FedPT: Federated Proxy-Tuning of Large Language Models on Resource-Constrained Edge Devices
作者: Zhidong Gao, Yu Zhang, Zhenxiao Zhang, Yanmin Gong, Yuanxiong Guo
分类: cs.CL, cs.AI
发布日期: 2024-10-01
备注: 29 pages, 19 figures
💡 一句话要点
FedPT:面向资源受限边缘设备的联邦代理调优大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大语言模型 代理调优 知识蒸馏 边缘计算 隐私保护 模型压缩
📋 核心要点
- 现有大语言模型联邦微调方法面临参数访问限制、计算开销大、通信成本高等挑战。
- FedPT通过联邦学习协同训练小模型,再将小模型知识迁移到大模型,实现高效的代理调优。
- 实验表明,FedPT在降低计算、通信和内存开销的同时,保持了与直接联邦微调相当的性能。
📝 摘要(中文)
预训练大语言模型(LMs)在各种语言任务中表现出色,但通常需要在特定数据集上进行微调,以有效解决不同的下游任务。然而,微调这些LMs需要收集个人数据,这引发了严重的隐私问题。联邦学习(FL)已成为事实上的解决方案,可以在不共享原始数据的情况下实现协作模型训练。然而,大型LMs的联邦微调面临着诸多挑战,包括模型参数访问受限以及高昂的计算、通信和内存开销。为了解决这些挑战,本文提出了一种新颖的框架——联邦代理调优(FedPT),用于黑盒大LMs的联邦微调,只需要访问它们在输出词汇表上的预测,而不需要访问它们的参数。具体来说,FedPT中的设备首先协同调优一个较小的LM,然后服务器将调优后的小LM学习到的知识与较大的预训练LM学习到的知识相结合,构建一个大型代理调优LM,该LM可以达到直接调优大型LMs的性能。实验结果表明,与直接联邦微调大型LMs相比,FedPT可以显著降低计算、通信和内存开销,同时保持具有竞争力的性能。FedPT为在资源受限设备上高效、保护隐私地微调大型LMs提供了一个有希望的解决方案,从而扩大了最先进的大型LMs的可访问性和适用性。
🔬 方法详解
问题定义:论文旨在解决在资源受限的边缘设备上,对黑盒大语言模型进行联邦微调时面临的计算、通信和内存开销过大的问题。现有方法通常需要直接访问和更新大模型的参数,这在联邦学习场景下是不可行的,因为边缘设备算力有限,且直接传输大模型参数会带来巨大的通信开销。
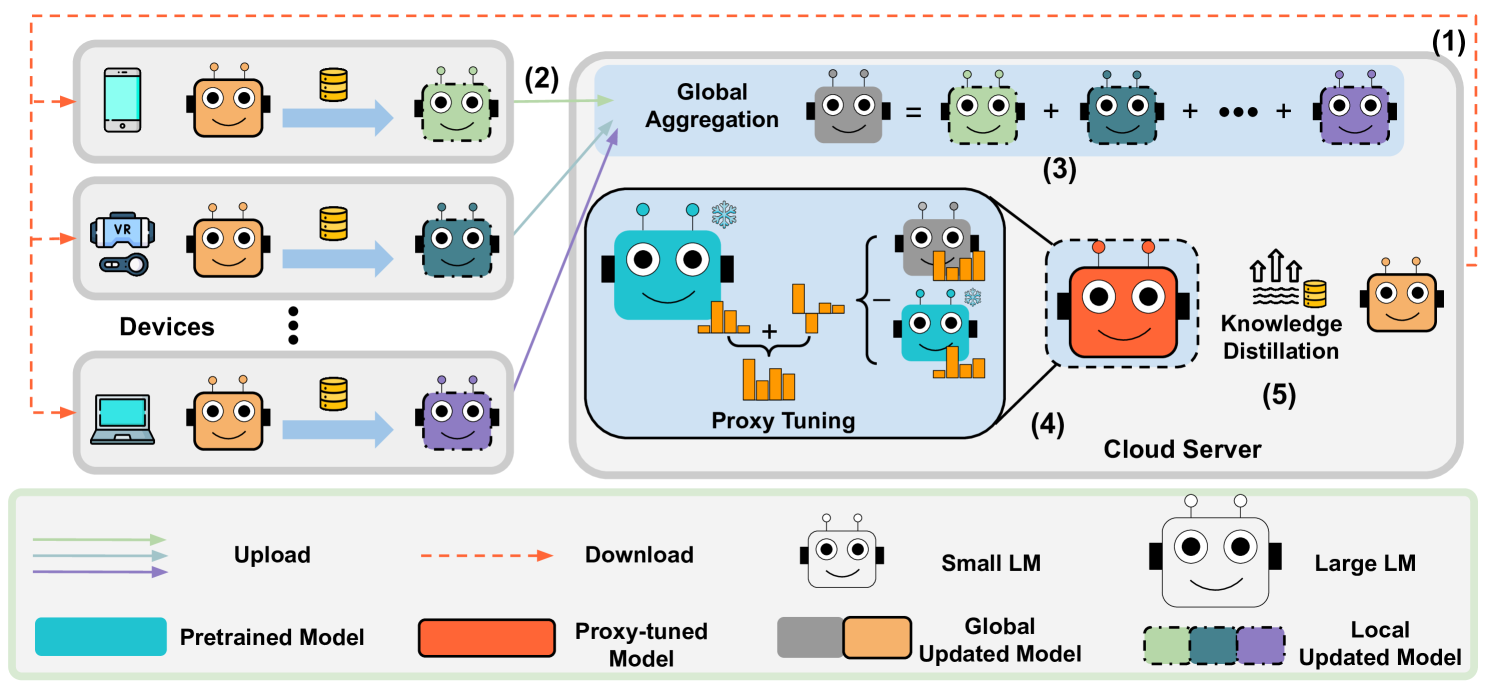
核心思路:FedPT的核心思路是采用代理调优的方式,即不直接微调大模型,而是先在边缘设备上联邦学习训练一个小模型,然后利用小模型的知识来指导大模型的调优。这样可以显著降低边缘设备的计算负担和通信开销,同时保护用户数据的隐私。
技术框架:FedPT的整体框架包含以下几个主要阶段: 1. 本地小模型训练:每个边缘设备使用本地数据训练一个小型的语言模型。 2. 联邦聚合:服务器收集来自各个边缘设备的小模型更新,并进行聚合,得到一个全局的小模型。 3. 代理模型构建:服务器利用全局小模型的知识,结合预训练的大语言模型,构建一个代理模型。具体来说,服务器使用小模型的预测结果作为监督信号,来训练大模型,使其能够模仿小模型的行为。 4. 模型部署:将代理模型部署到边缘设备或服务器上,用于下游任务。
关键创新:FedPT的关键创新在于提出了联邦代理调优的概念,将联邦学习和小模型蒸馏相结合,实现了在资源受限设备上对大语言模型进行高效微调。与直接联邦微调大模型相比,FedPT只需要传输小模型的参数,大大降低了通信开销。与传统的知识蒸馏方法相比,FedPT采用联邦学习的方式,保护了用户数据的隐私。
关键设计:FedPT的关键设计包括: 1. 小模型选择:选择一个与大模型结构相似,但参数量较小的模型作为小模型。 2. 损失函数设计:使用交叉熵损失函数来训练小模型,并使用KL散度损失函数来训练大模型,使其能够模仿小模型的预测分布。 3. 联邦聚合策略:采用FedAvg算法进行联邦聚合,即对各个边缘设备的小模型参数进行加权平均。
🖼️ 关键图片
📊 实验亮点
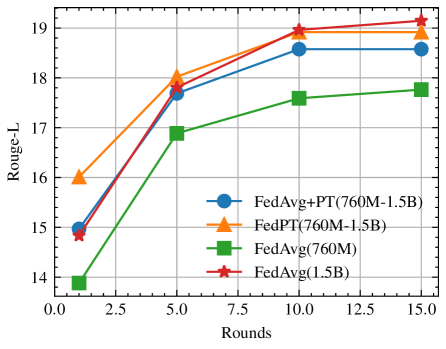
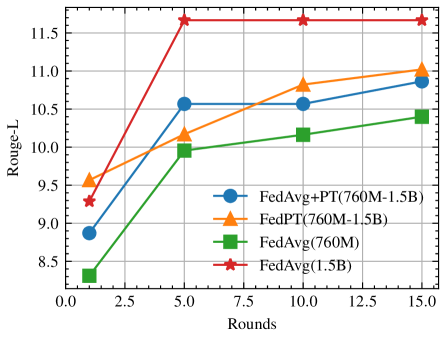
实验结果表明,FedPT在保持与直接联邦微调大语言模型相当的性能的同时,显著降低了计算、通信和内存开销。具体来说,FedPT可以将通信开销降低到原来的1/10,计算开销降低到原来的1/5,内存开销降低到原来的1/3。这些结果表明,FedPT是一种高效、实用的联邦学习方法,可以有效地解决在资源受限设备上微调大语言模型的问题。
🎯 应用场景
FedPT适用于各种需要在资源受限的边缘设备上进行大语言模型微调的场景,例如智能手机上的自然语言处理应用、物联网设备上的语音识别和文本生成等。该方法可以降低计算和通信开销,提高模型训练效率,同时保护用户数据的隐私,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Despite demonstrating superior performance across a variety of linguistic tasks, pre-trained large language models (LMs) often require fine-tuning on specific datasets to effectively address different downstream tasks. However, fine-tuning these LMs for downstream tasks necessitates collecting data from individuals, which raises significant privacy concerns. Federated learning (FL) has emerged as the de facto solution, enabling collaborative model training without sharing raw data. While promising, federated fine-tuning of large LMs faces significant challenges, including restricted access to model parameters and high computation, communication, and memory overhead. To address these challenges, this paper introduces \textbf{Fed}erated \textbf{P}roxy-\textbf{T}uning (FedPT), a novel framework for federated fine-tuning of black-box large LMs, requiring access only to their predictions over the output vocabulary instead of their parameters. Specifically, devices in FedPT first collaboratively tune a smaller LM, and then the server combines the knowledge learned by the tuned small LM with the knowledge learned by the larger pre-trained LM to construct a large proxy-tuned LM that can reach the performance of directly tuned large LMs. The experimental results demonstrate that FedPT can significantly reduce computation, communication, and memory overhead while maintaining competitive performance compared to directly federated fine-tuning of large LMs. FedPT offers a promising solution for efficient, privacy-preserving fine-tuning of large LMs on resource-constrained devices, broadening the accessibility and applicability of state-of-the-art large LMs.