Revealing the Inherent Instructability of Pre-Trained Language Models
作者: Seokhyun An, Minji Kim, Hyounghun Kim
分类: cs.CL, cs.AI
发布日期: 2024-10-03 (更新: 2025-09-13)
备注: Findings of EMNLP 2025 (32 pages). Code available at https://github.com/seokhyunan/response-tuning
💡 一句话要点
提出响应调优(RT),揭示预训练语言模型固有的指令理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 预训练语言模型 指令调优 响应调优 固有能力 多任务学习
📋 核心要点
- 现有指令调优方法依赖指令-响应对,忽略了预训练阶段模型可能已经具备的指令理解能力。
- 论文提出响应调优(RT),仅使用响应数据训练模型,验证预训练LLM是否具备固有的指令理解能力。
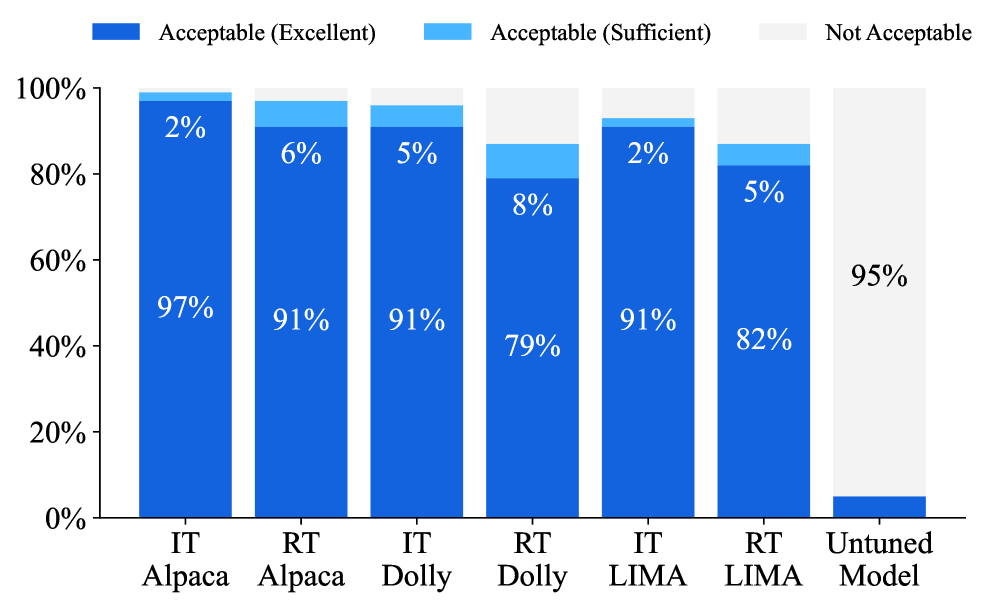
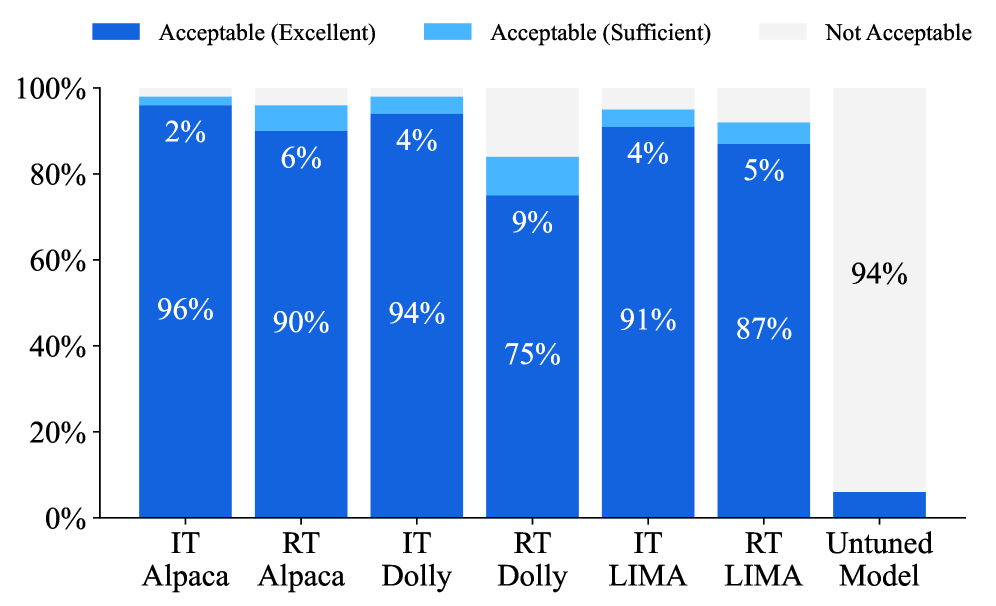
- 实验表明,仅使用响应数据训练的RT模型,在指令遵循和安全性方面,表现接近指令调优模型。
📝 摘要(中文)
指令调优是使预训练大型语言模型(LLMs)具备指令遵循能力的关键步骤,它使用指令-响应对进行监督微调。与此同时,LLMs在预训练阶段执行多任务学习,获得广泛的知识和能力。我们假设预训练阶段使它们能够发展理解和处理指令的能力。为了验证这一点,我们提出了响应调优(RT),它从指令调优中移除指令及其与响应的对应关系,而仅专注于建立响应分布。我们的实验表明,仅在响应上训练的RT模型可以有效地响应各种指令,类似于经过指令调优的模型。此外,我们观察到,在仅从响应数据中学习安全策略后,模型可以识别并拒绝不安全的查询。此外,我们发现这些观察结果可以扩展到上下文学习设置。这些发现支持了我们的假设,突出了预训练LLMs广泛的固有能力。
🔬 方法详解
问题定义:现有指令调优方法需要大量的指令-响应对,成本高昂。论文旨在探究预训练语言模型是否在预训练阶段已经具备了指令理解能力,从而减少对显式指令数据的依赖。现有方法的痛点在于,没有充分利用预训练阶段模型已经学习到的知识和能力,过度依赖指令微调。
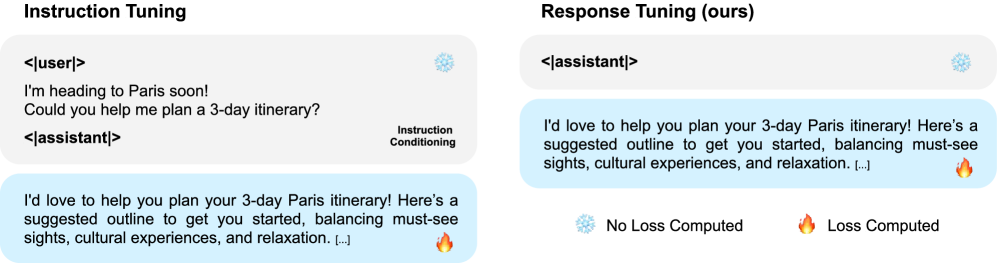
核心思路:论文的核心思路是,如果预训练语言模型已经具备了指令理解能力,那么仅使用响应数据进行训练,也能使模型学会生成符合指令的响应。通过移除指令,专注于建立响应分布,来验证预训练模型的固有能力。
技术框架:论文提出的响应调优(RT)方法,其整体流程如下:1) 收集响应数据,无需指令;2) 使用响应数据对预训练语言模型进行微调,目标是学习响应的分布;3) 使用指令对微调后的模型进行测试,评估其指令遵循能力和安全性。RT方法与传统的指令调优方法的主要区别在于,RT方法不使用指令数据进行训练。
关键创新:最重要的技术创新点在于,提出了响应调优(RT)这一概念,并验证了预训练语言模型在没有显式指令训练的情况下,仍然可以具备良好的指令遵循能力。与现有方法的本质区别在于,RT方法强调预训练阶段模型已经具备的固有能力,而现有方法则侧重于通过指令微调来赋予模型指令遵循能力。
关键设计:论文的关键设计包括:1) 使用各种数据集来训练和评估模型,包括指令遵循数据集和安全数据集;2) 使用不同的预训练语言模型作为基础模型,以验证RT方法的泛化能力;3) 使用不同的评估指标来衡量模型的指令遵循能力和安全性,例如BLEU score和安全指标。具体的参数设置和损失函数等技术细节在论文中进行了详细描述,但此处未提供具体数值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,仅使用响应数据训练的RT模型,在指令遵循能力上与经过指令调优的模型相当。此外,RT模型在安全性方面也表现良好,能够识别并拒绝不安全的查询。这些结果表明,预训练语言模型具备强大的固有能力,可以通过更高效的方式进行利用。具体的性能数据和提升幅度在论文中进行了详细展示,但此处未提供具体数值。
🎯 应用场景
该研究成果可应用于降低指令调优的成本,减少对大量指令数据的依赖。通过充分利用预训练模型的固有能力,可以更高效地训练出具备良好指令遵循能力和安全性的语言模型。这对于资源受限的场景,以及需要快速定制化语言模型的应用具有重要意义。未来,该方法可以扩展到其他类型的预训练模型和任务中。
📄 摘要(原文)
Instruction tuning -- supervised fine-tuning using instruction-response pairs -- is a key step in making pre-trained large language models (LLMs) instructable. Meanwhile, LLMs perform multitask learning during their pre-training, acquiring extensive knowledge and capabilities. We hypothesize that the pre-training stage can enable them to develop the ability to comprehend and address instructions. To verify this, we propose Response Tuning (RT), which removes the instruction and its corresponding mapping to the response from instruction tuning. Instead, it focuses solely on establishing a response distribution. Our experiments demonstrate that RT models, trained only on responses, can effectively respond to a wide range of instructions akin to their instruction-tuned counterparts. In addition, we observe that the models can recognize and reject unsafe queries after learning a safety policy only from the response data. Furthermore, we find that these observations extend to an in-context learning setting. These findings support our hypothesis, highlighting the extensive inherent capabilities of pre-trained LLMs.