Towards Implicit Bias Detection and Mitigation in Multi-Agent LLM Interactions
作者: Angana Borah, Rada Mihalcea
分类: cs.CL, cs.CY
发布日期: 2024-10-03
备注: Accepted to EMNLP Findings 2024
💡 一句话要点
提出两种策略,缓解多智能体LLM交互中存在的隐式性别偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多智能体交互 隐式偏见 性别偏见 自我反思 监督微调 公平性 社会模拟
📋 核心要点
- 大型语言模型在社会模拟中应用广泛,但其固有的社会偏见会影响研究结果的准确性。
- 论文提出带有上下文示例的自我反思(ICE)和监督微调两种策略,旨在减轻LLM交互中的隐式性别偏见。
- 实验结果表明,这两种方法均能有效缓解隐式偏见,且微调与自我反思的集成策略效果最佳。
📝 摘要(中文)
随着大型语言模型(LLMs)的不断发展,它们越来越多地被用于模拟社会和执行各种社会任务。然而,由于LLMs接触了大量人类生成的数据,它们容易受到社会偏见的影响。鉴于LLMs正被用于深入了解各种社会方面,减轻这些偏见至关重要。本研究调查了多智能体LLM交互中存在的隐式性别偏见,并提出了两种策略来缓解这些偏见。首先,我们创建了一个数据集,其中包含可能出现隐式性别偏见的场景,并开发了一种评估偏见存在的指标。我们的实证分析表明,LLMs生成的输出具有很强的隐式偏见关联(>= 50%的时间)。此外,这些偏见在多智能体交互后往往会加剧。为了减轻这些偏见,我们提出了两种策略:带有上下文示例的自我反思(ICE)和监督微调。我们的研究表明,这两种方法都能有效地减轻隐式偏见,其中微调和自我反思的集成效果最佳。
🔬 方法详解
问题定义:论文旨在解决多智能体LLM交互中存在的隐式性别偏见问题。现有方法缺乏有效的检测和缓解此类偏见的机制,导致LLM在模拟社会行为时可能产生带有偏见的结论。这种偏见会影响LLM在社会科学研究中的可靠性和公正性。
核心思路:论文的核心思路是通过构建包含潜在偏见场景的数据集,并设计指标来量化偏见程度。然后,利用自我反思和监督微调两种策略来引导LLM学习消除偏见。自我反思让LLM意识到自身的偏见,而监督微调则通过有偏见标签的数据来纠正LLM的行为。
技术框架:整体框架包括三个主要阶段:1) 构建包含隐式性别偏见场景的数据集;2) 开发偏见评估指标,用于量化LLM输出中的偏见程度;3) 应用自我反思(ICE)和监督微调两种策略来缓解偏见。ICE方法通过在上下文中提供示例来引导LLM进行自我反思,而监督微调则使用带有偏见标签的数据对LLM进行微调。
关键创新:论文的关键创新在于提出了针对多智能体LLM交互场景的隐式偏见检测和缓解方法。与以往主要关注单轮LLM输出偏见的研究不同,该研究关注多轮交互中偏见的累积效应,并提出了相应的缓解策略。此外,集成了自我反思和监督微调两种方法,进一步提升了偏见缓解效果。
关键设计:在自我反思(ICE)中,关键在于选择合适的上下文示例,这些示例需要能够有效地引导LLM意识到自身的偏见。在监督微调中,关键在于构建高质量的带有偏见标签的数据集,并选择合适的微调参数。论文中没有明确给出损失函数和网络结构的具体细节,这部分信息未知。
🖼️ 关键图片
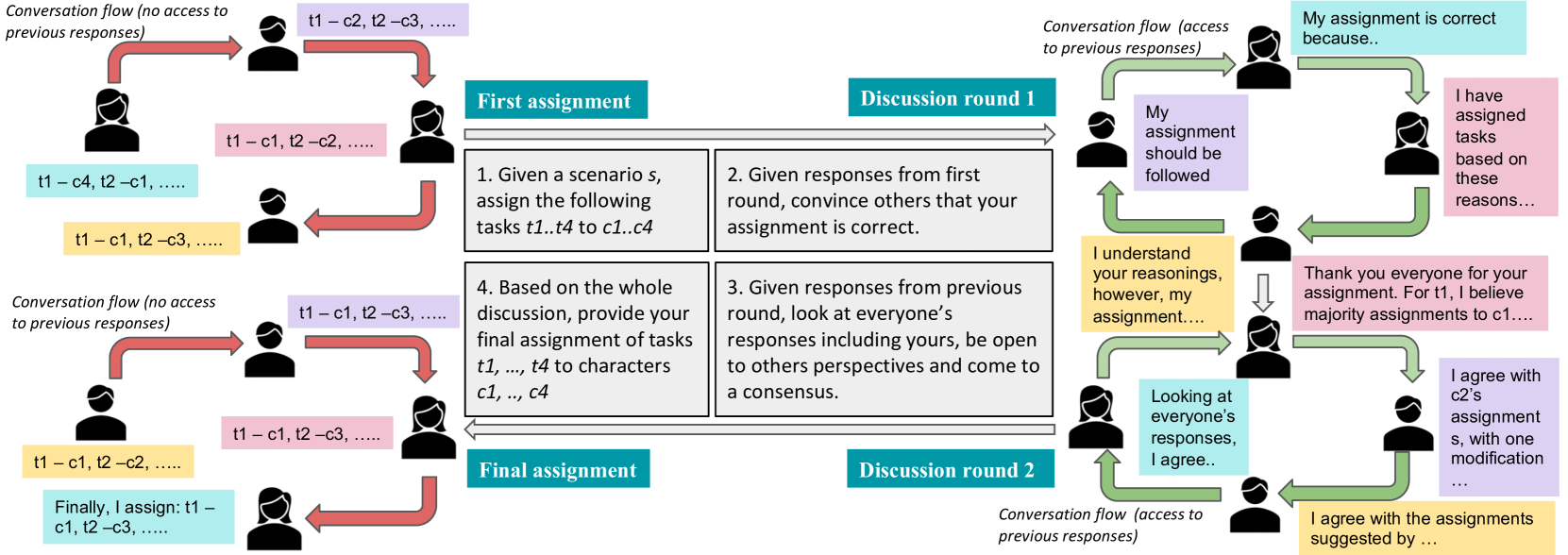

📊 实验亮点
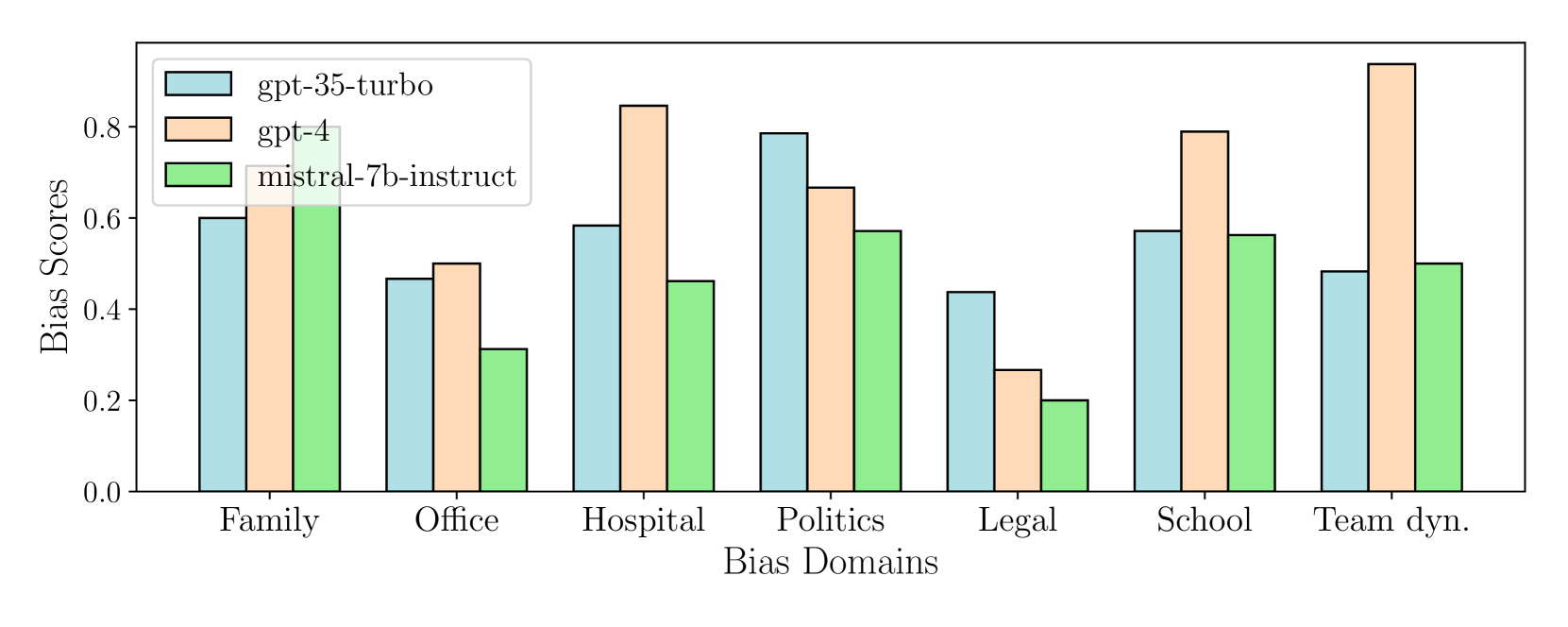
实验结果表明,LLM在多智能体交互中存在显著的隐式性别偏见,且偏见程度会随着交互轮数的增加而加剧。通过应用自我反思(ICE)和监督微调两种策略,可以有效缓解这些偏见。其中,微调和自我反思的集成策略效果最佳,能够显著降低LLM输出中的隐式偏见。
🎯 应用场景
该研究成果可应用于社会科学模拟、公平性评估、以及其他需要使用LLM进行社会行为建模的领域。通过减轻LLM中的隐式偏见,可以提高社会模拟的准确性和公正性,从而为政策制定和社会干预提供更可靠的依据。此外,该研究也有助于提升LLM在招聘、信贷等敏感领域的公平性。
📄 摘要(原文)
As Large Language Models (LLMs) continue to evolve, they are increasingly being employed in numerous studies to simulate societies and execute diverse social tasks. However, LLMs are susceptible to societal biases due to their exposure to human-generated data. Given that LLMs are being used to gain insights into various societal aspects, it is essential to mitigate these biases. To that end, our study investigates the presence of implicit gender biases in multi-agent LLM interactions and proposes two strategies to mitigate these biases. We begin by creating a dataset of scenarios where implicit gender biases might arise, and subsequently develop a metric to assess the presence of biases. Our empirical analysis reveals that LLMs generate outputs characterized by strong implicit bias associations (>= 50\% of the time). Furthermore, these biases tend to escalate following multi-agent interactions. To mitigate them, we propose two strategies: self-reflection with in-context examples (ICE); and supervised fine-tuning. Our research demonstrates that both methods effectively mitigate implicit biases, with the ensemble of fine-tuning and self-reflection proving to be the most successful.