局限性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择合适的LLM模型(文中使用了两个LLM);2) 选取多个包含仇恨言论的数据集(涵盖五种语言和六个数据集);3) 设计包含不同上下文信息的提示(prompt),例如加入地域名称、人物角色描述、数值锚定等;4) 使用LLM对数据集中的文本进行仇恨言论检测,并记录LLM的输出结果;5) 分析LLM在不同提示下的输出变化,评估其对不同因素的敏感程度。
关键创新:该研究的关键创新在于其系统性地研究了LLM在内容审核任务中对地域、身份和数值信息的敏感性。以往的研究主要关注LLM的整体性能,而忽略了其在不同群体上的表现差异。该研究通过控制提示中的上下文信息,揭示了LLM潜在的偏见和局限性,为后续研究提供了重要的参考。
关键设计:论文的关键设计包括:1) 针对不同的上下文信息,设计了不同的提示模板,例如使用“来自[地域]的人认为…”来引导LLM;2) 使用不同的数值锚定值,例如社区举报数量,来观察LLM的判断变化;3) 采用了多种评估指标,例如准确率、召回率等,来全面评估LLM的性能。
🖼️ 关键图片

📊 实验亮点
研究发现,LLM对人物角色属性的模仿会导致标注结果的可变性,而加入地域信号可以改善区域对齐。此外,LLM对数值锚定敏感,表明其容易受到对抗性攻击的影响。这些发现揭示了LLM在内容审核中的潜在风险,并为改进LLM的鲁棒性提供了思路。
🎯 应用场景
该研究成果可应用于改进内容审核系统,减少LLM的偏见,提高其公平性。通过了解LLM对不同因素的敏感性,可以设计更有效的提示工程策略,使其更好地服务于不同群体。此外,该研究还可以帮助开发者更好地理解LLM的局限性,从而开发出更可靠、更负责任的AI系统。
📄 摘要(原文)
For subjective tasks such as hate detection, where people perceive hate differently, the Large Language Model's (LLM) ability to represent diverse groups is unclear. By including additional context in prompts, we comprehensively analyze LLM's sensitivity to geographical priming, persona attributes, and numerical information to assess how well the needs of various groups are reflected. Our findings on two LLMs, five languages, and six datasets reveal that mimicking persona-based attributes leads to annotation variability. Meanwhile, incorporating geographical signals leads to better regional alignment. We also find that the LLMs are sensitive to numerical anchors, indicating the ability to leverage community-based flagging efforts and exposure to adversaries. Our work provides preliminary guidelines and highlights the nuances of applying LLMs in culturally sensitive cases.