MedVisionLlama: Leveraging Pre-Trained Large Language Model Layers to Enhance Medical Image Segmentation
作者: Gurucharan Marthi Krishna Kumar, Aman Chadha, Janine Mendola, Amir Shmuel
分类: eess.IV, cs.CL, cs.CV
发布日期: 2024-10-03 (更新: 2025-08-19)
备注: Accepted to the CVAMD Workshop (Computer Vision for Automated Medical Diagnosis) at the 2025 IEEE/CVF International Conference on Computer Vision (ICCVW 2025)
🔗 代码/项目: GITHUB
💡 一句话要点
MedVisionLlama:利用预训练LLM层增强医学图像分割
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像分割 大型语言模型 Vision Transformer 混合注意力机制 多尺度融合 预训练模型 深度学习
📋 核心要点
- 医学图像分割对精确诊断至关重要,但现有ViT模型在捕捉全局上下文信息和多尺度特征方面存在不足。
- 该论文提出将预训练LLM的Transformer块融入ViT编码器,并设计混合注意力机制和多尺度融合块,以提升分割性能。
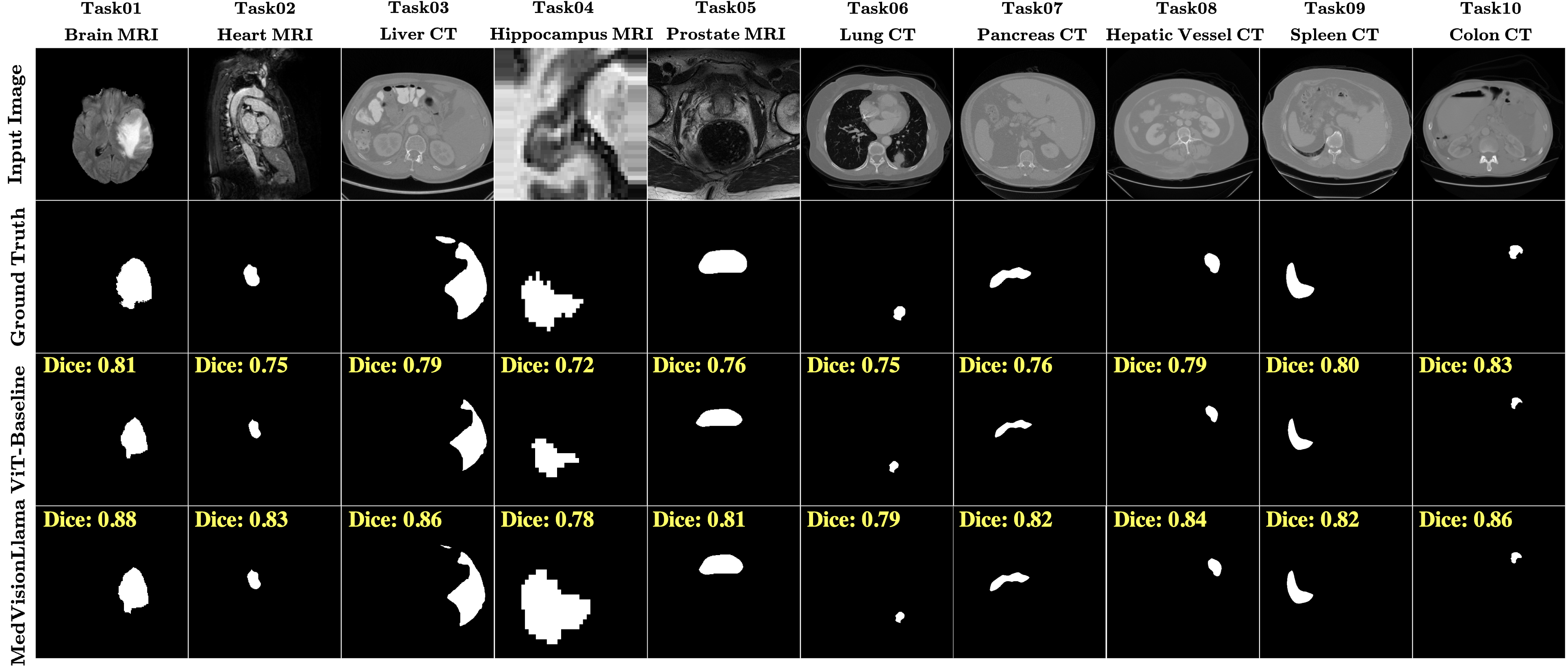
- 实验结果表明,该方法在多种医学成像模式下显著提高了分割准确率,Dice系数平均提升至0.79。
📝 摘要(中文)
大型语言模型(LLMs)在文本数据中表现出多功能性,目前正被探索其在医学图像分割方面的潜力,医学图像分割是精确诊断成像的关键任务。本研究探索通过集成预训练的LLM Transformer块来增强用于医学图像分割的Vision Transformers(ViTs)。我们的方法将冻结的LLM Transformer块整合到基于ViT的模型的编码器中,从而显著提高各种医学成像模式下的分割性能。我们提出了一种混合注意力机制,该机制结合了全局和局部特征学习以及用于聚合不同尺度特征的多尺度融合块。增强后的模型显示出显著的性能提升,包括平均Dice系数从0.74提高到0.79,以及在准确率、精确率和Jaccard指数方面的改进。这些结果证明了基于LLM的Transformer在改进医学图像分割方面的有效性,突出了它们在显著提高模型准确性和鲁棒性方面的潜力。源代码和我们的实现可在以下网址获得:https://github.com/AS-Lab/Marthi-et-al-2025-MedVisionLlama-Pre-Trained-LLM-Layers-to-Enhance-Medical-Image-Segmentation
🔬 方法详解
问题定义:医学图像分割旨在准确识别和分割医学图像中的目标区域,例如器官、病灶等。现有基于ViT的医学图像分割模型,虽然在局部特征提取方面表现良好,但在捕捉全局上下文信息和有效融合多尺度特征方面仍存在不足,导致分割精度受限。
核心思路:该论文的核心思路是将预训练的大型语言模型(LLM)的Transformer块集成到ViT模型的编码器中。LLM在处理序列数据方面表现出色,能够有效捕捉全局上下文信息。通过将LLM的Transformer块与ViT的局部特征提取能力相结合,可以提升模型对医学图像的理解能力,从而提高分割精度。
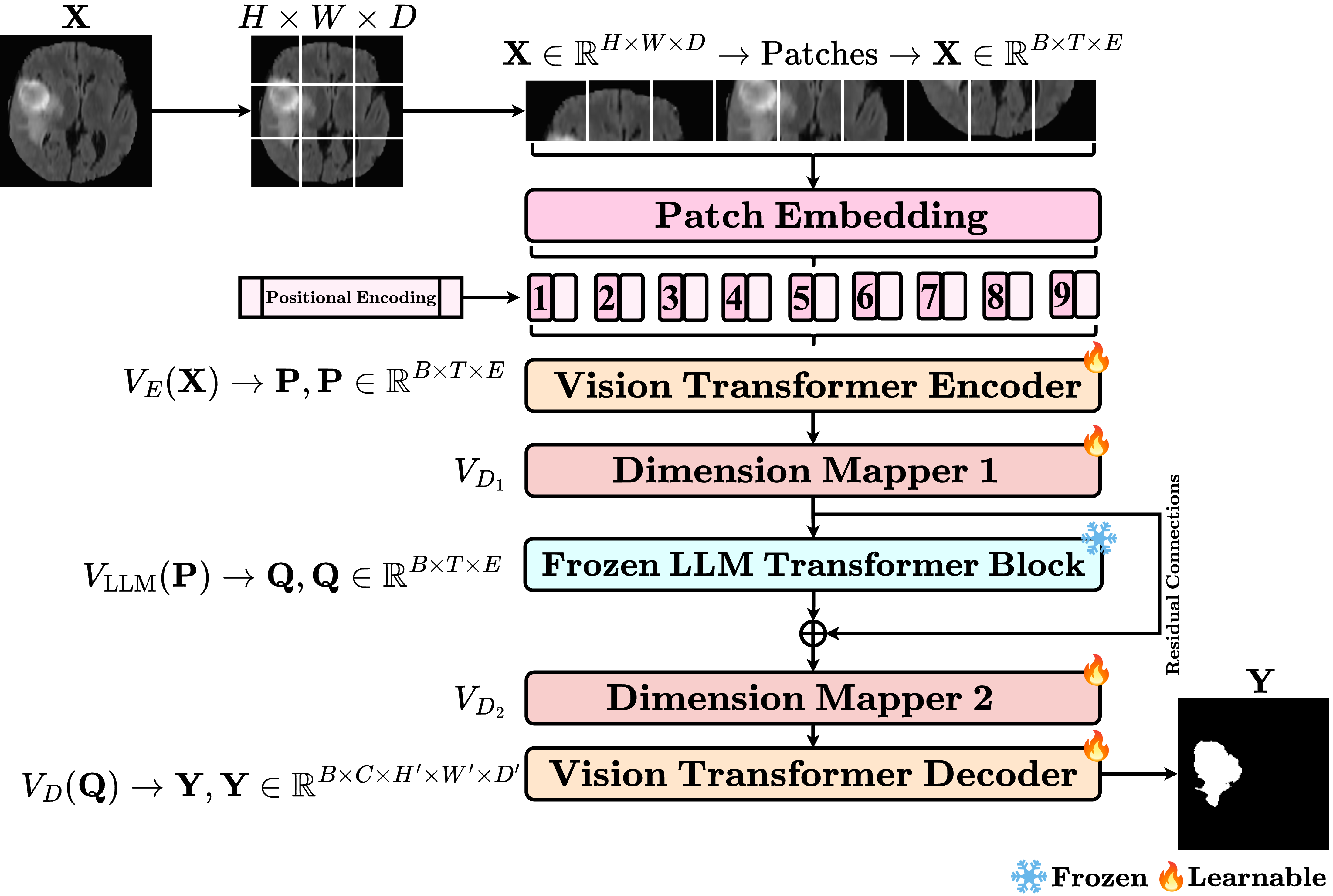
技术框架:该方法的技术框架主要包括以下几个模块:1) ViT编码器:用于提取医学图像的局部特征。2) 冻结的LLM Transformer块:用于捕捉全局上下文信息。3) 混合注意力机制:结合全局和局部特征学习。4) 多尺度融合块:用于聚合不同尺度的特征。整体流程是,首先使用ViT编码器提取图像特征,然后将特征输入到冻结的LLM Transformer块中进行全局上下文建模,接着通过混合注意力机制融合全局和局部特征,最后使用多尺度融合块聚合不同尺度的特征,得到最终的分割结果。
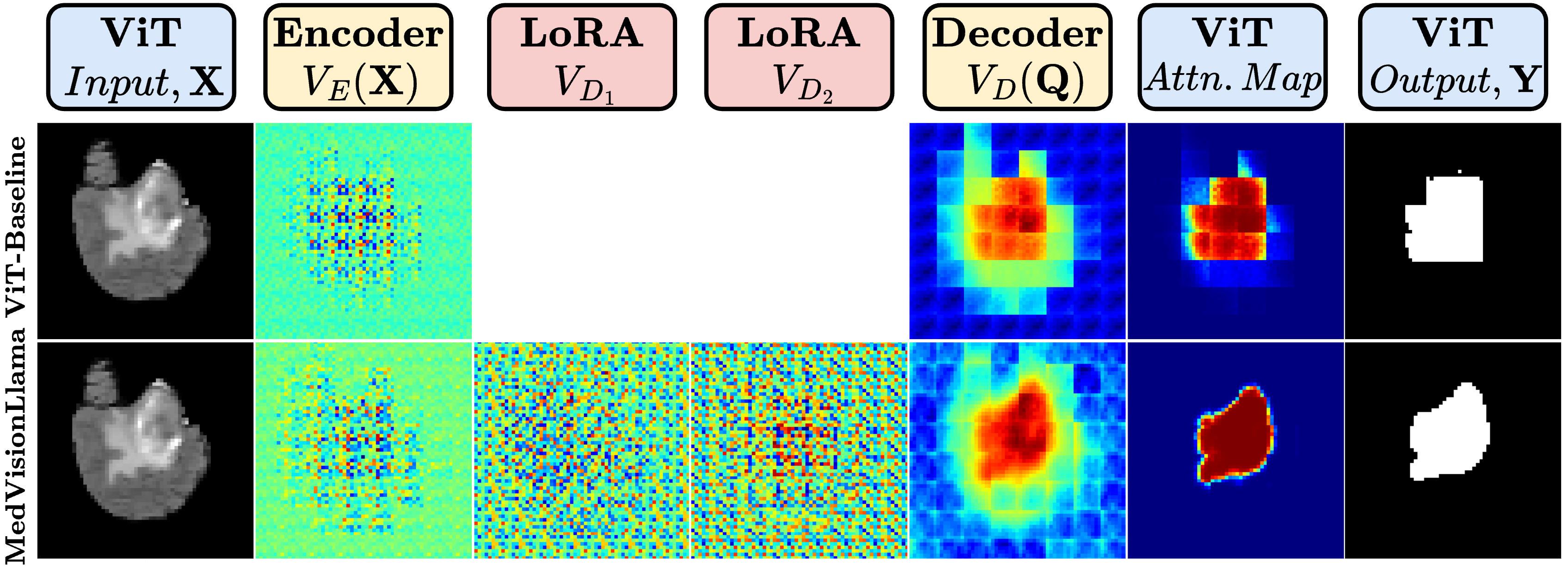
关键创新:该论文的关键创新在于将预训练的LLM Transformer块引入到医学图像分割任务中,并设计了混合注意力机制和多尺度融合块。与传统的ViT模型相比,该方法能够更好地捕捉全局上下文信息,并有效融合多尺度特征,从而显著提高分割精度。
关键设计:1) 冻结LLM Transformer块:为了避免微调LLM带来的计算负担和过拟合风险,该论文选择冻结LLM Transformer块的参数。2) 混合注意力机制:该机制结合了全局注意力和局部注意力,能够同时关注图像的全局上下文信息和局部细节。3) 多尺度融合块:该模块通过不同尺度的卷积操作提取不同尺度的特征,并将这些特征进行融合,从而提高模型对不同尺度目标的分割能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多种医学成像模式下均取得了显著的性能提升。例如,平均Dice系数从0.74提高到0.79,准确率、精确率和Jaccard指数也均有明显改善。这些结果表明,将预训练LLM层引入医学图像分割任务是有效的,能够显著提高模型的分割精度和鲁棒性。
🎯 应用场景
该研究成果可广泛应用于医学影像分析领域,例如肿瘤分割、器官分割、病灶检测等。通过提高医学图像分割的准确性和鲁棒性,可以辅助医生进行更精确的诊断和治疗计划制定,提升医疗效率和患者预后。未来,该方法有望推广到其他医学影像模态和分割任务中,并与其他AI技术相结合,实现更智能化的医学影像分析。
📄 摘要(原文)
Large Language Models (LLMs), known for their versatility in textual data, are increasingly being explored for their potential to enhance medical image segmentation, a crucial task for accurate diagnostic imaging. This study explores enhancing Vision Transformers (ViTs) for medical image segmentation by integrating pre-trained LLM transformer blocks. Our approach, which incorporates a frozen LLM transformer block into the encoder of a ViT-based model, leads to substantial improvements in segmentation performance across various medical imaging modalities. We propose a Hybrid Attention Mechanism that combines global and local feature learning with a Multi-Scale Fusion Block for aggregating features across different scales. The enhanced model shows significant performance gains, including an average Dice score increase from 0.74 to 0.79 and improvements in accuracy, precision, and the Jaccard Index. These results demonstrate the effectiveness of LLM-based transformers in refining medical image segmentation, highlighting their potential to significantly boost model accuracy and robustness. The source code and our implementation are available at: https://github.com/AS-Lab/Marthi-et-al-2025-MedVisionLlama-Pre-Trained-LLM-Layers-to-Enhance-Medical-Image-Segmentation