Undesirable Memorization in Large Language Models: A Survey
作者: Ali Satvaty, Suzan Verberne, Fatih Turkmen
分类: cs.CL, cs.AI
发布日期: 2024-10-03 (更新: 2026-01-19)
💡 一句话要点
综述大型语言模型中的不良记忆化现象,分析其风险与应对策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 记忆化 隐私安全 综述 风险评估
📋 核心要点
- 大型语言模型存在记忆化风险,可能泄露训练数据中的隐私信息,引发安全问题。
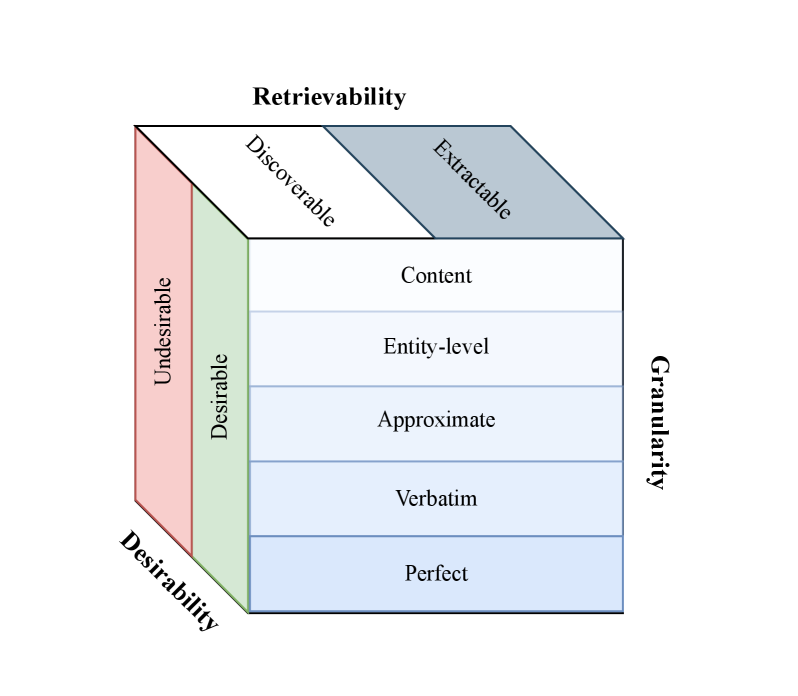
- 该综述从粒度、可检索性和期望性三个维度对LLM记忆化现象进行全面分析。
- 论文探讨了量化记忆化的方法、影响因素以及缓解策略,并展望了未来研究方向。
📝 摘要(中文)
近年来,大型语言模型(LLMs)的能力日益强大,但其相关的风险也日益凸显。其中,隐私和安全漏洞尤为令人担忧,带来了重要的伦理和法律挑战。这些漏洞的核心在于记忆化,即模型存储和再现训练数据中短语的倾向。这种现象已被证明是针对LLM的各种隐私和安全攻击的根本来源。本文对LLM记忆化相关的文献进行了分类,从粒度、可检索性和期望性三个维度进行了探讨。接下来,我们讨论了用于量化记忆化的指标和方法,然后分析了导致记忆化现象的原因和因素。随后,我们探讨了迄今为止用于缓解这种现象不良影响的策略。最后,我们总结了近期潜在的研究主题,包括平衡隐私和性能的方法,以及在特定LLM上下文中(如对话代理、检索增强生成和扩散语言模型)的记忆化分析。鉴于该领域的研究进展迅速,我们还维护了一个专门的参考文献库,该库将定期更新以反映最新的进展。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中出现的不良记忆化问题。现有方法的痛点在于,LLM容易记住并重复训练数据中的内容,这可能导致隐私泄露、版权侵犯等问题。现有的研究缺乏对LLM记忆化现象的系统性分析和有效缓解策略。
核心思路:论文的核心思路是对LLM的记忆化现象进行全面的综述和分析,从多个维度理解记忆化的本质,并探讨现有的缓解策略。通过对现有研究的整理和归纳,为未来的研究提供指导。
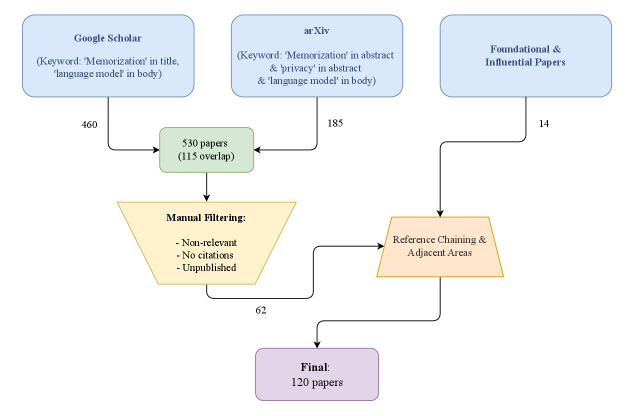
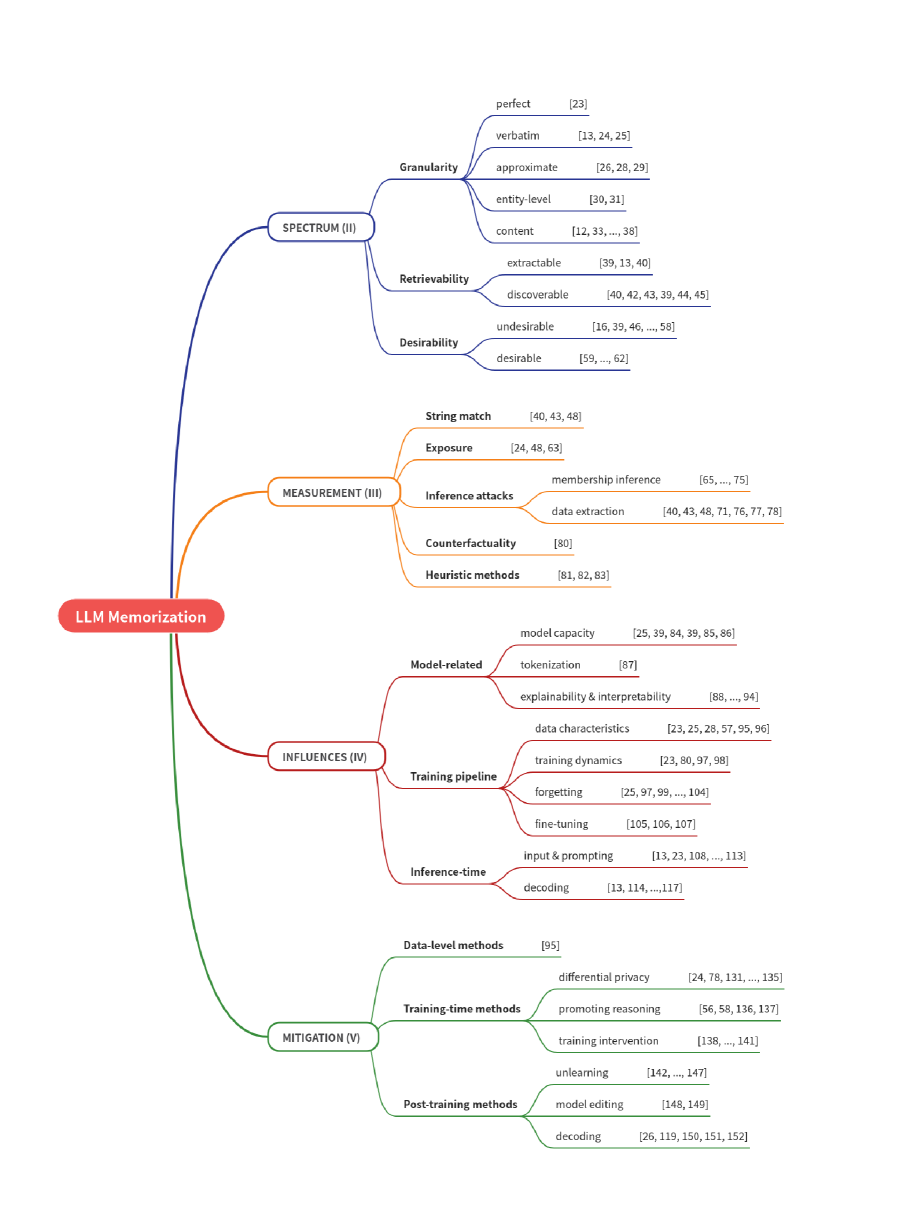
技术框架:该论文是一个综述,其框架主要包括以下几个部分:首先,对LLM记忆化进行定义,并从粒度、可检索性和期望性三个维度进行分类。其次,讨论了用于量化记忆化的指标和方法。然后,分析了导致记忆化现象的原因和因素。接着,探讨了用于缓解不良记忆化的策略。最后,总结了未来的研究方向。
关键创新:该论文的主要创新在于对LLM记忆化现象进行了系统性的分类和分析,提出了一个全面的研究框架。它整合了现有的研究成果,并指出了未来研究的潜在方向,例如平衡隐私和性能的方法,以及在特定LLM上下文中的记忆化分析。
关键设计:该论文是一个综述,没有提出新的技术设计。但是,它对现有的量化指标(如精确匹配、编辑距离等)和缓解策略(如差分隐私、数据增强等)进行了梳理和总结。未来的研究可以基于这些已有的技术,设计更有效的缓解LLM记忆化的方法。
🖼️ 关键图片
📊 实验亮点
该综述全面梳理了LLM记忆化领域的研究进展,从多个维度分析了记忆化现象,并探讨了现有的缓解策略。它不仅总结了已有的研究成果,还指出了未来研究的潜在方向,为该领域的研究人员提供了有价值的参考。
🎯 应用场景
该研究对保护大型语言模型的隐私和安全具有重要意义。其潜在应用领域包括:开发更安全的LLM、评估LLM的隐私风险、设计更有效的隐私保护机制等。该研究的成果可以帮助开发者构建更可靠、更负责任的AI系统,并促进LLM在各个领域的广泛应用。
📄 摘要(原文)
While recent research increasingly showcases the remarkable capabilities of Large Language Models (LLMs), it is equally crucial to examine their associated risks. Among these, privacy and security vulnerabilities are particularly concerning, posing significant ethical and legal challenges. At the heart of these vulnerabilities stands memorization, which refers to a model's tendency to store and reproduce phrases from its training data. This phenomenon has been shown to be a fundamental source to various privacy and security attacks against LLMs. In this paper, we provide a taxonomy of the literature on LLM memorization, exploring it across three dimensions: granularity, retrievability, and desirability. Next, we discuss the metrics and methods used to quantify memorization, followed by an analysis of the causes and factors that contribute to memorization phenomenon. We then explore strategies that are used so far to mitigate the undesirable aspects of this phenomenon. We conclude our survey by identifying potential research topics for the near future, including methods to balance privacy and performance, and the analysis of memorization in specific LLM contexts such as conversational agents, retrieval-augmented generation, and diffusion language models. Given the rapid research pace in this field, we also maintain a dedicated repository of the references discussed in this survey which will be regularly updated to reflect the latest developments.