LLM-Pilot: Characterize and Optimize Performance of your LLM Inference Services
作者: Małgorzata Łazuka, Andreea Anghel, Thomas Parnell
分类: cs.DC, cs.CL, cs.LG
发布日期: 2024-10-03
备注: Accepted to the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '24)
💡 一句话要点
LLM-Pilot:表征并优化LLM推理服务的性能,实现硬件高效选择。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM推理 性能优化 硬件选择 基准测试 成本效益 预测模型
📋 核心要点
- 现有LLM推理服务在选择硬件时面临挑战,难以在性能和成本之间取得平衡,缺乏有效的性能预测和优化工具。
- LLM-Pilot通过基准测试、服务配置优化和预测模型学习,为LLM推理服务选择最具成本效益的硬件。
- 实验结果表明,LLM-Pilot比现有方法更频繁地满足性能要求(提高33%),同时平均降低成本60%。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速普及,LLM推理服务必须能够服务于数千用户的请求,同时满足性能要求。LLM推理服务的性能很大程度上取决于部署的硬件,但了解哪种硬件能够满足性能需求仍然具有挑战性。本文提出了LLM-Pilot,这是一个首创的系统,用于表征和预测LLM推理服务的性能。LLM-Pilot在各种GPU上,在实际工作负载下,对LLM推理服务进行基准测试,并优化每个考虑的GPU的服务配置,以最大限度地提高性能。最后,利用这些表征数据,LLM-Pilot学习一个预测模型,该模型可用于为先前未见过的LLM推荐最具成本效益的硬件。与现有方法相比,LLM-Pilot能够更频繁地满足性能要求(提高33%),同时平均降低成本60%。
🔬 方法详解
问题定义:论文旨在解决LLM推理服务中硬件选择的难题。现有方法难以准确预测不同硬件上的LLM性能,导致硬件资源利用率低,成本高昂。缺乏一个系统化的方法来表征LLM在不同硬件上的性能,并根据性能要求推荐最具成本效益的硬件。
核心思路:LLM-Pilot的核心思路是通过对LLM推理服务进行全面的基准测试,建立LLM性能与硬件之间的关联模型。通过优化服务配置,最大化每个硬件上的性能。然后,利用这些数据训练一个预测模型,该模型可以根据LLM的特性和性能要求,推荐最佳的硬件配置。这种方法旨在实现性能和成本之间的最佳平衡。
技术框架:LLM-Pilot包含三个主要模块:1) 基准测试模块:在各种GPU上,使用真实的工作负载对LLM推理服务进行基准测试,收集性能数据。2) 优化模块:针对每个GPU,优化LLM推理服务的配置,例如批处理大小、并行度等,以最大化性能。3) 预测模块:使用基准测试和优化后的数据,训练一个预测模型,该模型可以根据LLM的特性和性能要求,推荐最具成本效益的硬件。
关键创新:LLM-Pilot的关键创新在于它是一个端到端的系统,能够自动地表征LLM推理服务的性能,优化服务配置,并预测硬件选择。与现有方法相比,LLM-Pilot更加系统化和自动化,能够更准确地预测LLM在不同硬件上的性能,并推荐最具成本效益的硬件。它将基准测试、优化和预测结合在一起,形成一个完整的解决方案。
关键设计:LLM-Pilot的关键设计包括:1) 使用真实的工作负载进行基准测试,以确保结果的可靠性。2) 针对每个GPU进行服务配置优化,以最大化性能。3) 使用机器学习模型进行性能预测,以实现硬件的智能选择。具体的参数设置、损失函数和网络结构等技术细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片
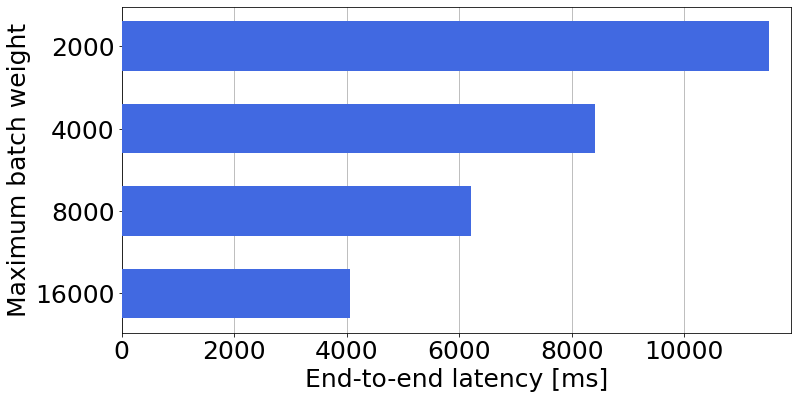
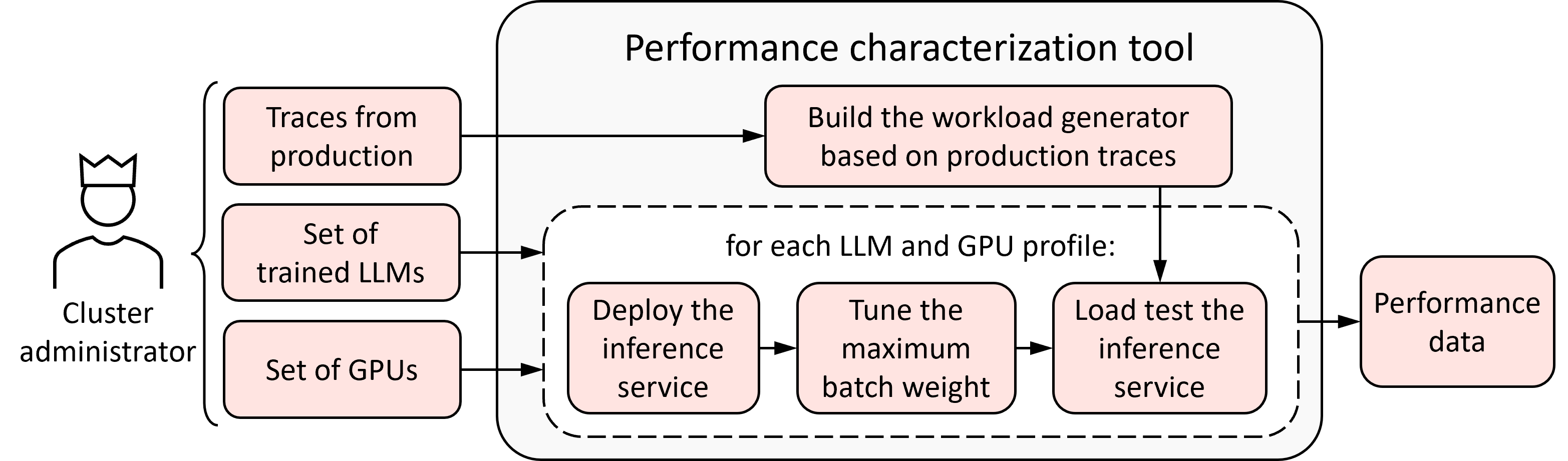
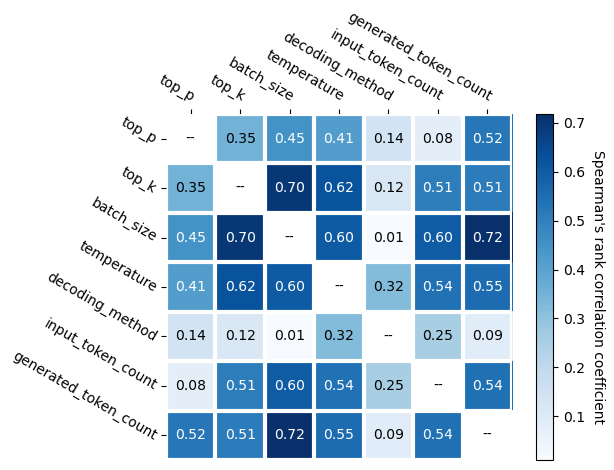
📊 实验亮点
LLM-Pilot在实验中表现出色,与现有方法相比,能够更频繁地满足性能要求(提高33%),同时平均降低成本60%。这些结果表明,LLM-Pilot能够有效地表征和优化LLM推理服务的性能,并为硬件选择提供有价值的指导。
🎯 应用场景
LLM-Pilot可应用于各种需要部署LLM推理服务的场景,例如在线问答、文本生成、机器翻译等。它可以帮助用户选择最具成本效益的硬件,降低部署成本,提高服务性能。该研究的成果有助于推动LLM在各个领域的广泛应用,并促进LLM推理服务的优化和发展。
📄 摘要(原文)
As Large Language Models (LLMs) are rapidly growing in popularity, LLM inference services must be able to serve requests from thousands of users while satisfying performance requirements. The performance of an LLM inference service is largely determined by the hardware onto which it is deployed, but understanding of which hardware will deliver on performance requirements remains challenging. In this work we present LLM-Pilot - a first-of-its-kind system for characterizing and predicting performance of LLM inference services. LLM-Pilot performs benchmarking of LLM inference services, under a realistic workload, across a variety of GPUs, and optimizes the service configuration for each considered GPU to maximize performance. Finally, using this characterization data, LLM-Pilot learns a predictive model, which can be used to recommend the most cost-effective hardware for a previously unseen LLM. Compared to existing methods, LLM-Pilot can deliver on performance requirements 33% more frequently, whilst reducing costs by 60% on average.