Contextual Document Embeddings
作者: John X. Morris, Alexander M. Rush
分类: cs.CL, cs.AI
发布日期: 2024-10-03 (更新: 2024-11-08)
💡 一句话要点
提出上下文文档嵌入方法,提升神经检索中文档表示的质量和泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 上下文文档嵌入 神经检索 对比学习 文档表示 领域泛化
📋 核心要点
- 现有神经检索方法依赖于独立编码文档,忽略了文档间的上下文关系,导致检索效果受限。
- 论文提出上下文文档嵌入,通过对比学习和上下文编码架构,显式地利用相邻文档信息。
- 实验表明,该方法在多个数据集上优于传统双编码器,尤其在跨领域检索任务中表现突出。
📝 摘要(中文)
稠密文档嵌入是神经检索的核心。目前的主流方法是直接在单个文档上运行编码器来训练和构建嵌入。本文认为,这些嵌入虽然有效,但对于检索的特定用例来说,在上下文中是隐式地“脱离”的。上下文文档嵌入应该同时考虑文档本身和上下文中相邻的文档,类似于上下文词嵌入。我们提出了两种互补的上下文文档嵌入方法:首先,一种替代的对比学习目标,它显式地将相邻文档纳入到批内上下文损失中;其次,一种新的上下文架构,它显式地将相邻文档信息编码到表示中。结果表明,这两种方法在多个设置中都优于双编码器,尤其是在领域外的情况下。我们在MTEB基准测试上取得了最先进的结果,且未使用困难负样本挖掘、分数蒸馏、数据集特定指令、GPU内示例共享或极大的批大小。我们的方法可以应用于改进任何对比学习数据集和任何双编码器的性能。
🔬 方法详解
问题定义:现有神经检索方法通常独立地编码每个文档,忽略了文档之间的上下文信息。这种孤立的编码方式使得文档嵌入缺乏对文档之间关系的建模能力,从而影响检索的准确性和泛化性。尤其是在领域外检索任务中,这种问题更加突出。
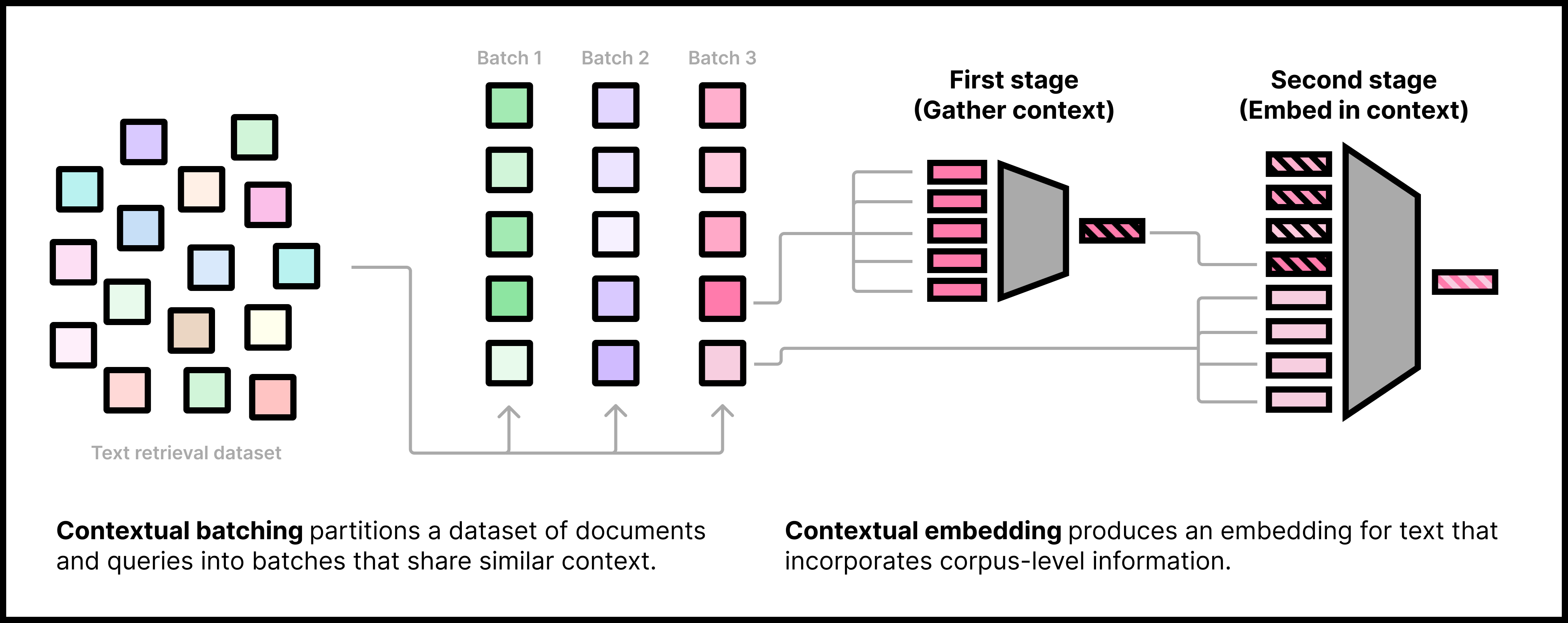
核心思路:论文的核心思路是借鉴上下文词嵌入的思想,将文档嵌入也进行上下文建模。具体来说,就是让文档嵌入不仅包含文档自身的信息,还包含其相邻文档的信息。通过这种方式,文档嵌入能够更好地反映文档在整个文档集合中的语义关系,从而提高检索的准确性。
技术框架:论文提出了两种互补的方法来实现上下文文档嵌入。第一种方法是改进对比学习的损失函数,将相邻文档纳入到批内上下文损失中。具体来说,就是将目标文档和其相邻文档视为正样本,而将其他文档视为负样本。第二种方法是设计一种新的上下文编码架构,该架构能够显式地将相邻文档的信息编码到文档表示中。该架构通常包含一个文档编码器和一个上下文编码器,文档编码器用于编码目标文档,上下文编码器用于编码相邻文档,然后将两个编码器的输出进行融合,得到最终的上下文文档嵌入。
关键创新:论文的关键创新在于提出了上下文文档嵌入的概念,并设计了两种有效的方法来实现该概念。与传统的独立文档编码方法相比,该方法能够更好地建模文档之间的关系,从而提高检索的准确性和泛化性。此外,该方法不需要使用困难负样本挖掘、分数蒸馏等复杂的技巧,也能够取得很好的效果。
关键设计:在对比学习方面,论文修改了损失函数,使得正样本不仅包含目标文档本身,还包含其相邻文档。在上下文编码架构方面,论文提出了多种融合文档编码器和上下文编码器输出的方式,例如拼接、加权平均等。具体的网络结构和参数设置需要根据具体的任务和数据集进行调整。论文中没有明确给出具体的网络结构和参数设置,这部分内容可能需要在实际应用中进行探索。
🖼️ 关键图片
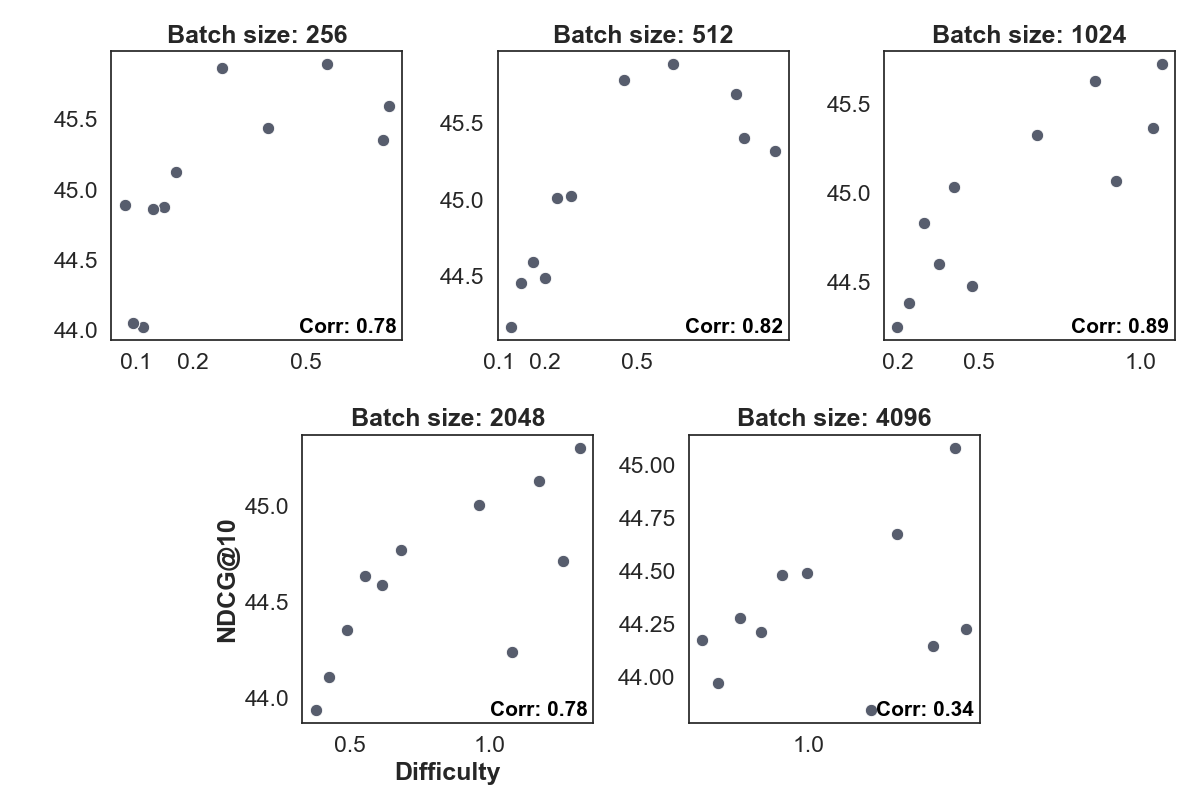
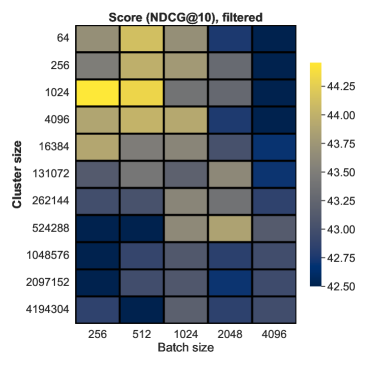
📊 实验亮点
该方法在MTEB基准测试上取得了最先进的结果,无需复杂的训练技巧,如困难负样本挖掘、分数蒸馏等。实验表明,该方法在多个数据集上优于传统的双编码器,尤其是在领域外检索任务中,性能提升显著。这表明该方法具有良好的泛化能力和实用价值。
🎯 应用场景
该研究成果可广泛应用于信息检索、问答系统、推荐系统等领域。通过提升文档嵌入的质量,可以提高搜索结果的相关性,改善用户体验。尤其在处理大规模文档集合和跨领域检索任务时,该方法的优势更加明显。未来,该方法有望应用于知识图谱构建、文档聚类等更广泛的自然语言处理任务。
📄 摘要(原文)
Dense document embeddings are central to neural retrieval. The dominant paradigm is to train and construct embeddings by running encoders directly on individual documents. In this work, we argue that these embeddings, while effective, are implicitly out-of-context for targeted use cases of retrieval, and that a contextualized document embedding should take into account both the document and neighboring documents in context - analogous to contextualized word embeddings. We propose two complementary methods for contextualized document embeddings: first, an alternative contrastive learning objective that explicitly incorporates the document neighbors into the intra-batch contextual loss; second, a new contextual architecture that explicitly encodes neighbor document information into the encoded representation. Results show that both methods achieve better performance than biencoders in several settings, with differences especially pronounced out-of-domain. We achieve state-of-the-art results on the MTEB benchmark with no hard negative mining, score distillation, dataset-specific instructions, intra-GPU example-sharing, or extremely large batch sizes. Our method can be applied to improve performance on any contrastive learning dataset and any biencoder.