ERASMO: Leveraging Large Language Models for Enhanced Clustering Segmentation
作者: Fillipe dos Santos Silva, Gabriel Kenzo Kakimoto, Julio Cesar dos Reis, Marcelo S. Reis
分类: cs.CL, cs.AI
发布日期: 2024-10-01 (更新: 2025-02-04)
备注: 15 pages, 10 figures, published in BRACIS 2024 conference
💡 一句话要点
ERASMO:利用大型语言模型增强聚类分割,处理多模态表格数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 聚类分析 表格数据 语言模型 多模态学习 嵌入表示
📋 核心要点
- 传统聚类方法难以有效处理包含表格和文本的多模态数据,无法充分挖掘隐藏的复杂关系模式。
- ERASMO框架通过将表格数据转换为文本,利用预训练语言模型学习数据间的上下文关系,生成高质量的嵌入表示。
- 实验结果表明,ERASMO能够有效提升聚类性能,通过捕获复杂关系模式,生成更精确和细致的嵌入。
📝 摘要(中文)
本研究提出了ERASMO框架,旨在通过微调预训练语言模型来增强聚类分割效果,尤其针对包含表格和文本数据的多模态数据。ERASMO首先使用文本转换器将表格数据转换为文本格式,使语言模型能够更有效地处理和理解数据。然后,通过随机特征序列洗牌和数字文本化等技术,生成具有上下文丰富性和结构代表性的嵌入。通过多个数据集和基线方法的广泛实验评估表明,ERASMO能够充分利用每个表格数据集的特定上下文,从而生成更精确和细致的嵌入,实现更准确的聚类。该方法通过捕获各种表格数据中复杂的关系模式,显著提高了聚类性能。
🔬 方法详解
问题定义:论文旨在解决在多模态数据(特别是表格数据和文本数据结合)的聚类分析中,传统方法难以有效提取隐藏模式和复杂关系的问题。现有方法通常无法充分利用表格数据的上下文信息,导致聚类效果不佳。
核心思路:论文的核心思路是将表格数据转换为文本形式,然后利用预训练的语言模型来学习这些文本化的表格数据的嵌入表示。通过这种方式,语言模型可以利用其强大的上下文理解能力,捕捉表格数据中复杂的语义关系,从而生成更具代表性的嵌入,进而提升聚类性能。
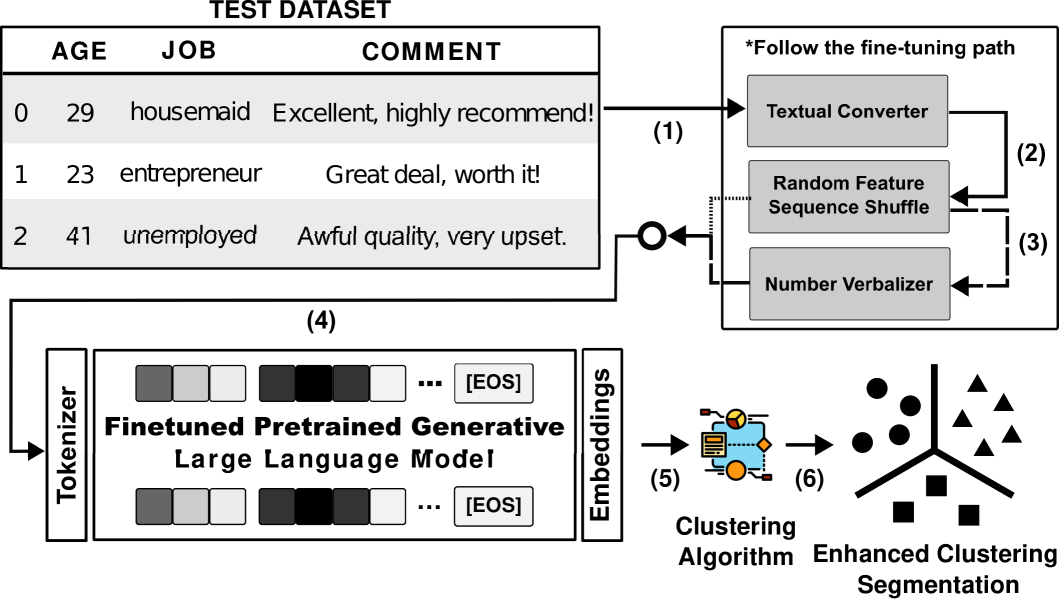
技术框架:ERASMO框架主要包含以下几个阶段:1) 文本转换器:将表格数据转换为文本格式。2) 预训练语言模型微调:在转换后的文本数据上微调预训练的语言模型。3) 嵌入生成:使用微调后的语言模型生成表格数据的嵌入表示。4) 聚类:使用生成的嵌入进行聚类分析。框架通过文本转换和语言模型微调,实现了表格数据上下文信息的有效利用。
关键创新:ERASMO的关键创新在于将表格数据聚类问题转化为自然语言处理问题,并利用预训练语言模型的强大能力来解决。此外,论文还提出了随机特征序列洗牌和数字文本化等技术,进一步增强了嵌入的上下文丰富性和结构代表性。与传统方法相比,ERASMO能够更好地捕捉表格数据中的复杂关系模式。
关键设计:ERASMO使用了文本转换器将表格数据转换为文本,具体转换方式未知。在语言模型微调阶段,使用了交叉熵损失函数。随机特征序列洗牌通过随机打乱表格数据的列顺序来增强模型的鲁棒性。数字文本化将数值数据转换为文本描述,例如将“123”转换为“one hundred and twenty-three”。具体使用的预训练语言模型类型和微调参数未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ERASMO在多个数据集上显著优于现有的聚类方法。具体性能提升数据未知,但摘要强调了ERASMO能够充分利用每个表格数据集的特定上下文,从而生成更精确和细致的嵌入,实现更准确的聚类。该方法通过捕获各种表格数据中复杂的关系模式,显著提高了聚类性能。
🎯 应用场景
ERASMO框架可广泛应用于客户细分、金融风险评估、医疗诊断等领域。通过更精确的聚类分析,可以帮助企业更好地了解客户需求,提高营销效率;辅助金融机构识别潜在风险,降低信贷损失;支持医生进行更准确的疾病诊断,制定个性化治疗方案。未来,该方法有望应用于更多涉及表格数据的分析场景,提升决策效率和准确性。
📄 摘要(原文)
Cluster analysis plays a crucial role in various domains and applications, such as customer segmentation in marketing. These contexts often involve multimodal data, including both tabular and textual datasets, making it challenging to represent hidden patterns for obtaining meaningful clusters. This study introduces ERASMO, a framework designed to fine-tune a pretrained language model on textually encoded tabular data and generate embeddings from the fine-tuned model. ERASMO employs a textual converter to transform tabular data into a textual format, enabling the language model to process and understand the data more effectively. Additionally, ERASMO produces contextually rich and structurally representative embeddings through techniques such as random feature sequence shuffling and number verbalization. Extensive experimental evaluations were conducted using multiple datasets and baseline approaches. Our results demonstrate that ERASMO fully leverages the specific context of each tabular dataset, leading to more precise and nuanced embeddings for accurate clustering. This approach enhances clustering performance by capturing complex relationship patterns within diverse tabular data.