Defining Knowledge: Bridging Epistemology and Large Language Models
作者: Constanza Fierro, Ruchira Dhar, Filippos Stamatiou, Nicolas Garneau, Anders Søgaard
分类: cs.CL
发布日期: 2024-10-03
备注: EMNLP 2024
💡 一句话要点
探讨LLM知识定义:桥接认知论与大语言模型,提出评估协议
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识表示 认知论 知识评估 人工智能伦理
📋 核心要点
- 现有研究对LLM的“知识”缺乏明确的认知论定义,导致评估标准不统一,难以判断LLM是否真正具备知识。
- 论文核心在于将认知论中知识的定义形式化,并应用于LLM,从而为评估LLM的知识能力提供理论基础。
- 通过调研哲学和计算机科学领域专家,并提出相应的评估协议,旨在弥合理论与实践之间的差距。
📝 摘要(中文)
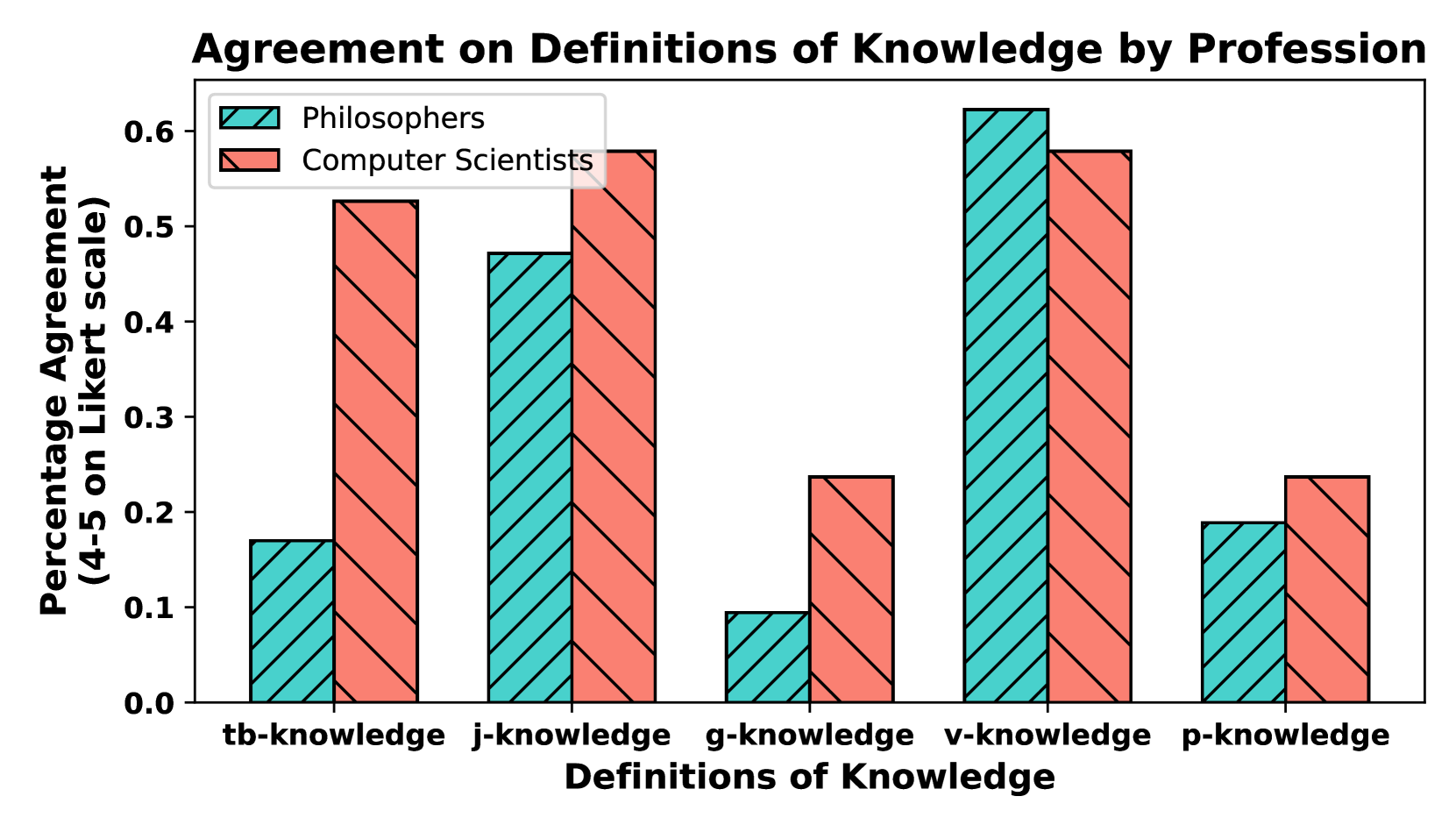
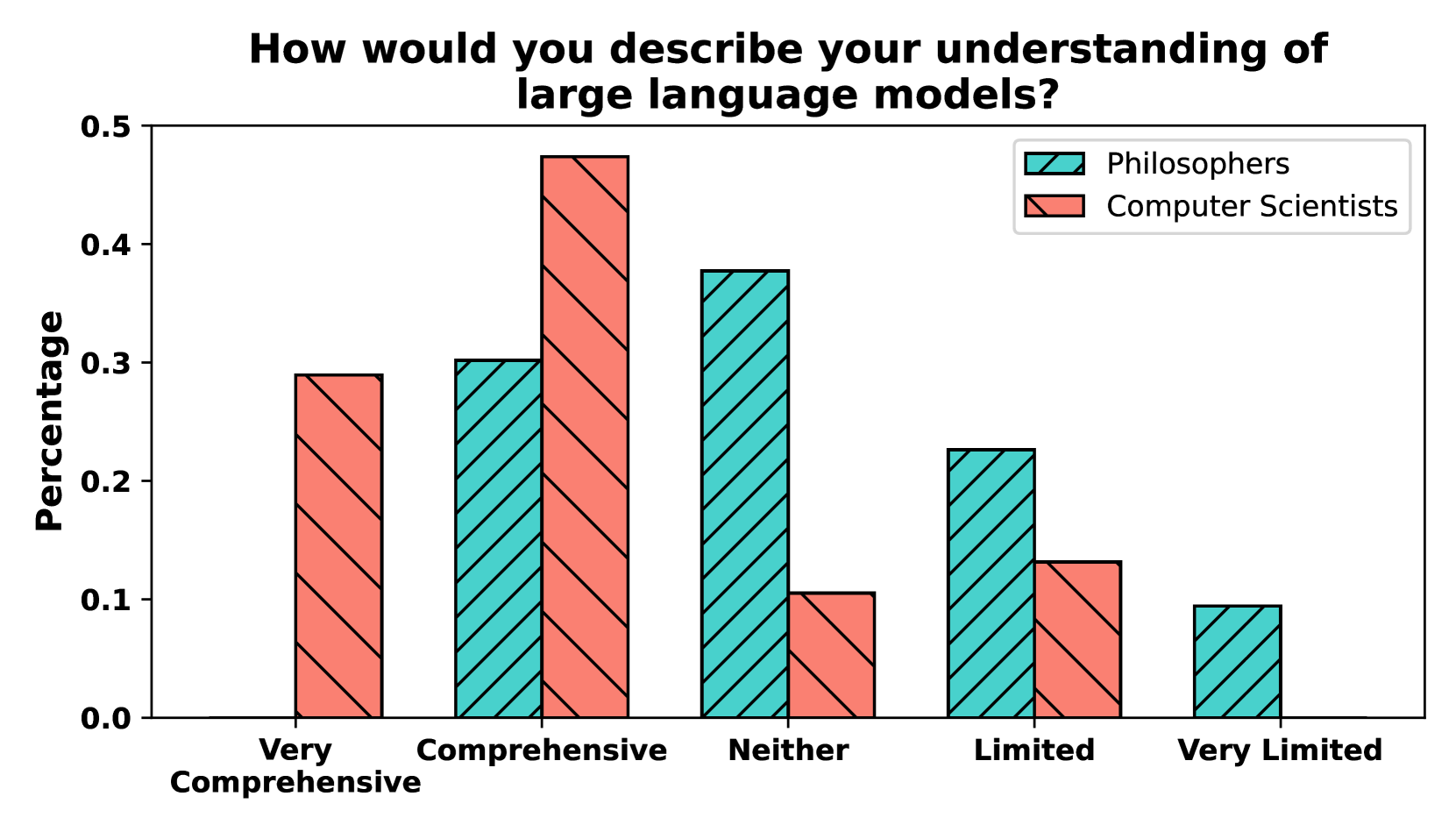
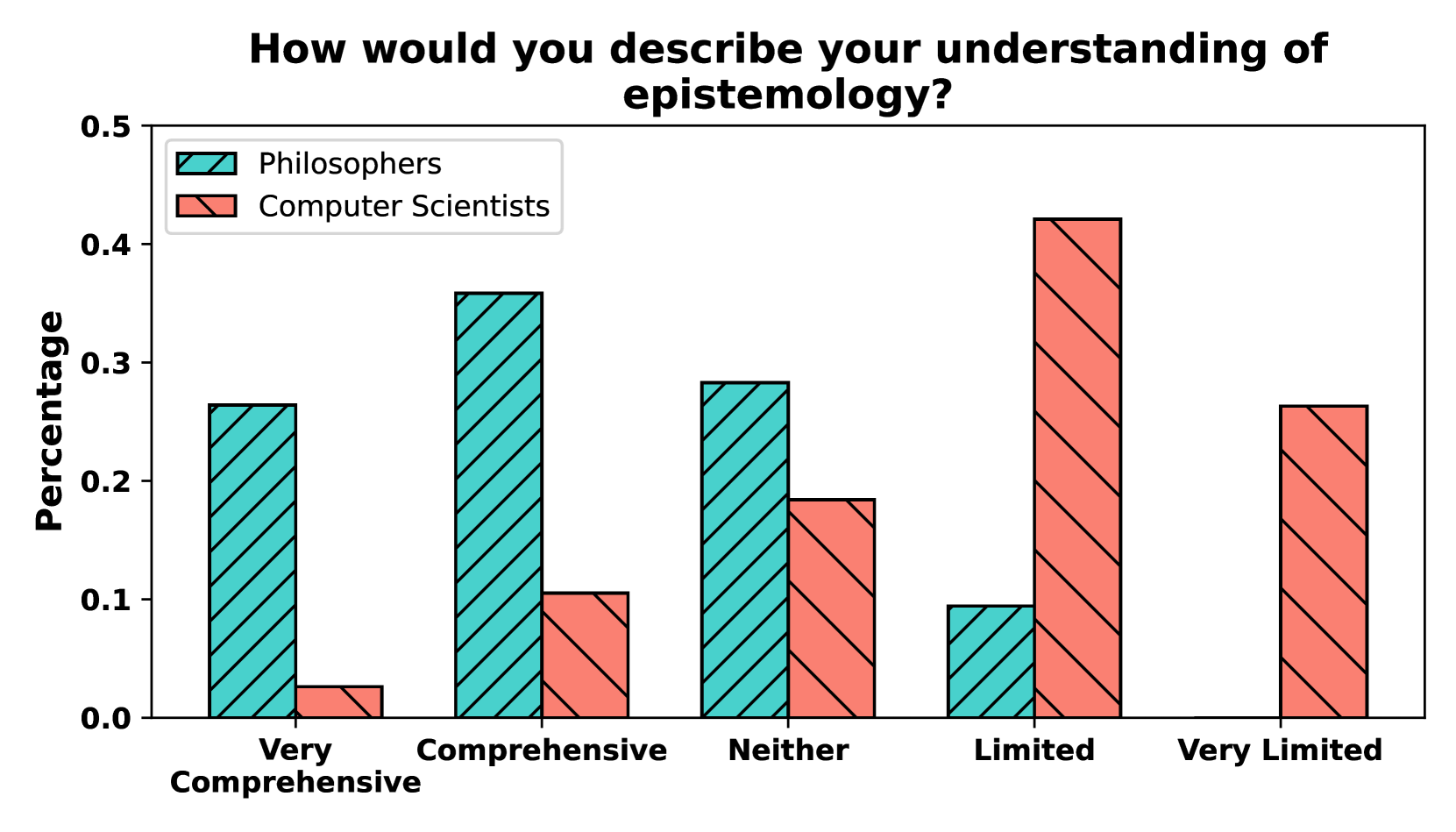
关于大语言模型(LLM)的文献中充斥着关于知识的论断;但我们能否说GPT-4真正“知道”地球是圆的?为了解决这个问题,我们回顾了认知论中知识的标准定义,并形式化了适用于LLM的解释。通过这样做,我们发现了当前NLP研究在概念化知识方面与认知论框架的不一致和差距。此外,我们对100位专业哲学家和计算机科学家进行了调查,以比较他们在知识定义方面的偏好以及他们对LLM是否真的可以被称为知道的看法。最后,我们提出了根据最相关的定义测试知识的评估协议。
🔬 方法详解
问题定义:论文旨在解决如何定义和评估大语言模型(LLM)所拥有的“知识”这一问题。现有方法通常依赖于简单的问答测试,但缺乏对“知识”的深入理解和明确的认知论基础。这导致对LLM知识能力的评估缺乏严谨性和可信度,难以区分LLM是真正理解还是仅仅记忆了答案。
核心思路:论文的核心思路是将认知论中关于知识的定义(例如,JTB理论:Justified True Belief,即辩护的真信念)形式化,并将其应用于LLM。通过分析LLM是否满足这些形式化的知识定义,来判断LLM是否真正“知道”某些事实。这种方法旨在提供一种更严谨、更具理论基础的知识评估框架。
技术框架:论文主要包含以下几个阶段:1) 回顾认知论中关于知识的各种定义;2) 将这些定义形式化,使其能够应用于LLM;3) 进行专家调研,了解哲学和计算机科学领域专家对LLM知识的看法;4) 基于形式化的知识定义,提出评估LLM知识的协议。整体流程是从理论到实践,旨在建立一套完整的LLM知识评估体系。
关键创新:论文的关键创新在于将认知论的知识定义与LLM的评估联系起来。以往的研究主要集中在提高LLM的性能,而忽略了对LLM知识本质的探讨。该论文首次尝试将哲学领域的知识理论应用于LLM,为LLM的研究提供了一个新的视角。
关键设计:论文的关键设计包括:1) 对认知论知识定义的精确形式化,使其能够被LLM处理和评估;2) 设计专家调研问卷,收集不同领域专家对LLM知识的看法;3) 提出具体的评估协议,包括选择合适的测试数据集、设计评估指标等。这些设计旨在确保评估的科学性和有效性。论文未提及具体的参数设置、损失函数或网络结构,因为其重点在于知识的定义和评估框架,而非具体的模型训练。
🖼️ 关键图片
📊 实验亮点
论文通过对100位哲学和计算机科学专家的调研发现,不同领域专家对LLM是否具备知识存在显著差异。此外,论文提出的评估协议能够更有效地识别LLM的知识盲点和错误,相比传统的问答测试,能够更准确地评估LLM的知识水平。具体性能数据未知,但该研究为LLM知识评估提供了一个新的方向。
🎯 应用场景
该研究成果可应用于提升LLM的可信度和可靠性。通过更准确地评估LLM的知识水平,可以更好地控制LLM的输出,避免其产生错误或误导性信息。此外,该研究还可以促进LLM在教育、医疗等领域的应用,因为在这些领域中,LLM的知识准确性至关重要。未来,该研究有望推动LLM朝着更智能、更可靠的方向发展。
📄 摘要(原文)
Knowledge claims are abundant in the literature on large language models (LLMs); but can we say that GPT-4 truly "knows" the Earth is round? To address this question, we review standard definitions of knowledge in epistemology and we formalize interpretations applicable to LLMs. In doing so, we identify inconsistencies and gaps in how current NLP research conceptualizes knowledge with respect to epistemological frameworks. Additionally, we conduct a survey of 100 professional philosophers and computer scientists to compare their preferences in knowledge definitions and their views on whether LLMs can really be said to know. Finally, we suggest evaluation protocols for testing knowledge in accordance to the most relevant definitions.